
Les modèles d’IA sont toujours à la traîne des humains dans des tests de compréhension de texte simples
Une équipe de recherche internationale dirigée par l’URV a analysé les capacités de sept modèles d’intelligence artificielle (IA) dans la compréhension du langage et les a comparés à ceux de l’homme.
Les résultats, publiés dans la revue Rapports scientifiquesMontrez que, malgré leur succès dans certaines tâches spécifiques, les modèles n’atteignent pas un niveau comparable à celui des humains dans des tests de compréhension de texte simples.
« La capacité des modèles à effectuer des tâches complexes ne garantit pas qu’elles sont compétentes dans des tâches simples », a averti les chercheurs.
Les grands modèles de langue (LLMS) sont des réseaux de neurones conçus pour générer des textes de manière autonome à partir d’une demande d’utilisateur. Ils se spécialisent dans les tâches telles que la génération de réponses aux requêtes générales, la traduction de textes, la résolution de problèmes et la résumé de contenu.
On prétend souvent que ces modèles ont des capacités similaires à celles de l’homme, en termes de compréhension et de raisonnement, mais les résultats de la recherche dirigée par Vittoria Dentella, chercheuse au groupe de recherche sur le langage et la linguistique de l’URV, montrent leurs limites: « LLMS Ne comprenez pas vraiment la langue, mais profitez simplement des modèles statistiques présents dans leurs données de formation. «
Les réseaux neuronaux sont des modèles de calcul qui imitent les structures neuronales biologiques du cerveau. Ils sont constitués d’une série de nœuds interconnectés, appelés neurones artificiels. Chaque nœud reçoit des informations des autres neurones, les traite et les envoie. Vu de l’extérieur, un réseau neuronal accepte une entrée, le traite et renvoie un résultat.
Les chercheurs doivent former le réseau avec des informations qu’ils connaissent afin qu’elles apprennent automatiquement à traiter les données pour fournir la réponse attendue. Une fois formés, ils sont utilisés dans les tâches de prédiction, la classification et le filtrage des données, la reconnaissance des modèles, etc.
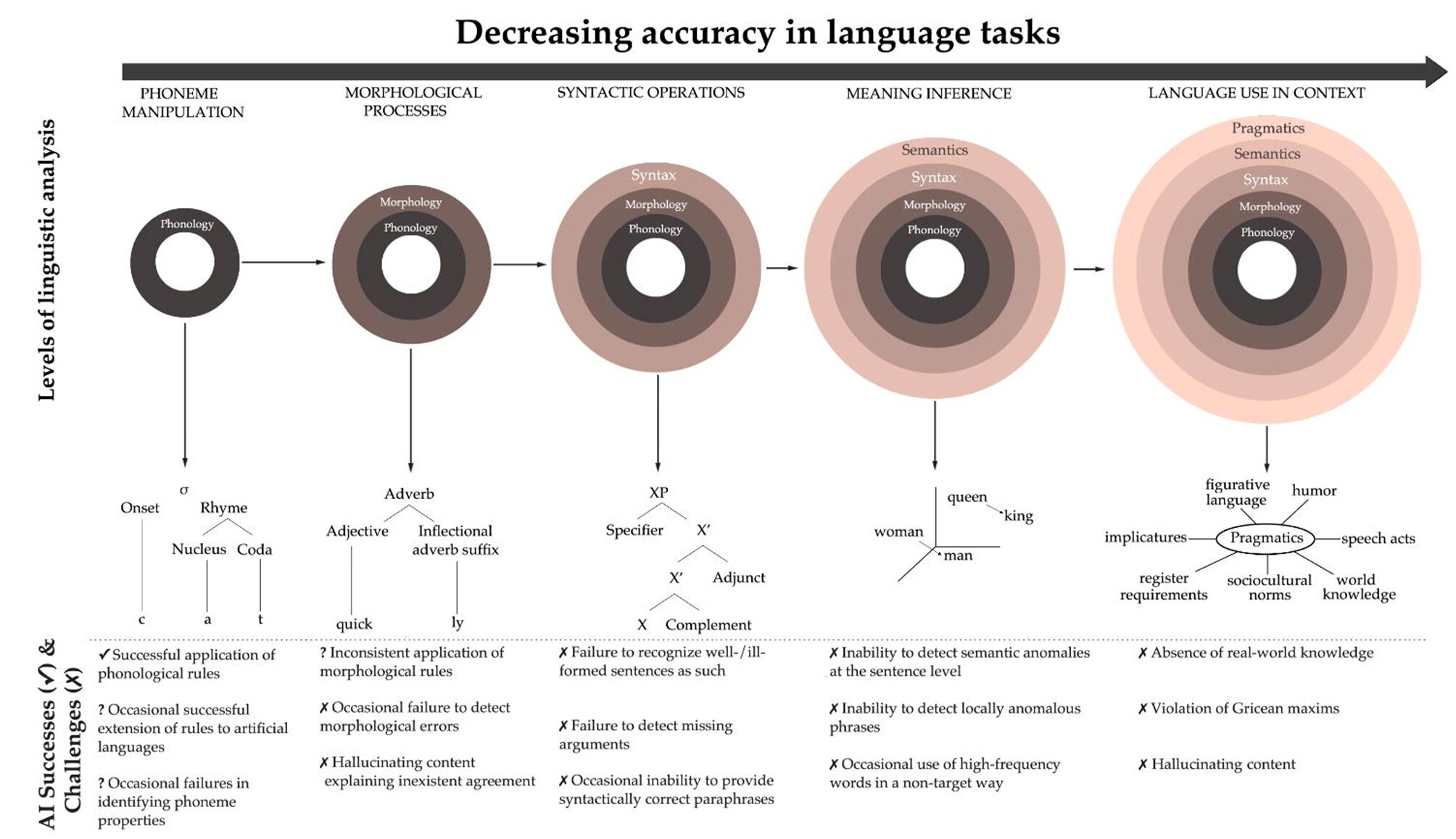
Afin de comparer les performances des humains et des LLM dans la compréhension du texte, les chercheurs ont posé 40 questions à sept modèles d’IA (Bard, Chatgpt-3.5, Chatgpt-4, Falcon, Gemini, Llama2 et Mixtral), en utilisant des structures grammaticales simples et fréquemment utilisées verbes.
