
Les modèles de vision ne peuvent pas gérer les requêtes avec des mots de négation, montre l’étude
Imaginez un radiologue examinant une radiographie pulmonaire d’un nouveau patient. Elle remarque que le patient a un gonflement dans le tissu mais n’a pas de cœur élargi. Cherchant à accélérer le diagnostic, elle pourrait utiliser un modèle d’apprentissage en machine en langue visuelle pour rechercher des rapports de patients similaires.
Mais si le modèle identifie à tort les rapports avec les deux conditions, le diagnostic le plus probable pourrait être très différent: si un patient a un gonflement de tissu et un cœur élargi, la condition est très susceptible d’être liée au cardiaque, mais sans cœur élargi, il pourrait y avoir plusieurs causes sous-jacentes.
Dans une nouvelle étude apparaissant sur le arxiv Préprint Server, les chercheurs du MIT ont constaté que les modèles en langue visuelle sont extrêmement susceptibles de faire une telle erreur dans les situations du monde réel parce qu’ils ne comprennent pas la négation – des mots comme « non » et « ne sont pas » qui spécifient ce qui est faux ou absent.
« Ces mots de négation peuvent avoir un impact très significatif, et si nous utilisons simplement ces modèles, nous pouvons avoir des conséquences catastrophiques », explique Kumail Alhamoud, étudiant diplômé du MIT et auteur principal de cette étude.
Les chercheurs ont testé la capacité des modèles en langue visuelle à identifier la négation dans les légendes d’image. Les modèles ont souvent effectué une supposition aléatoire. S’appuyant sur ces résultats, l’équipe a créé un ensemble de données d’images avec des légendes correspondantes, y compris des mots de négation décrivant des objets manquants.
Ils montrent que le recyclage d’un modèle en langue visuelle avec cet ensemble de données conduit à des améliorations de performances lorsqu’un modèle est invité à récupérer des images qui ne contiennent pas certains objets. Il stimule également la précision sur la réponse aux questions à choix multiples avec des légendes nichées.
Mais les chercheurs avertissent que davantage de travaux sont nécessaires pour résoudre les causes profondes de ce problème. Ils espèrent que leur recherche alerter les utilisateurs potentiels d’une lacune auparavant inaperçue qui pourrait avoir de graves implications dans des contextes à enjeux élevés où ces modèles sont actuellement utilisés, en déterminant quels patients reçoivent certains traitements pour identifier les défauts des produits dans les usines de fabrication.
« Il s’agit d’un document technique, mais il y a des problèmes plus importants à considérer. Si quelque chose d’aussi fondamental que la négation est brisé, nous ne devrions pas utiliser de grands modèles de vision / langue de nombreuses façons dont nous les utilisons maintenant – sans évaluation intensive », a déclaré l’auteur principal Marzyeh Ghassemi, un professeur agrégé au ministère de l’ingénierie électrique et de l’informatique (EECS) et un membre de l’Institut de Sciences de l’ingénierie médicale et du laboratoire pour les systèmes de décisions.
Ghassemi et Alhamoud sont rejoints sur le journal par Shaden Alshammari, un étudiant diplômé du MIT; Yonglong Tian d’Openai; Guohao Li, un ancien post-doctorant à l’Université d’Oxford; Philip HS Torr, professeur à Oxford; et Yoon Kim, professeur adjoint d’EECS et membre du Laboratoire d’intelligence informatique et d’intelligence artificielle (CSAIL) au MIT. La recherche sera présentée lors de la conférence sur la vision par ordinateur et la reconnaissance des modèles.
Négliger la négation
Les modèles de vision en langue (VLM) sont formés à l’aide d’énormes collections d’images et de légendes correspondantes, qu’ils apprennent à coder en tant qu’ensembles de nombres, appelés représentations vectorielles. Les modèles utilisent ces vecteurs pour distinguer les différentes images.
Un VLM utilise deux encodeurs distincts, un pour le texte et un pour les images, et les encodeurs apprennent à produire des vecteurs similaires pour une image et sa légende de texte correspondante.
« Les légendes expriment ce qui se trouve dans les images – ce sont une étiquette positive. Et c’est en fait tout le problème. Personne ne regarde une image d’un chien qui sautait par-dessus une clôture et le décortique en disant » un chien sautant par-dessus une clôture, sans hélicoptères « », explique Ghastemi.
Étant donné que les ensembles de données de caption d’image ne contiennent pas d’exemples de négation, les VLM n’apprennent jamais à l’identifier.
Pour approfondir ce problème, les chercheurs ont conçu deux tâches de référence qui testent la capacité des VLM à comprendre la négation.
