

Maia 200 Microsoft, l'accélérateur d'IA change les règles d'inférence dans le cloud
Microsoft a annoncé Maia 200, le nouvel accélérateur d'inférence qui représente une étape clé dans la stratégie de bout en bout de l'entreprise en matière d'intelligence artificielle. Conçu pour modifier fondamentalement l’économie de l’IA à grande échelle, Maia 200 vise à rendre l’exécution des modèles plus rapide et plus viable économiquement au sein des centres de données Azure.
Performances et coûts optimisés
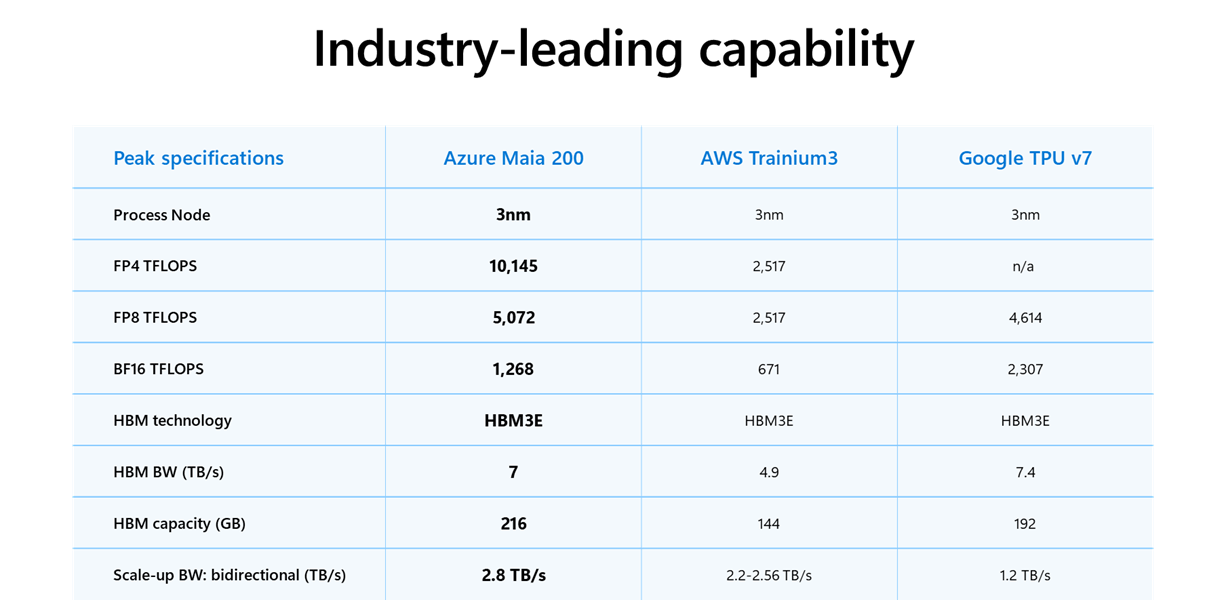
Construit à l'aide du processus de fabrication de 3 nanomètres de TSMC, Maia 200 intègre des cœurs tenseurs natifs FP8 et FP4, un système de mémoire repensé avec 216 Go de HBM3e à 7 To/s et 272 Mo de SRAM sur puce. Selon Microsoft, la puce offre trois fois les performances FP4 du Trainium de troisième génération d'Amazon et surpasse le TPU de septième génération de Google en FP8, offrant une amélioration de 30 % du rapport performances/prix par rapport aux solutions précédentes.
Conçu spécifiquement pour l'inférence de l'IA
Chaque puce dépasse 100 milliards de transistors et est optimisée pour le calcul de basse précision, avec plus de 10 pétaFLOPS dans FP4 et environ 5 pétaFLOPS dans FP8. Cela permet à un seul nœud Maia 200 d’exécuter les plus grands modèles d’IA disponibles aujourd’hui, laissant ainsi une marge aux générations futures. L'architecture réduit également les goulots d'étranglement lors du transfert de données en conservant localement les pondérations et les informations critiques.
Mémoire et données au centre de l'architecture
Microsoft s'est concentré sur un sous-système de mémoire conçu autour de formats de faible précision, de moteurs DMA dédiés, de SRAM sur puce et d'un réseau interne à large bande passante. L'objectif est de réduire le nombre d'appareils nécessaires à l'exécution d'un modèle, améliorant ainsi l'efficacité et l'utilisation des ressources dans les centres de données.

Réseau unifié et évolutivité du cloud
Au niveau du système, Maia 200 introduit une architecture évolutive à deux niveaux basée sur l'Ethernet standard. Chaque accélérateur offre 1,4 To/s de bande passante dédiée et prend en charge des opérations collectives prévisibles sur des clusters comprenant jusqu'à 6 144 accélérateurs. Le réseau unifié, du nœud unique au cluster mondial, simplifie la programmation et réduit les coûts énergétiques et le coût total de possession pour Azure.
Développement agile et mise sur le marché accélérée
Le projet Maia 200 est né d'une approche qui privilégie la simulation et l'émulation dès les premières étapes. Microsoft a validé le matériel, la mise en réseau et les logiciels bien avant l'arrivée du premier silicium physique, réduisant ainsi considérablement les temps de déploiement dans les centres de données. Les premiers modèles d'IA ont commencé à fonctionner sur Maia 200 quelques jours après l'arrivée des puces, réduisant de moitié le temps par rapport à des programmes comparables.
Des laboratoires aux produits Microsoft
La première utilisation de Maia 200 sera confiée à l'équipe Microsoft Superintelligence pour la génération de données synthétiques et l'apprentissage par renforcement. L'accélérateur sera ensuite déployé dans Microsoft Foundry et Microsoft 365 Copilot, devenant ainsi une partie de l'infrastructure mondiale d'IA hétérogène de l'entreprise, avec une disponibilité future également étendue aux clients.

L'avenir du programme Maia
Maia 200 n'est que le début d'un programme conçu pour être multigénérationnel. Microsoft travaille déjà sur les prochaines évolutions, dans le but d'établir de nouveaux standards en termes de performances et d'efficacité.
En parallèle, la société a ouvert la préversion du SDK Maia, invitant les développeurs, les chercheurs et les communautés open source à commencer à optimiser les modèles sur la nouvelle plateforme.