
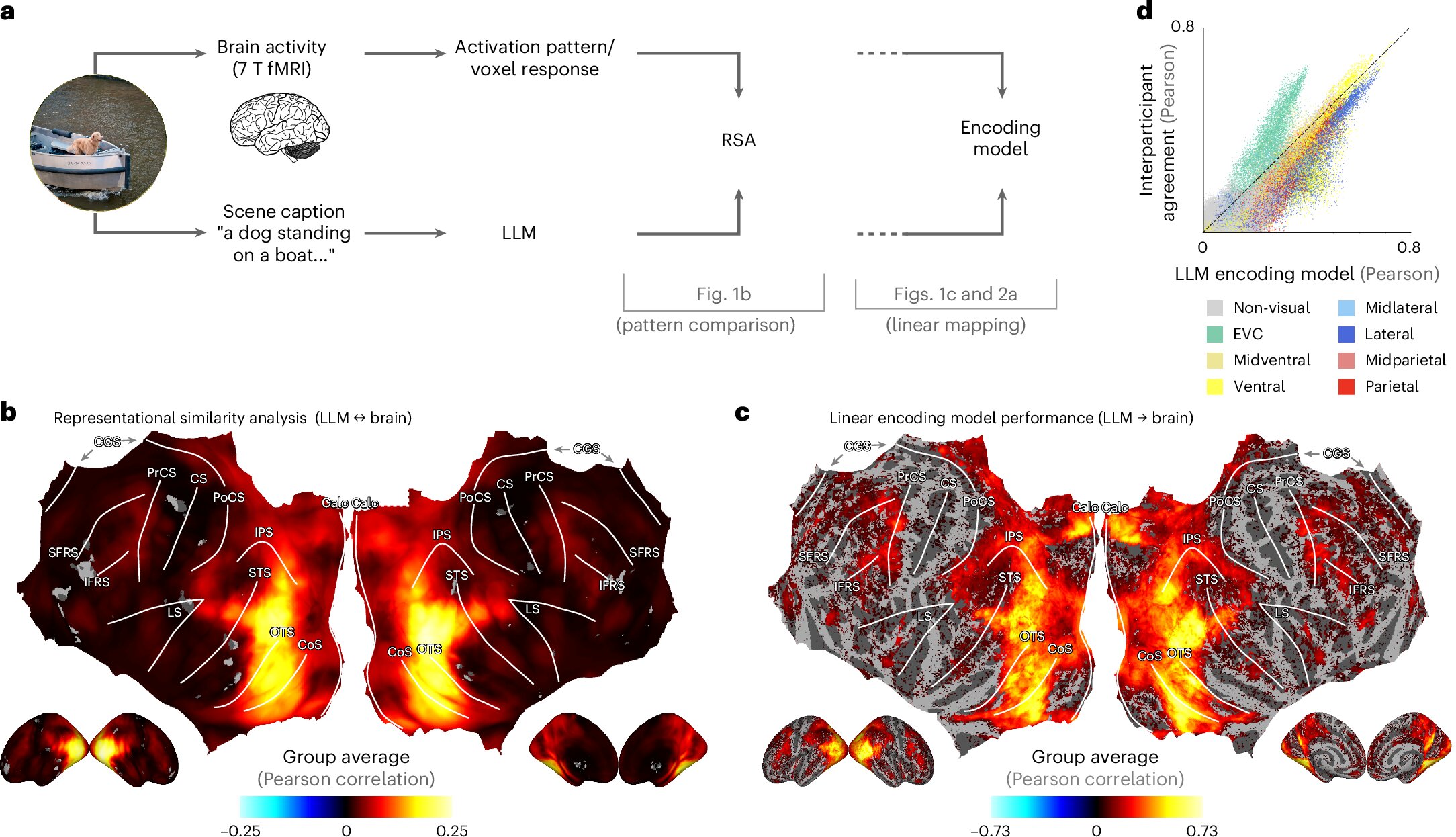
Les LLM peuvent correspondre aux perceptions du cerveau humain dans les scènes de tous les jours
Lorsque nous regardons le monde, notre cerveau ne reconnaît pas seulement des objets tels que « un chien » ou « une voiture », il comprend également le sens plus large, comme ce qui se passe, où cela se produit et comment tout s'intègre. Mais pendant des années, les scientifiques n'avaient pas un bon moyen de mesurer cette compréhension riche et complexe.
Maintenant, dans une nouvelle étude publiée aujourd'hui dans Intelligence de la machine de la natureUniversité de Montréal, professeur agrégé de psychologie, Ian Charest explique comment lui et ses collègues de l'Université du Minnesota et de l'Université allemande d'Osnabrück et de Frei Universität Berlin ont utilisé des modèles de grande langue (LLMS) pour le comprendre.
« En alimentant les descriptions de scène naturelle dans ces LLM – le même type d'IA derrière des outils comme Chatgpt – nous avons créé une sorte d'empreinte digitale basée sur le langage » de ce qu'une scène signifie « , a déclaré Charest, titulaire de la présidence Courtois d'Udem en neurosciences fondamentales et membre de Mila – Carebec AI Institute.
« Remarquablement », a-t-il dit, « ces empreintes digitales correspondaient étroitement aux modèles d'activité cérébrale enregistrés tandis que les gens regardaient les mêmes scènes dans un scanner IRM », des choses comme un groupe d'enfants jouant ou une grande ligne d'horizon.
« Par exemple », a déclaré Charest, « à l'aide de LLMS, nous pouvons décoder dans une phrase la scène visuelle que la personne vient de percevoir. Nous pouvons également prédire précisément comment le cerveau réagirait aux scènes d'aliments ou de lieux ou de scènes, y compris des visages humains, en utilisant les représentations codées dans le LLM. »
Les chercheurs sont allés encore plus loin: ils ont formé des réseaux de neurones artificiels pour prendre des images et prédire ces empreintes digitales LLM – et ont constaté que ces réseaux faisaient un meilleur travail pour faire correspondre les réponses cérébrales que bon nombre des modèles de vision d'IA les plus avancés disponibles aujourd'hui.
Et cela, malgré le fait que ces modèles disponibles ont été formés sur des données beaucoup moins.
La conception de ces «réseaux de neurones artificiels» a été soutenu par le professeur de l'apprentissage automatique Tim Kietzmann et son équipe à l'Université d'Osnabrück. Le premier auteur de l'étude est le professeur Adrien Doerig de Freie Universität Berlin.
« Ce que nous avons appris suggère que le cerveau humain peut représenter des scènes visuelles complexes d'une manière étonnamment similaire à la façon dont les modèles de langage modernes comprennent le texte », a déclaré Charest, qui poursuit ses recherches sur le sujet.
« Notre étude ouvre de nouvelles possibilités pour décoder les pensées, améliorer les interfaces cérébrales-ordinateurs et construire des systèmes d'IA plus intelligents qui« voyons »plus comme nous les humains. Nous pourrions un jour imaginer de meilleurs modèles de vision de vision soutenant de meilleures décisions pour les voitures autonomes.
« Ces nouvelles technologies pourraient également un jour aider à développer des prothèses visuelles pour les personnes ayant des déficiences visuelles importantes. Mais en fin de compte, c'est un pas en avant pour comprendre comment le cerveau humain comprend le sens du monde visuel. »