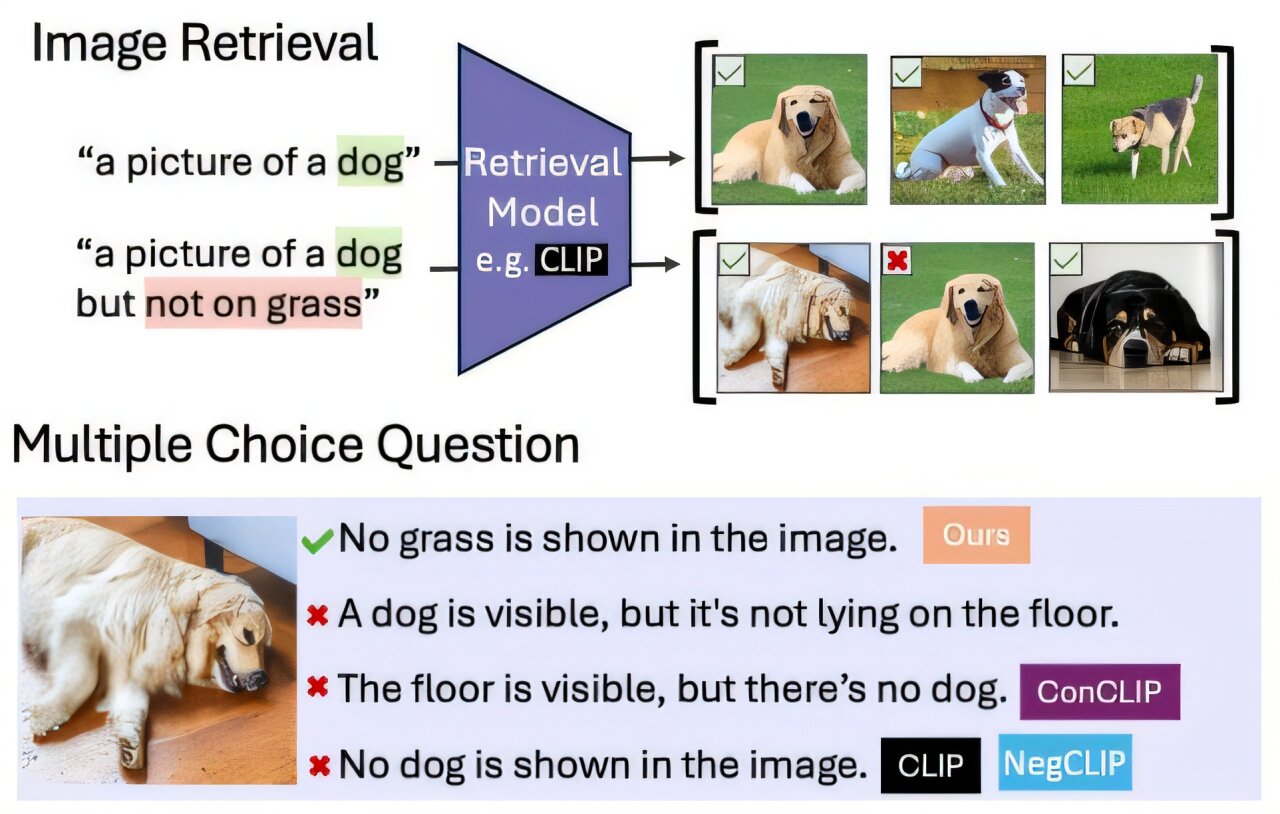
Pour le premier, ils ont utilisé un modèle grand langage (LLM) pour recaper des images dans un ensemble de données existant en demandant au LLM de penser aux objets connexes et non dans une image et à les écrire dans la légende. Ensuite, ils ont testé des modèles en les invitant avec des mots de négation pour récupérer des images contenant certains objets, mais pas d’autres.
Pour la deuxième tâche, ils ont conçu des questions à choix multiples qui demandent à un VLM de sélectionner la légende la plus appropriée dans une liste d’options étroitement liées. Ces légendes ne diffèrent qu’en ajoutant une référence à un objet qui n’apparaît pas dans l’image ou en noyant un objet qui apparaît dans l’image.
Les modèles ont souvent échoué aux deux tâches, avec des performances de récupération d’image baissant de près de 25% avec des légendes niées. En ce qui concerne la réponse à des questions à choix multiples, les meilleurs modèles n’ont atteint que 39% de précision, avec plusieurs modèles performants ou même en dessous de la chance aléatoire.
L’une des raisons de cet échec est un raccourci que les chercheurs appelle le biais d’affirmation – les VLMs ignorent les mots de négation et se concentrent plutôt sur des objets dans les images.
« Cela ne se produit pas seulement pour des mots comme« non »et« pas ». Quelle que soit la façon dont vous exprimez la négation ou l’exclusion, les modèles l’ignoreront simplement « , explique Alhamoud.
Cela était cohérent dans chaque VLM qu’ils ont testé.
‘Un problème résoluble’
Étant donné que les VLM ne sont généralement pas formés sur les légendes d’image avec une négation, les chercheurs ont développé des ensembles de données avec des mots de négation comme première étape vers la résolution du problème.
En utilisant un ensemble de données avec 10 millions de paires de légendes de texte d’image, ils ont incité un LLM à proposer des légendes connexes qui spécifient ce qui est exclu des images, produisant de nouvelles légendes avec des mots de négation.
Ils devaient être particulièrement prudents que ces légendes synthétiques se lisent toujours naturellement, ou cela pourrait faire échouer un VLM dans le monde réel face à des légendes plus complexes écrites par les humains.
Ils ont constaté que les VLM à réglage fin avec leur ensemble de données conduisaient à des gains de performances à tous les niveaux. Il a amélioré les capacités de récupération d’images des modèles d’environ 10%, tout en augmentant les performances de la tâche de réponses à choix multiple d’environ 30%.
« Mais notre solution n’est pas parfaite. Nous ne faisons que des ensembles de données de recaption, une forme d’augmentation des données. Nous n’avons même pas touché la façon dont ces modèles fonctionnent, mais nous espérons que c’est un signal qu’il s’agit d’un problème résoluble et d’autres peuvent prendre notre solution et l’améliorer », explique Alhamoud.
Dans le même temps, il espère que leur travail encourage davantage d’utilisateurs à réfléchir au problème qu’ils veulent utiliser un VLM pour résoudre et concevoir quelques exemples pour le tester avant le déploiement.
À l’avenir, les chercheurs pourraient développer ce travail en enseignant aux VLMS pour traiter le texte et les images séparément, ce qui pourrait améliorer leur capacité à comprendre la négation. De plus, ils pourraient développer des ensembles de données supplémentaires qui incluent des paires de caption d’image pour des applications spécifiques, telles que les soins de santé.