
L'IA apprend comment la vision et le son sont connectés, sans intervention humaine
Les humains apprennent naturellement en établissant des liens entre la vue et le son. Par exemple, nous pouvons regarder quelqu'un jouer du violoncelle et reconnaître que les mouvements de la violoncelliste génèrent la musique que nous entendons.
Une nouvelle approche développée par des chercheurs du MIT et ailleurs améliore la capacité d'un modèle d'IA à apprendre de cette même manière. Cela pourrait être utile dans des applications telles que le journalisme et la production cinématographique, où le modèle pourrait aider à la conservation du contenu multimodal grâce à la récupération automatique et à la récupération audio.
À plus long terme, ce travail pourrait être utilisé pour améliorer la capacité d'un robot à comprendre les environnements du monde réel, où les informations auditives et visuelles sont souvent étroitement connectées.
Améliorant les travaux antérieurs de leur groupe, les chercheurs ont créé une méthode qui aide les modèles d'apprentissage à la machine à aligner les données audio et visuelles correspondantes à partir de clips vidéo sans avoir besoin d'étiquettes humaines.
Ils ont ajusté la façon dont leur modèle d'origine est formé afin qu'il apprenne une correspondance plus fine entre un cadre vidéo particulier et l'audio qui se produit à ce moment-là. Les chercheurs ont également fait des ajustements architecturaux qui aident le système à équilibrer deux objectifs d'apprentissage distincts, ce qui améliore les performances.
Ensemble, ces améliorations relativement simples renforcent la précision de leur approche dans les tâches de récupération vidéo et dans la classification de l'action dans les scènes audiovisuelles. Par exemple, la nouvelle méthode pourrait correspondre automatiquement et précisément au son d'une porte claquant avec le visuel de la fermeture dans un clip vidéo.
«Nous construisons des systèmes d'IA qui peuvent traiter le monde comme le font les humains, en termes de conception audio et visuelle à la fois et en mesure de traiter de manière transparente les deux modalités.
« Dans l'attente, si nous pouvons intégrer cette technologie audiovisuelle dans certains des outils que nous utilisons quotidiennement, comme les modèles de grande langue, il pourrait ouvrir de nombreuses nouvelles applications », explique Andrew Rouditchenko, un étudiant diplômé du MIT et co-auteur d'un article sur cette recherche publiée sur le MIT arxiv serveur de préimprimée.
Il est rejoint sur le journal par l'auteur principal Edson Araujo, étudiant diplômé à l'Université Goethe en Allemagne; Yuan Gong, un ancien MIT Postdoc; Saurabhchand Bhati, un MIT postdoc actuel; Samuel Thomas, Brian Kingsbury et Leonid Karlinsky d'IBM Research; Rogerio Feris, scientifique principal et directeur du laboratoire MIT-IBM Watson AI; James Glass, chercheur principal et chef du groupe de systèmes de langage parlé au MIT Informatique et Laboratoire d'intelligence artificielle (CSAIL); et l'auteur principal Hilde Kuehne, professeur d'informatique à l'Université Goethe et professeur affilié au MIT-IBM Watson AI Lab.
Les travaux seront présentés lors de la conférence sur la vision par ordinateur et la reconnaissance des modèles (CVPR 2025), qui se déroule à Nashville du 11 au 15 juin.
Synchronisation
Ce travail s'appuie sur une méthode d'apprentissage automatique que les chercheurs ont développé il y a quelques années, ce qui a fourni un moyen efficace de former un modèle multimodal pour traiter simultanément des données audio et visuelles sans avoir besoin d'étiquettes humaines.
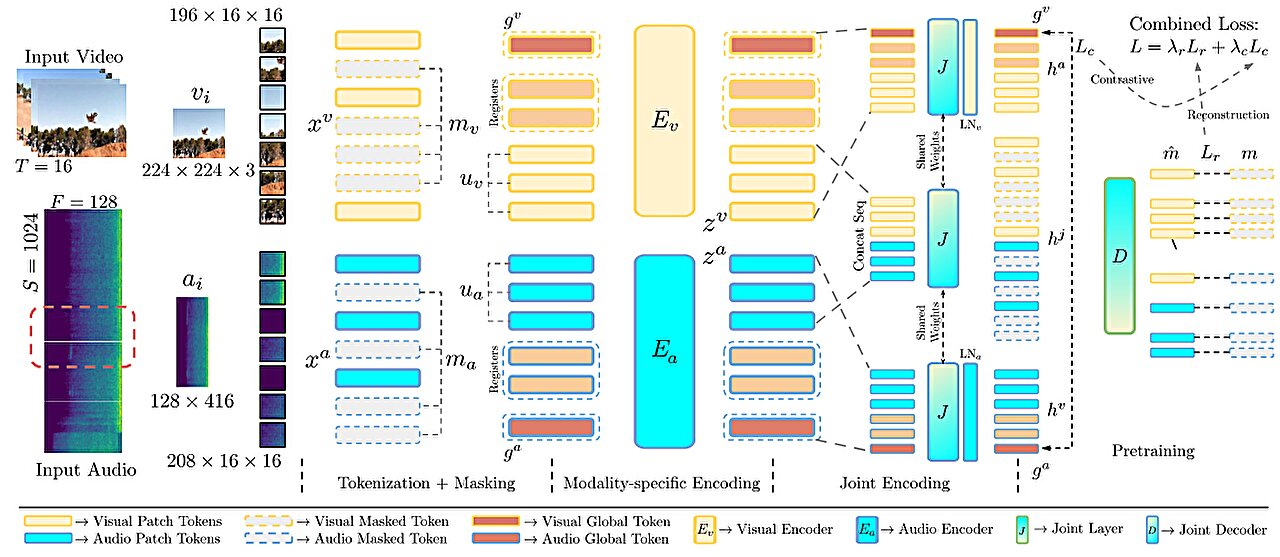
Les chercheurs alimentent ce modèle, appelé Cav-Mae, des clips vidéo non marqués et il code séparément les données visuelles et audio en représentations appelées jetons. En utilisant l'audio naturel de l'enregistrement, le modèle apprend automatiquement à cartographier des paires de jetons audio et visuels correspondants proches les uns des autres dans son espace de représentation interne.
