
L'interruption de l'entraînement du codeur dans les modèles de diffusion permet une AI générative plus efficace
Un nouveau cadre pour les modèles de diffusion génératifs a été développé par des chercheurs de Science Tokyo, améliorant considérablement les modèles d'IA génératifs. La méthode a réinterprété les modèles de pont Schrödinger en tant qu'autoencodeurs variationnels avec infiniment de nombreuses variables latentes, réduisant les coûts de calcul et empêchant le sur-ajustement. En interrompant de manière appropriée la formation de l'encodeur, cette approche a permis le développement d'une IA générative plus efficace, avec une large applicabilité au-delà des modèles de diffusion standard.
Les modèles de diffusion sont parmi les approches les plus utilisées dans l'IA générative pour créer des images et l'audio. Ces modèles génèrent de nouvelles données en ajoutant progressivement du bruit (nuls) à des échantillons réels, puis en apprenant à inverser ce processus (déniisation) dans des données réalistes. Une version largement utilisée, le modèle basé sur les scores, y parvient par le processus de diffusion reliant les données antérieures à un intervalle suffisamment de longue date. Cette méthode, cependant, a une limitation que lorsque les données diffèrent fortement de la précédente, les intervalles de temps des processus de noing et de débarras deviennent plus longs, ce qui provoque un ralentissement de la génération d'échantillons.
Maintenant, une équipe de recherche de l'Institute of Science Tokyo (Science Tokyo), au Japon, a proposé un nouveau cadre pour les modèles de diffusion qui est plus rapide et moins exigeant. Ils l'ont atteint en réinterprétant les modèles de pont de Schrödinger (SB), un type de modèle de diffusion, en tant qu'autoencodeurs variationnels (VAE).
L'étude a été menée par l'étudiant diplômé M. Kentaro Kaba et le professeur Masayuki Ohzeki du Département de physique de Science Tokyo, en collaboration avec M. Reo Shimizu (alors étudiant diplômé) et professeur agrégé Yuki Sugiyama de la Graduate School of Information Sciences de l'Université Tohoku, au Japon. Leurs résultats ont été publiés dans le Recherche d'examen physique le 3 septembre 2025.
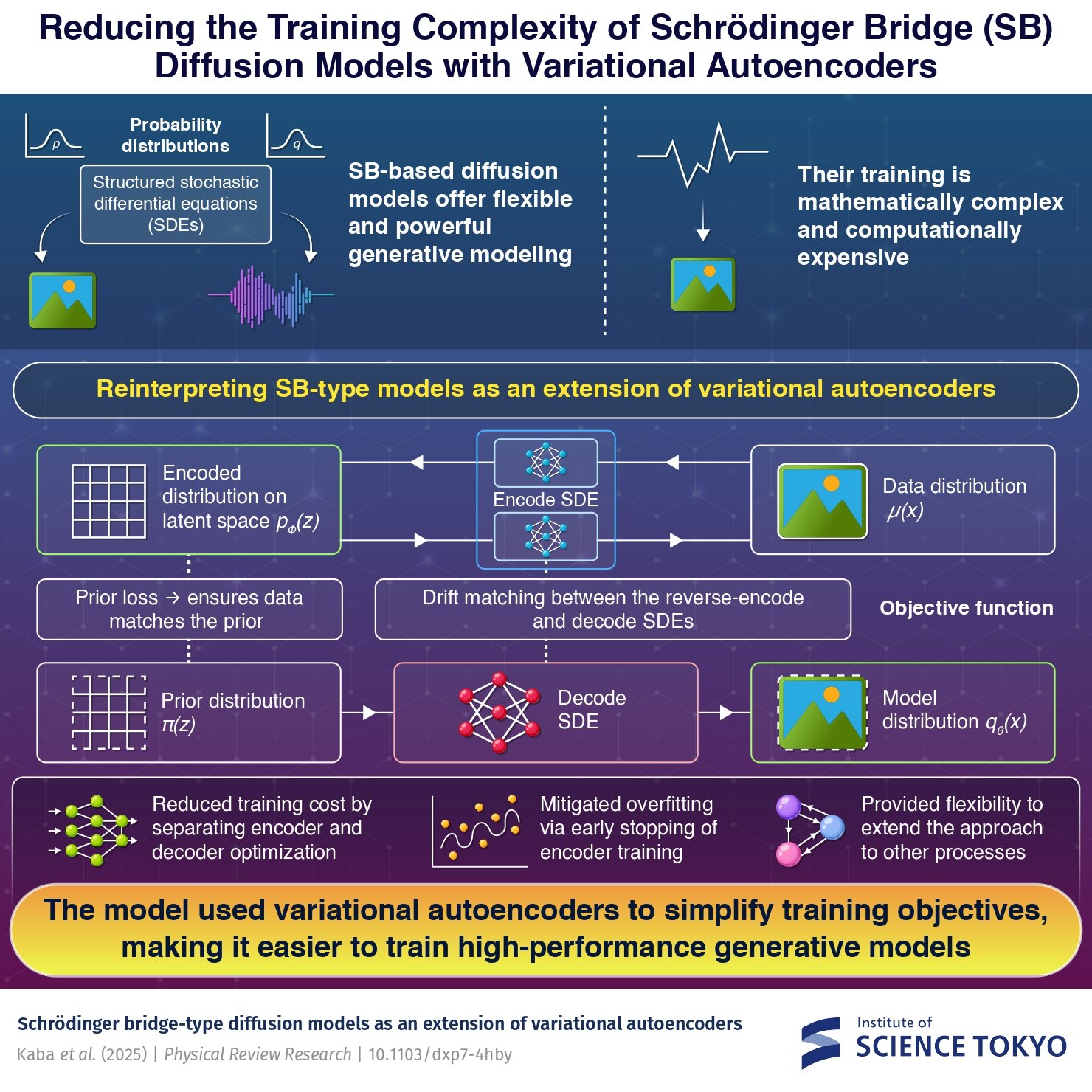
