

les grands modèles linguistiques expliqués de manière simple
Les progrès de l’IA ces dernières années peuvent être attribués à de nombreux facteurs, mais l’un d’entre eux est sans aucun doute le Grand modèle linguistique (LLM). De nombreux outils d'IA pour la génération de texte sont alimentés par LLM ; Par exemple, ChatGPT utilise le modèle GPT.
Un modèle de langage est un modèle NLP probabiliste
L'apprentissage automatique est un domaine de l'intelligence artificielle qui se concentre sur les études de généralisation des données avec des algorithmes statistiques. Dans un sens, l’apprentissage automatique tente d’atteindre l’intelligence artificielle en étudiant les données afin que le programme puisse effectuer des tâches intelligentes sans instructions. Historiquement, le domaine qui croise l'informatique et la linguistique est appelé le domaine de la Traitement du langage naturel. Le domaine concerne principalement toute tâche de traitement automatique de textes humains, tels que les documents texte.
Auparavant, ce domaine se limitait uniquement aux systèmes basés sur des règles, mais s'est élargi avec l'introduction d'algorithmes avancés semi-supervisés et non supervisés qui permettent au modèle d'apprendre sans aucune direction.
L'un des modèles avancés pour ce faire est le modèle linguistique. Le modèle de langage est un modèle NLP probabiliste pour effectuer de nombreuses tâches humaines telles que la traduction, la correction grammaticale et la génération de texte.
L'ancienne forme du modèle de langage utilise des approches purement statistiques telles que méthode n-gramme, où l'hypothèse est que la probabilité du mot suivant dépend uniquement des données de taille fixe du mot précédent. Cependant, l'introduction du Les réseaux de neurones elle a détrôné l’approche précédente. Un réseau de neurones artificiels, ou NN, est un programme informatique qui imite la structure des neurones du cerveau humain. L'approche du réseau neuronal est intéressante à utiliser car elle peut gérer la reconnaissance de formes complexes à partir de données textuelles et gérer des données séquentielles telles que du texte.
C'est pourquoi le modèle linguistique actuel est généralement basé sur NN.
Les grands modèles de langage, ou LLM, sont des modèles d'apprentissage automatique qui apprennent à partir d'un grand nombre de documents de données pour effectuer la génération de langage à usage général. Je suis toujours un modèle de langage, mais le grand nombre de paramètres appris par le NN les rend « grands ». En termes simples, le modèle pourrait fonctionner comme les humains écrivent en prédisant très bien les mots suivants à partir des mots d'entrée donnés. Des exemples de tâches LLM incluent la traduction linguistique, le chatbot automatique, la réponse aux questions et bien d'autres. À partir de n'importe quelle séquence d'entrées donnée, le modèle pourrait identifier les relations entre les mots et générer des sorties appropriées à partir de l'instruction. Presque tous les produits d'IA générative qui utilisent la génération de texte sont alimentés par des LLM. ChatGPT, Bard de Google et bien d'autres utilisent LLM comme base de leur produit.
Comment fonctionnent les réseaux de neurones et l’apprentissage profond
Comme expliqué ci-dessus, LLM est un modèle de réseau neuronal formé sur d'énormes quantités de données textuelles. Pour mieux comprendre ce concept, il serait utile de comprendre comment fonctionnent les réseaux de neurones et l'apprentissage profond. Au niveau précédent, nous avons expliqué qu’un neurone neuronal artificiel est un modèle qui imite la structure neuronale du cerveau humain. Les principaux éléments du réseau neuronal sont les neurones, souvent appelés nœuds. Pour mieux expliquer le concept, regardez l'architecture typique du réseau neuronal dans l'image ci-dessous.
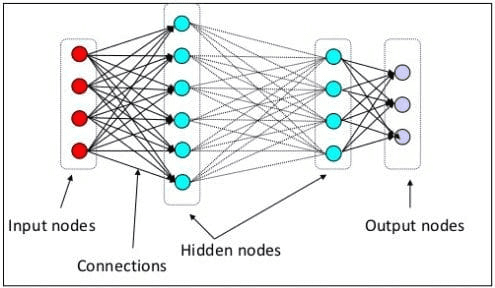
Comme nous pouvons le voir sur l’image, le réseau neuronal se compose de trois couches :
- Couche d'entréeoù il reçoit des informations et les transfère vers d'autres nœuds de la couche suivante.
