
Microsoft découvre une faille de sécurité dans les chatbots IA qui pourrait exposer des sujets de conversation
Vos conversations avec des assistants IA tels que ChatGPT et Google Gemini ne sont peut-être pas aussi privées que vous le pensez. Microsoft a révélé une grave faille dans les grands modèles de langage (LLM) qui alimentent ces services d'IA, exposant potentiellement le sujet de vos conversations avec eux. Les chercheurs ont surnommé la vulnérabilité « Whisper Leak » et ont découvert qu’elle affectait presque tous les modèles testés.
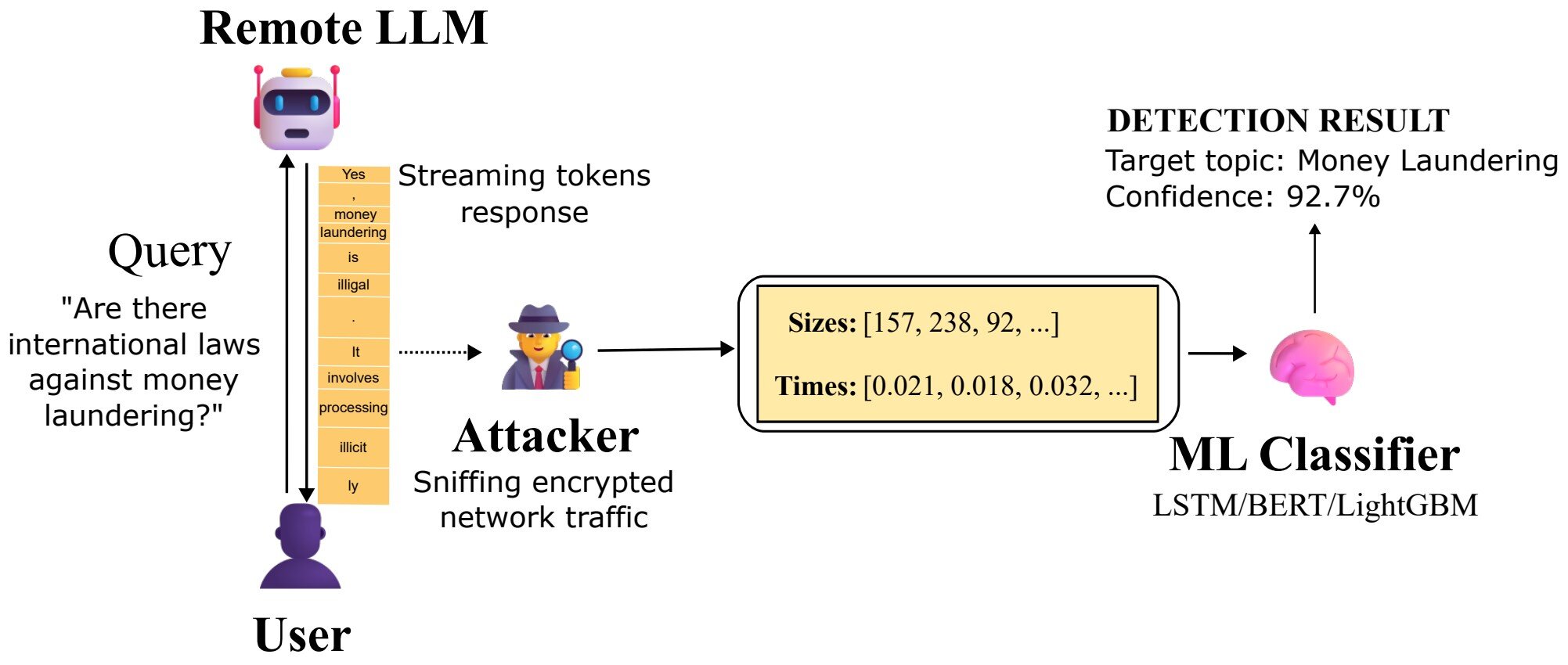
Lorsque vous discutez avec des assistants IA intégrés aux principaux moteurs de recherche ou applications, les informations sont protégées par TLS (Transport Layer Security), le même cryptage que celui utilisé pour les services bancaires en ligne. Ces connexions sécurisées empêchent les oreilles indiscrètes de lire les mots que vous tapez. Cependant, Microsoft a découvert que les métadonnées (la façon dont vos messages circulent sur Internet) restent visibles. Whisper Leak ne brise pas le cryptage, mais il profite de ce que le cryptage ne peut pas cacher.
Tester les LLM
Dans une recherche publiée sur le arXiv serveur de préimpression, les chercheurs de Microsoft expliquent comment ils ont testé 28 LLM pour rechercher cette vulnérabilité. Premièrement, ils ont créé deux séries de questions. L’une regroupait de nombreuses façons de poser des questions sur un sujet unique et sensible, comme le blanchiment d’argent, et l’autre était remplie de milliers de requêtes aléatoires et quotidiennes. Ensuite, ils ont secrètement enregistré le rythme des données de chaque réseau. Il s'agit de la taille du paquet (morceaux de données envoyés) et du timing (le délai entre l'envoi d'un paquet et l'arrivée de l'autre).
Ensuite, ils ont formé un programme d’IA pour distinguer les sujets cibles sensibles des requêtes quotidiennes uniquement sur la base du rythme des données. Si l’IA parvenait à identifier les sujets sensibles sans lire le texte crypté, cela confirmerait un problème de confidentialité.
Dans la plupart des modèles, l’IA a correctement deviné le sujet de la conversation avec une précision de plus de 98 %. L’attaque pourrait également identifier les conversations sensibles 100 % du temps, même si elles n’ont lieu que dans 1 conversation sur 10 000. Les chercheurs ont testé trois manières différentes de se défendre contre les attaques, mais aucune ne les a complètement arrêtées.
Arrêter la fuite
Selon l’équipe, le problème ne vient pas du cryptage lui-même, mais de la manière dont les réponses sont transmises. « Il ne s'agit pas d'une vulnérabilité cryptographique dans TLS lui-même, mais plutôt d'une exploitation de métadonnées que TLS révèle intrinsèquement sur la structure et le timing du trafic chiffré. »
Compte tenu de la gravité de la fuite et de la facilité avec laquelle l’attaque peut être exécutée, les chercheurs affirment clairement dans leur article que l’industrie doit sécuriser les futurs systèmes. « Nos résultats soulignent la nécessité pour les fournisseurs de LLM de remédier aux fuites de métadonnées à mesure que les systèmes d'IA gèrent des informations de plus en plus sensibles. »
Écrit pour vous par notre auteur Paul Arnold, édité par Gaby Clark, et vérifié et révisé par Robert Egan, cet article est le résultat d'un travail humain minutieux. Nous comptons sur des lecteurs comme vous pour maintenir en vie le journalisme scientifique indépendant. Si ce reporting vous intéresse, pensez à faire un don (surtout mensuel). Vous obtiendrez un sans publicité compte en guise de remerciement.