Dans le même temps, un groupe de 400 personnes, tous des anglophones natifs, ont été posés les mêmes questions et la précision de leurs réponses a été comparée à celles des LLM. Chaque question a été répétée trois fois pour évaluer la cohérence des réponses.
La précision humaine moyenne était de 89%, bien supérieure à celle des modèles d’IA, dont la meilleure (ChatGPT-4) a fourni 83% de réponses correctes.
Les résultats montrent une grande différence dans les performances des technologies de compréhension du texte: à l’exception de ChatGPT-4, aucun des LLM n’a atteint une précision de plus de 70%. Les humains étaient également plus cohérents face à des questions répétées, en maintenant des réponses dans 87% des cas. Dans le cas des modèles de compréhension du texte, en revanche, c’était entre 66% et 83%
« Bien que les LLM peuvent générer des textes grammaticalement corrects et apparemment cohérents, les résultats de cette étude suggèrent que, en fin de compte, ils ne comprennent pas le sens du langage comme le fait un humain », explique la dentella.
En réalité, les modèles de langage étendus n’interprètent pas le sens comme le fait une personne – à travers une combinaison d’éléments sémantiques, grammaticaux, pragmatiques et contextuels. Ils travaillent en identifiant les modèles dans les textes qui leur ont été donnés, en les comparant avec les modèles des informations qui ont été utilisées pour les former, puis en utilisant des algorithmes prédictifs basés sur statistiquement. Leur humanité apparente est donc une illusion.
Le manque de compréhension des LLMS peut les empêcher de donner des réponses cohérentes, surtout lorsqu’elles sont soumises à des questions répétées, comme l’a révélé l’étude. Il explique également pourquoi les modèles peuvent fournir des réponses non seulement incorrectes, mais qui indiquent également qu’ils n’ont pas compris le contexte ou le sens d’un concept.
Cela signifie à son tour, prévient Dentella, que la technologie n’est pas encore suffisamment fiable pour être utilisée dans certaines applications critiques: « Nos recherches montrent que la capacité des LLM à effectuer des tâches complexes ne garantit pas qu’elles sont compétentes dans des tâches simples, qui sont souvent ceux qui nécessitent une réelle compréhension du langage. «