Ils ont constaté que l'utilisation de deux objectifs d'apprentissage équilibre le processus d'apprentissage du modèle, ce qui permet à Cav-Mae de comprendre les données audio et visuelles correspondantes tout en améliorant sa capacité à récupérer des clips vidéo qui correspondent aux requêtes des utilisateurs.
Mais Cav-mae traite des échantillons audio et visuels comme une seule unité, donc un clip vidéo de 10 secondes et le son de la claque d'une porte sont cartographiés, même si cet événement audio se produit en une seconde de la vidéo.
Dans leur modèle amélioré, appelé Cav-Mae Sync, les chercheurs divisaient l'audio en fenêtres plus petites avant que le modèle ne calcule ses représentations des données, donc elle génère des représentations distinctes qui correspondent à chaque fenêtre audio plus petite.
Pendant la formation, le modèle apprend à associer un cadre vidéo à l'audio qui se produit pendant ce cadre.
« Ce faisant, le modèle apprend une correspondance plus fine, ce qui aide à la performance plus tard lorsque nous agrégeons ces informations », explique Araujo.
Ils ont également incorporé des améliorations architecturales qui aident le modèle à équilibrer ses deux objectifs d'apprentissage.
Ajout de «marge de manœuvre»
Le modèle intègre un objectif contrastif, où il apprend à associer des données audio et visuelles similaires, et un objectif de reconstruction qui vise à récupérer des données audio et visuelles spécifiques basées sur les requêtes utilisateur.
Dans la synchronisation CAV-MAE, les chercheurs ont introduit deux nouveaux types de représentations de données, ou jetons, pour améliorer la capacité d'apprentissage du modèle.
Ils incluent des «jetons mondiaux» dédiés qui aident à l'objectif d'apprentissage contrasté et à des «jetons d'enregistrement» dédiés qui aident le modèle à se concentrer sur des détails importants pour l'objectif de reconstruction.
« Essentiellement, nous ajoutons un peu plus de marge de manœuvre au modèle afin qu'il puisse effectuer chacune de ces deux tâches, contrastive et reconstructive, un peu plus indépendamment. Cela a profité aux performances globales », ajoute Araujo.
Bien que les chercheurs aient eu une certaine intuition, ces améliorations amélioreraient les performances de la synchronisation cav-mae, il a fallu une combinaison minutieuse de stratégies pour déplacer le modèle dans la direction qu'ils voulaient qu'il va.
« Parce que nous avons plusieurs modalités, nous avons besoin d'un bon modèle pour les deux modalités par eux-mêmes, mais nous devons également les amener à fusionner et à collaborer », explique Rouditchenko.
En fin de compte, leurs améliorations ont amélioré la capacité du modèle à récupérer des vidéos basées sur une requête audio et à prédire la classe d'une scène audiovisuelle, comme un aboyage de chien ou un jeu d'instrument.
Ses résultats étaient plus précis que leurs travaux antérieurs, et il a également fonctionné mieux que des méthodes plus complexes et de pointe qui nécessitent de plus grandes quantités de données de formation.
« Parfois, des idées très simples ou des petits modèles que vous voyez dans les données ont une grande valeur lorsqu'ils sont appliqués en plus d'un modèle sur lequel vous travaillez », explique Araujo.
À l'avenir, les chercheurs souhaitent intégrer de nouveaux modèles qui génèrent de meilleures représentations de données dans la synchronisation Cav-Mae, ce qui pourrait améliorer les performances. Ils veulent également permettre à leur système de gérer les données de texte, ce qui serait une étape importante vers la génération d'un modèle de langue audiovisuelle en grand.