- Couches de nœuds masquées où tous les calculs ont lieu.
- Couche de nœuds de sortie où se trouvent les sorties de calcul.
Il s'appelle l'apprentissage en profondeur lorsque nous entraînons notre modèle de réseau neuronal avec deux ou plusieurs couches cachées. Il s'appelle profond car il utilise de nombreuses couches intermédiaires. L’avantage des modèles d’apprentissage profond est qu’ils apprennent et extraient automatiquement des fonctionnalités des données que les modèles d’apprentissage automatique traditionnels ne peuvent pas. Dans les grands modèles de langage, l’apprentissage en profondeur est important puisque le modèle est basé sur des architectures de réseaux neuronaux profonds.
Donc, pourquoi ça s'appelle LLM ? Parce que des milliards de couches sont formées sur d’énormes quantités de données textuelles. Les couches produiraient des paramètres de modèle qui aideraient le modèle à apprendre des modèles complexes de langage, notamment la grammaire, le style d'écriture, etc.
Le processus simplifié de formation du modèle est présenté dans l'image ci-dessous.
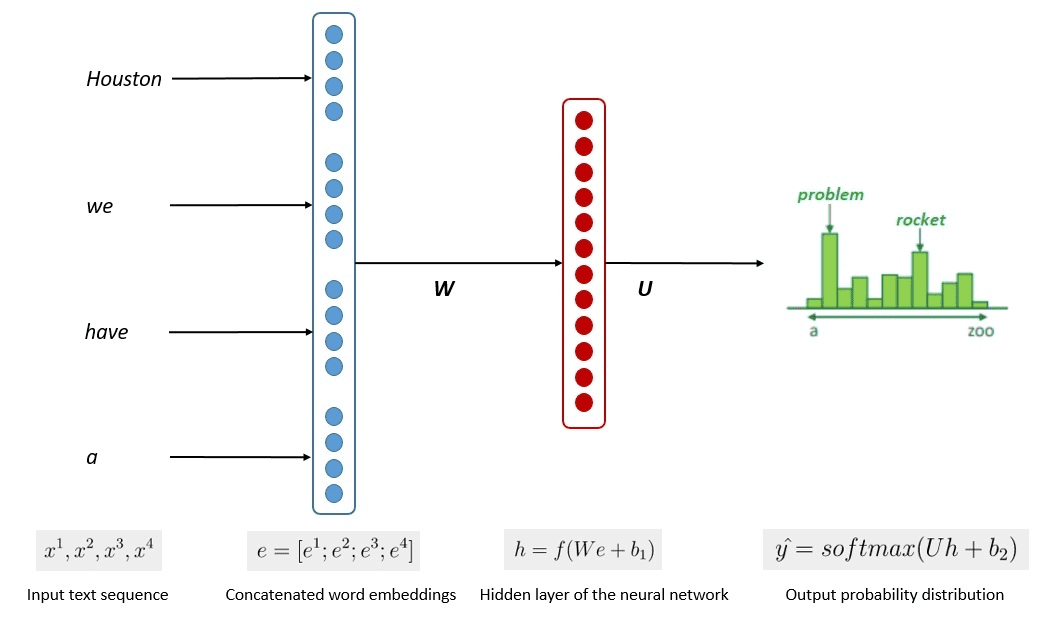
Le processus a montré que les modèles pouvaient générer un texte pertinent en fonction de la probabilité de chaque mot ou expression dans les données d'entrée. Dans les LLM, l'approche avancée utilise l'apprentissage auto-supervisé et semi-supervisé pour atteindre les capacités générales. L'apprentissage auto-supervisé est une technique dans laquelle nous n'avons pas d'étiquettes et où les données d'entraînement fournissent elles-mêmes le retour d'information sur l'entraînement. Il est utilisé dans le processus de formation LLM car les données manquent généralement d'étiquettes. En LLM, on pourrait utiliser le contexte environnant comme indice pour prédire les mots suivants.
En revanche, l’apprentissage semi-supervisé combine les concepts d’apprentissage supervisé et non supervisé avec une petite quantité de données étiquetées afin de générer de nouvelles étiquettes pour une grande quantité de données non étiquetées. L'apprentissage semi-supervisé est généralement utilisé pour les LLM ayant des besoins spécifiques en matière de contexte ou de domaine.
