
Les modèles d'IA simulent des sujets humains pour aider la recherche en sciences sociales, mais les limites restent
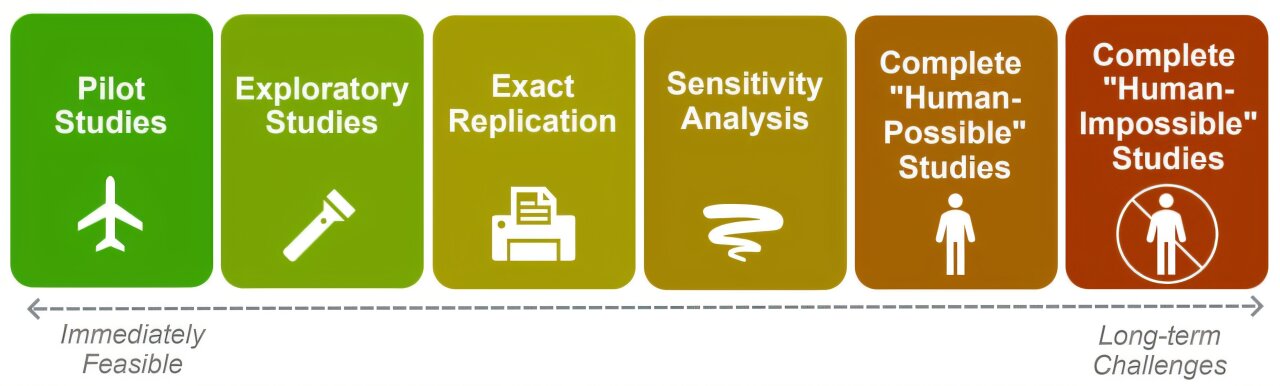
Les LLM qui imitent la parole humaine sont utilisées pour tester les hypothèses de manière rentable et mener des études pilotes, produisant des résultats précoces prometteurs. Mais les chercheurs notent que les données humaines restent essentielles.
En améliorant notre compréhension du comportement humain, la recherche en sciences sociales aide les entreprises à concevoir des programmes de marketing réussis, garantit que les politiques gouvernementales répondent aux besoins des gens et soutiennent le développement de stratégies appropriées pour lutter contre les maladies et maintenir la sécurité publique.
Cette recherche s'étend sur les domaines de l'économie, de la psychologie, de la sociologie et des sciences politiques et utilise une variété d'approches, du travail sur le terrain aux sondages en ligne, des essais contrôlés randomisés, des groupes de discussion, de l'observation, etc.
Mais toutes les recherches en sciences sociales sont compliquées par son sujet: les gens.
« Nous n'avons pas affaire à des boîtes de Pétri ou des plantes qui sont restées immobiles et nous permettent d'expérimenter sur de longues périodes », explique Jacy Anthis, érudit en visite au Stanford Institute for Human Centered IA (HAI) et un doctorat. candidat à l'Université de Chicago. « Et parce que nous étudions des sujets humains, cette recherche peut prendre du temps, coûteuse et difficile à reproduire. »
Avec les progrès de l'IA, cependant, les spécialistes des sciences sociales peuvent désormais simuler des données humaines. Des modèles de grandes langues (LLM) qui imitent la parole humaine peuvent jouer un rôle d'experts en sciences sociales ou des sujets humains divers à tester des hypothèses à peu de frais, à mener des études pilotes, à estimer les tailles d'échantillon optimales et à tirer parti du pouvoir statistique qu'une combinaison de sujets humains et LLM fournit.
Pourtant, il reste quelques façons dont les LLM ne sont pas un excellent remplaçant pour les sujets humains, Anthis note dans un nouveau journal publié sur le arxiv Serveur de préimprimée: ils donnent souvent des réponses moins variées, biaisées ou sycophantiques; Et ils ne généralisent pas bien aux nouveaux paramètres.
Pourtant, Anthis et d'autres sont optimistes quant à l'utilisation des LLM pour la recherche en sciences sociales, car certaines méthodes brutes et prêtes ont déjà produit des résultats prometteurs.
Si d'autres chercheurs tiennent compte de son cri de ralliement, dit Anthis, une année de travail supplémentaire pourrait conduire à des améliorations substantielles. « Alors que la technologie et la société évoluent rapidement, nous avons besoin d'outils de sciences sociales comme des simulations qui peuvent suivre le rythme. »
Évaluer l'IA comme proxy humain
Bien que l'IA ait fait de grandes sauts sur les références populaires, sa capacité à imiter les humains est un développement plus récent. Pour déterminer à quel point il prédit le comportement humain, Luke Hewitt, chercheur principal chez Stanford PACS, et ses collègues Robb Willer, Ashwini Ashokkumar et Isaias Ghezae ont été testés LLMS contre les essais contrôlés randomisés (RCTS)?
