

LLM 2030 : une inférence plus efficace et des coûts jusqu'à 90 % inférieurs
Selon les prévisions de Gartner, d’ici 2030, exécuter des inférences sur un grand modèle de langage (LLM) avec mille milliards de paramètres coûtera plus de 90 % de moins qu’en 2025. Un changement radical qui promet de redéfinir l’économie de l’intelligence artificielle générative.
Les jetons, unités de traitement fondamentales pour les modèles GenAI – équivalents à environ 3,5 octets ou 4 caractères – deviendront progressivement moins chers, réduisant considérablement les coûts opérationnels pour les fournisseurs.
Les leviers technologiques derrière la révolution
Plusieurs facteurs sont à l’origine de ce déclin : améliorations de l’efficacité des semi-conducteurs, infrastructures plus avancées, innovations dans la conception des modèles et utilisation plus intensive des puces.
Comme l'explique Will Sommer, analyste directeur principal chez Gartner, les puces spécialisées pour l'inférence et l'adoption croissante de dispositifs de pointe pour des cas d'utilisation spécifiques joueront également un rôle clé.
Des modèles plus performants : jusqu’à 100 fois meilleurs
L’évolution ne concerne pas seulement les coûts absolus, mais aussi l’efficacité. Toujours selon Gartner, d’ici 2030, les LLM seront jusqu’à 100 fois plus efficaces que les premiers modèles de taille similaire développés en 2022.
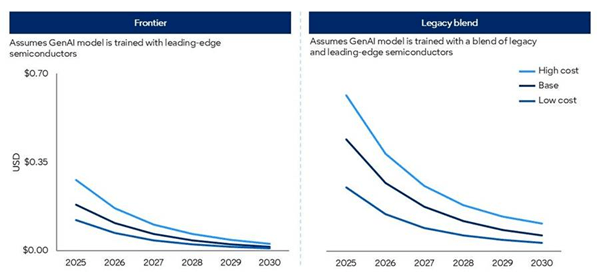
Les prévisions reposent sur deux scénarios distincts :
- Frontier : basé sur des puces de dernière génération
- Mélange hérité : basé sur un mélange représentatif de semi-conducteurs disponibles
Dans le second cas, les coûts sont nettement plus élevés en raison de la moindre puissance de calcul.
Le paradoxe des coûts : moins par jeton, plus au total
Malgré la baisse des coûts unitaires, les entreprises ne verront pas nécessairement leurs factures allégées. En fait, les fournisseurs de GenAI ne répercutent peut-être pas entièrement les économies réalisées sur les entreprises clientes.
De plus, les modèles plus avancés nécessiteront beaucoup plus de jetons pour fonctionner. Les modèles agentiques, par exemple, consomment 5 à 30 fois plus de tokens par tâche que les chatbots traditionnels, bien qu’ils soient capables d’effectuer des tâches beaucoup plus complexes.
Le résultat ? Même si chaque jeton coûte moins cher, la consommation globale augmente plus rapidement, augmentant ainsi le coût total de l’inférence.
Parce que l’IA avancée ne sera pas vraiment démocratique
« Réduire le coût des jetons n'est pas la même chose que démocratiser l'intelligence avancée », prévient Sommer.
Alors que le renseignement «marchandises » tend vers des coûts quasi nuls, les ressources nécessaires au raisonnement avancé – infrastructures, puissance de calcul et systèmes complexes – restent limitées et coûteuses.
Cela signifie que l’accès aux capacités les plus sophistiquées de l’IA pourrait rester concentré entre les mains de quelques grands acteurs.
La stratégie gagnante : orchestrer différents modèles
Selon Gartner, la valeur va se déplacer vers des plateformes capables d’orchestrer intelligemment différents modèles.
Les activités répétitives et à haute fréquence devront être confiées à des modèles plus petits et spécialisés, souvent plus efficaces et économiques que les modèles généralistes.
Au contraire, les modèles frontières – plus chers – devront être réservés à des tâches complexes à forte valeur ajoutée.
Vers un nouvel équilibre de l’IA
L’avenir de GenAI ne sera pas défini uniquement par le coût des jetons, mais aussi par la capacité à équilibrer efficacité, complexité et valeur.
Le défi pour les entreprises ne sera pas simplement de dépenser moins, mais de dépenser mieux : en choisissant quand utiliser l’intelligence la plus puissante et quand, à la place, se concentrer sur des solutions plus simples et plus durables.