Transformateurs dans les grands modèles de langage : qu’est-ce que c’est ?
Nous avons discuté du fait que LLM est basé sur un modèle de réseau neuronal avec des techniques d'apprentissage en profondeur. Le LLM est généralement construit sur la base d'une architecture transformateurs (transformateurs) ces dernières années. Le transformateur est basé sur le mécanisme attention multi-têtes introduit par Vaswani et al. (2017) et a été utilisé dans de nombreux LLM. Les transformateurs sont une architecture modèle qui tente de résoudre des tâches séquentielles précédemment rencontrées dans les RNN et les LSTM. L'ancienne méthode du modèle linguistique consistait à utiliser RNN et LSTM pour traiter les données de manière séquentielle, où le modèle utiliserait chaque mot de sortie et les ramènerait afin que le modèle ne l'oublie pas. Cependant, ils rencontrent des problèmes avec les données à séquence longue une fois les transformateurs introduits.
Avant de plonger dans le transformateursnous introduisons le concept de encodeur-décodeur qui était auparavant utilisé dans les RNN. La structure codeur-décodeur permet que le texte d'entrée et de sortie n'ait pas la même longueur. L'utilisation typique est la traduction linguistique, qui a souvent une taille de séquence différente. La structure peut être divisée en deux. La première partie s'appelle encodeur, qui est une partie qui reçoit la séquence de données et crée une nouvelle représentation basée sur celle-ci. La représentation serait utilisée dans la deuxième partie du modèle, qui est le décodeur. Le problème avec RNN est que le modèle peut avoir besoin d'aide pour mémoriser des séquences plus longues, même avec la structure codeur-décodeur ci-dessus. C'est là que le mécanisme attention pourrait aider à résoudre le problème, une couche qui pourrait résoudre de longs problèmes d'entrée.
Le mécanisme d'attention a été introduit dans l'article de Bahdanau et al. (2014) pour résoudre les RNN de type codeur-décodeur en se concentrant sur une partie importante de l'entrée du modèle tout en prédisant la sortie. La structure du transformateur est inspirée du type codeur-décodeur et construite avec des techniques de mécanisme d'attention, il n'a donc pas besoin de traiter les données dans un ordre séquentiel. Le modèle global du transformateur est structuré comme l'image ci-dessous.
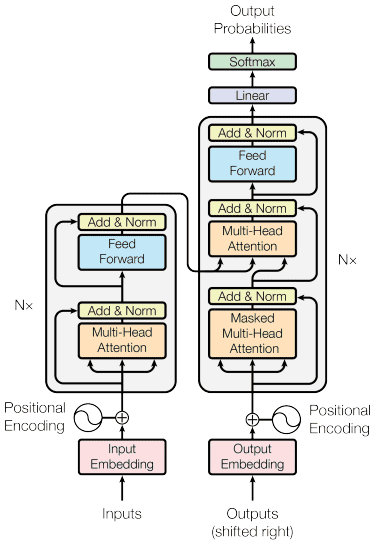
Dans la structure, les transformateurs codent la séquence du vecteur de données dans l'intégration de mots tout en utilisant le décodage pour transformer les données sous leur forme originale. Le codage peut attribuer une certaine importance à l'entrée avec le mécanisme attention.
Qu'est-ce qu'un support de données
Nous avons parlé des transformateurs qui codent le vecteur de données, mais qu'est-ce qu'un support de données ? Dans le modèle d’apprentissage automatique, nous ne pouvons pas saisir les données naturelles brutes, nous devons donc les transformer sous forme numérique. Le processus de transformation est appelé intégration de mots, où chaque mot d'entrée est traité via le modèle d'intégration de mots pour obtenir le vecteur de données. Nous pouvons utiliser de nombreuses intégrations de mots initiales, telles que Mot2vec ou Gantmais de nombreux utilisateurs avancés tentent de les affiner en utilisant leur propre vocabulaire.
Les transformateurs pourraient prendre en compte les entrées et fournir un contexte plus pertinent en présentant les mots sous des formes numériques comme le vecteur de données ci-dessus. Dans les LLM, les incorporations de mots dépendent généralement du contexte, généralement affinées en fonction des cas d'utilisation et du résultat attendu.