Les ECR typiques impliquent un « traitement » – certaines informations ou action que les chercheurs s'attendent à avoir un impact sur les attitudes ou le comportement d'une personne. Ainsi, par exemple, un chercheur pourrait demander aux participants de lire un texte, de regarder une courte vidéo ou de participer à un jeu sur un sujet (changement climatique ou vaccins, par exemple), puis leur demander leur opinion sur ce sujet et comparer leurs réponses à celles d'un groupe témoin qui n'a pas subi le traitement. Leurs opinions ont-elles changé par rapport aux témoins? Sont-ils plus susceptibles de changer, de démarrer ou d'arrêter les comportements pertinents?
Pour leur projet, Hewitt et ses collègues ont utilisé le modèle linguistique GPT-4 pour simuler comment un échantillon représentatif d'Américains réagirait à 476 traitements randomisés différents qui avaient été précédemment étudiés. Ils ont constaté que dans les expériences d'enquête en ligne, les prédictions LLM des réponses simulées étaient aussi précises que les prédictions des experts humains et sont fortement corrélées (0,85) avec des effets de traitement mesurés.
Cette précision est impressionnante, dit Hewitt. L'équipe a été particulièrement encouragée à trouver le même niveau de précision même lors de la réplication des études publiées après la formation du GPT-4. « Beaucoup se seraient attendus à voir le LLM réussir à simuler des expériences qui faisaient partie de ses données de formation et à échouer sur de nouvelles qu'elle n'avait jamais vues auparavant », a déclaré Hewitt. « Au lieu de cela, nous avons constaté que le LLM pourrait faire des prédictions assez précises même pour des expériences entièrement nouvelles. »
Malheureusement, dit-il, les nouveaux modèles sont plus difficiles à examiner. Ce n'est pas seulement parce que leurs données de formation comprennent des études réalisées plus récemment, mais aussi parce que les LLM commencent à effectuer leurs propres recherches sur le Web, leur donnant accès à des informations sur lesquelles ils n'ont pas été formés. Pour évaluer ces modèles, les chercheurs peuvent avoir besoin de créer une archive d'études non publiées jamais auparavant sur Internet.
L'IA est étroite d'esprit
Bien que les LLM montrent une précision potentielle dans les études de réplication, elles sont confrontées à d'autres défis majeurs que les chercheurs devraient trouver des moyens de relever.
L'une est l'alignement de la distribution: les LLM ont une incapacité remarquable pour correspondre à la variation des réponses des humains. Par exemple, en réponse à un jeu « choisir un nombre », les LLMS choisissent souvent une gamme de réponses plus étroite (et étrangement prévisible) que les gens. « Ils peuvent malporter et aplatir de nombreux groupes », explique Nicole Meister, étudiante diplômée en génie électrique à Stanford.
Dans un article récent, Meister et ses collègues ont évalué différentes façons de provoquer et de mesurer la distribution des réponses d'un LLM à diverses questions. Par exemple, un LLM pourrait être invité à répondre à une question sur la moralité de l'alcool à boire en sélectionnant l'une des quatre options de choix multiples: A, B, C ou D.
Un LLM n'écoute généralement qu'une seule réponse, mais une approche pour mesurer la distribution des réponses possibles est de regarder une couche plus profonde dans le modèle pour voir la probabilité évaluée par le modèle de chacune des quatre réponses avant de faire un choix final. Mais il s'avère que cette distribution dite de « probabilité de log » n'est pas très similaire aux distributions humaines, dit Meister. D'autres approches ont donné plus de variations humaines: demander au LLM de simuler 30 réponses de la personne ou de demander au LLM de verbaliser la distribution probable.
L'équipe a vu des résultats encore meilleurs lorsqu'il a fourni au LLM des informations de distribution sur la façon dont un groupe réagit généralement à une invite connexe, une approche meister appelle la direction « à quelques coups ». Par exemple, une LLM répondant à une question sur la façon dont les démocrates et les républicains pensent que la moralité de la consommation d'alcool allait mieux s'aligner sur les réelles réponses humaines si le modèle était amorcé avec la distribution des opinions par les démocrates et les républicains concernant la religion ou la conduite en état d'ivresse.
L'approche à quelques coups fonctionne mieux pour les questions basées sur l'opinion et moins bien pour les préférences, note Meister. « Si quelqu'un pense que les voitures autonomes sont mauvaises, il pensera probablement que la technologie est mauvaise et que le modèle fera ce saut », dit-elle. « Mais si j'aime les livres de guerre, cela ne signifie pas que je n'aime pas les livres mystères, il est donc plus difficile pour un LLM de faire cette prédiction. »
C'est une préoccupation croissante car certaines entreprises commencent à utiliser les LLM pour prédire des choses comme les préférences des produits. « Les LLM peuvent ne pas être le bon outil à cette fin », dit-elle.