Les modèles SB offrent une plus grande flexibilité que les modèles basés sur les scores standard car ils peuvent connecter deux distributions de probabilité sur un temps fini en utilisant une équation différentielle stochastique (SDE). Cela prend en charge des processus de n ° de n ° et une génération d'échantillons de meilleure qualité. Le compromis, cependant, est que les modèles SB sont mathématiquement complexes et coûteux à former.
La méthode proposée aborde cela en reformulant les modèles SB en tant que VAE avec plusieurs variables latentes. « L'informatique clé réside dans l'extension du nombre de variables latentes de une à l'infini, tirant parti de l'inégalité de traitement des données. Cette perspective nous permet d'interpréter les modèles de type SB dans le cadre des VAE », explique Kaba.
Dans cette configuration, le codeur représente le processus avant qui mappe les données réelles sur un espace latent bruyant, tandis que le décodeur inverse le processus pour reconstruire des échantillons réalistes, et les deux processus sont modélisés comme SDE appris par les réseaux de neurones.
Le modèle utilise un objectif de formation avec deux composantes. Le premier est la perte antérieure, qui garantit que l'encodeur mappe correctement la distribution des données à la distribution antérieure. Le second est la correspondance de dérive, qui forme le décodeur à imiter la dynamique du processus d'encodeur inversé. De plus, une fois que la perte antérieure s'est stabilisée, la formation en coder peut être arrêtée tôt. Cela nous permet de terminer l'apprentissage plus rapidement, en réduisant le risque de sur-ajustement et de préserver une grande précision dans les modèles SB.
« La fonction objectif est composée des pièces de correspondance antérieures de perte et de dérive, qui caractérise respectivement la formation des réseaux de neurones dans l'encodeur et le décodeur. Ensemble, ils réduisent le coût de calcul de la formation des modèles de type SB. Il a été démontré que l'interruption de la formation de l'encodeur a attiré le défi de la surfiance », explique Ohzeki.
Cette approche est flexible et peut être appliquée à d'autres ensembles de règles probabilistes, même les processus non-Markov, ce qui en fait un schéma de formation largement applicable.