

Les entreprises américaines continuent de rechercher des modèles d’IA de plus en plus vastes. Ceux de Chine continuent de démontrer qu’il n’est pas nécessaire
Jusqu’à présent, Alibaba disposait d’un excellent modèle ouvert pour la programmation. Il est basé sur Qwen3.5-397B-A17B, mais le problème est qu’il était gigantesque avec ses 397 milliards de paramètres et ses 807 Go de taille disque (et mémoire). La société chinoise a fait quelque chose de surprenant et a annoncé ces jours-ci le modèle Qwen3.6-27B, qui dans sa version quantifiée pèse moins de 17 Go. On pourrait penser qu’à cette taille, il serait bien pire que son frère aîné. Mais vous auriez tort. C’est la preuve qu’il est possible de donner pour beaucoup moins cher.
Un modèle dense. La plupart des grands modèles de pondérations ouvertes en 2026 utilisent l’architecture Mixture-of-Experts (MoE) : ils ont de nombreux paramètres au total, mais n’en activent qu’une fraction lorsque nous les utilisons. Par exemple, le modèle Qwen3.5-397B-A17B indiquait précisément que dans son nom : sur les 397 milliards de paramètres, il n’en activait que 17 milliards (d’où l’A17B) lors de son utilisation.
Avec Qwen3.6-27B, nous avons ce qu’on appelle un modèle dense : les 27 milliards de paramètres sont activés dans chaque inférence. Même s’il est un peu moins efficace, il présente des avantages pratiques évidents. Par exemple, il n’est pas nécessaire de configurer un routeur expert et la quantification est plus prévisible et compacte. L’idée a fonctionné et les résultats le prouvent.
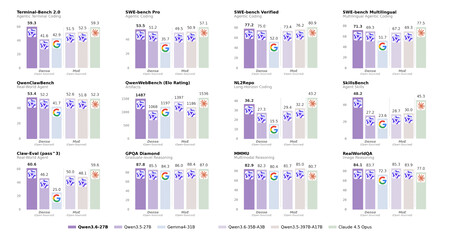
Les performances de ce « petit » modèle d’IA sont encore supérieures à celles d’une version précédente beaucoup plus grande.
Les benchmarks ne mentent pas (trop). Dans SWE-bench Verified, le benchmark le plus populaire pour les tâches de programmation réelles, Qwen3.6-27B obtient un score de 77,2 %, contre 76,2 % pour le modèle 397B. Dans Terminal-Bench 2.0, qui mesure la façon dont le modèle exécute les tâches dans la console de commande, il a obtenu 59,3% contre 2,5% pour son rival. Mais dans ce test, il obtient exactement le même score que Claude Opus 4.5, l’un des meilleurs modèles Anthropic récents. Qu’un modèle « Open Source » facilement utilisable localement parvienne à quelque chose comme ça est inhabituel, mais il faut être prudent : les benchmarks viennent d’Alibaba lui-même, et il n’y a actuellement aucune vérification indépendante, même si ceux qui l’utilisent semblent en être vraiment satisfaits.
Même Alibaba est surpris. Ce qui est frappant dans ce lancement, c’est que l’entreprise qui l’a lancé le promeut au-dessus de son modèle le plus ambitieux jusqu’à récemment. Qu’ils comparent eux-mêmes les deux versions et reconnaissent que la « petite » est la plus puissante est significatif. C’est comme dire sur les toits que les plus grands modèles d’IA n’ont pas de concurrence, alors qu’ils viennent de prouver que ce n’est pas le cas et que des modèles comme le Qwen3.6-27B peuvent avoir un comportement vraiment remarquable.

24 Go de VRAM, c’est « suffisant ». Grâce à sa petite taille, il est possible d’utiliser ce modèle sur des machines relativement accessibles. Ainsi, les 24 Go de mémoire vidéo du RTX 3090 font de ces cartes graphiques une alternative parfaite pour installer et utiliser Qwen3.6-27B avec d’excellentes performances. Les modèles denses ne fonctionnent pas très bien sur les MacBook ou Mac mini à mémoire unifiée, et même si tout le monde n’a logiquement pas accès aux cartes graphiques avec 24 Go de RAM, l’accès aux modèles locaux vraiment performants continue de s’améliorer.
Les meilleures essences, en petites bouteilles. Alibaba est un rouleau compresseur de « petits » modèles d’IA, et il l’a démontré début mars en en publiant plusieurs allant de 0,8 milliard à 9 milliards. Heureusement, il existe diverses alternatives dans ce segment des « Small Language Models » (SLM) et nous avons ici des exemples de référence tels que Gemma 4, récemment lancé par Google. Microsoft avec Phi-4 (qui nécessite une mise à jour, comme gpt-oss-20b/120b) ou Mistral avec Devstral 2 sont des exemples de sociétés occidentales qui progressent également dans ce domaine intéressant.
Mais. Selon les benchmarks, le Qwen3.6-27b est comparable dans certains benchmarks au Claude Opus 4.5, le modèle le plus avancé d’Anthropic lors de son lancement en novembre 2025. Cela est surprenant et confirme que les modèles à poids ouvert des entreprises chinoises ont, comme l’a dit Demis Hassabis, entre 6 et 12 mois de retard sur les modèles les plus avancés d’Anthropic, OpenAI ou Google. Mais pour les exécuter, un investissement important est encore nécessaire, et bien que les modèles d’IA locaux soient très intéressants en termes de confidentialité, si aujourd’hui on veut une vitesse et des performances maximales, cela dépend toujours des modèles commerciaux dans le cloud.
À Simseo | Google investira jusqu’à 40 milliards de dollars dans Anthropic parce que la nouvelle norme pour l’IA consiste à investir dans votre ennemi