Autres défis: validation, biais, sycophance et plus
Comme pour la plupart des technologies d'IA, l'utilisation des LLM dans les sciences sociales pourrait être nocive si les gens utilisent des simulations LLM pour remplacer les expériences humaines, ou s'ils les utilisent d'une manière qui n'est pas bien validée, dit Hewitt. Lorsque vous utilisez un modèle, les gens doivent avoir une idée de leur confiance: leur cas d'utilisation est-il suffisamment proche des autres utilisations sur lesquelles le modèle a été validé? « Nous progressons, mais dans la plupart des cas, je ne pense pas que nous ayons encore ce niveau de confiance », explique Hewitt.
Il sera également important, dit Hewitt, de mieux quantifier l'incertitude des prédictions du modèle. « Sans quantification de l'incertitude », dit-il, « les gens pourraient faire confiance aux prédictions d'un modèle insuffisamment dans certains cas et trop dans d'autres. »
Selon Anthis, d'autres défis clés de l'utilisation des LLM pour la recherche en sciences sociales comprennent:
- Biais: les modèles présentent systématiquement des groupes sociaux particuliers de manière inexacte, s'appuyant souvent sur les stéréotypes raciaux, ethniques et de genre.
- Sycophance: les modèles conçus comme des «assistants» ont tendance à offrir des réponses qui peuvent sembler utiles aux gens, qu'ils soient exacts.
- Alinéness: les réponses des modèles peuvent ressembler à ce qu'un humain pourrait dire, mais à un niveau plus profond, sont totalement étrangers. Par exemple, un LLM pourrait dire que 3.11 est supérieur à 3,9, ou il pourrait résoudre un problème mathématique simple en utilisant une méthode bizarrement complexe.
- Généralisation: Les LLM ne généralisent pas avec précision au-delà des données à portée de main, de sorte que les spécialistes des sciences sociales peuvent avoir du mal à les utiliser pour étudier de nouvelles populations ou un comportement en grand groupe.
Ces défis sont traitables, dit Anthis. Les chercheurs peuvent déjà appliquer certaines astuces pour atténuer les préjugés et la sycophance; Par exemple, la simulation basée sur des entretiens, la demandant au LLM de participer à un expert ou à affiner un modèle pour optimiser la simulation sociale. S'attaquer aux problèmes d'étalage et de généralisation est plus difficile et peut nécessiter une théorie générale du fonctionnement des LLM, qui fait actuellement défaut, dit-il.
Meilleures pratiques actuelles? Une approche hybride
Malgré les défis, les LLM d'aujourd'hui peuvent toujours jouer un rôle dans la recherche en sciences sociales. David Broska, étudiant diplômé en sociologie à Stanford, a développé une méthodologie générale d'utilisation de LLMS de manière responsable qui combine des sujets humains et des prédictions LLM dans une conception de sujets mixtes.
« Nous avons maintenant deux types de données », dit-il. « L'une est que les réponses humaines, qui sont très informatives mais coûteuses, et les autres prédictions LLM, n'est pas si informative mais bon marché. »
L'idée est de gérer d'abord une petite étude pilote avec des humains et également d'exécuter la même expérience avec un LLM pour voir à quel point les résultats sont interchangeables. L'approche, appelée inférence alimentée par la prédiction, combine efficacement les deux ressources de données tout en empêchant le LLM d'introduire un biais.
« Nous voulons garder ce que les sujets humains nous disent et augmenter notre confiance dans l'effet global du traitement tout en empêchant statistiquement la LLM de diminuer la crédibilité de nos résultats », dit-il.
Une première étude de pilote hybride peut également fournir une analyse du pouvoir – une estimation concrète de la proportion de sujets humains et LLM qui seront les plus susceptibles de générer un résultat statistiquement significatif, dit Broska. Cela met les chercheurs à réussir dans une étude hybride qui pourrait potentiellement être moins coûteuse.
Plus largement, Hewitt voit des cas où les simulations LLM sont déjà utiles. « Si je concevais une étude en ce moment pour tester une intervention pour changer les attitudes des gens à l'égard du climat par rapport à un événement d'actualités ou à une nouvelle politique, ou pour accroître la confiance du public dans les vaccins, je simulerais d'abord cette expérience dans un LLM et utiliserais les résultats pour augmenter mon intuition. »
La confiance dans le modèle est moins importante si le LLM aide uniquement à la sélection des conditions expérimentales ou au libellé d'une question d'enquête, dit Hewitt. Les sujets humains sont encore primordiaux.
« En fin de compte, si vous étudiez le comportement humain, votre expérience doit se terminer dans les données humaines. »