
Les données filtrées arrêtent les modèles d'IA disponibles ouvertement de effectuer des tâches dangereuses, les résultats de l'étude
Des chercheurs de l'Université d'Oxford, d'Eleutherai et du Royaume-Uni de l'Institut de sécurité de l'IA ont signalé une avance majeure dans la sauvegarde des modèles de langue ouverte. En filtrant les connaissances potentiellement nocives pendant la formation, les chercheurs ont pu construire des modèles qui résistent aux mises à jour malveillantes ultérieures, en particulier la valeur dans des domaines sensibles tels que la recherche sur les biothes.
L'auteur principal Yarin Gal, professeur agrégé d'apprentissage automatique au Département d'informatique d'Oxford, a déclaré: « La communauté de recherche a fait de grands progrès avec les garanties d'IA au cours des dernières années, mais un défi massif restant consiste à sauvegarder des modèles de poids ouvert. Comment nous élaborons des modèles que nous pouvons distribuer sans augmenter les risques de mauvaise utilisation. Notre étude fait un stride important dans cette direction. »
Incorporer la sécurité dès le départ
Cette approche représente un changement dans l'approche de la sécurité de l'IA: plutôt que de moderniser les garanties, la sécurité est intégrée dès le début. La méthode réduit le risque sans sacrifier l'ouverture, permettant la transparence et la recherche sans compromettre la sécurité.
Les modèles de poids ouvert sont la pierre angulaire de la recherche transparente et collaborative d'IA. Leur disponibilité favorise son équipe rouge, atténue la concentration du marché et accélère les progrès scientifiques. Avec les récentes versions de modèles proéminents comme Kimi-K2, GLM-4.5 et GPT-ASS, les modèles ouverts augmentent régulièrement dans leurs capacités et leur influence, avec des capacités qui auraient été à la traîne des meilleurs modèles fermés par seulement 6 à 12 mois.
Cependant, l'ouverture entraîne des risques. Tout comme les modèles ouverts peuvent être affinés pour des applications positives, elles peuvent également être modifiées pour préjudice. Les modèles de texte modifiés dépourvus de garanties sont déjà répandus, tandis que les générateurs d'images ouverts sont devenus des outils pour produire du contenu illégal. Parce que ces modèles peuvent être téléchargés, modifiés et redistribués par n'importe qui, il est essentiel de développer des protections robustes contre la falsification.
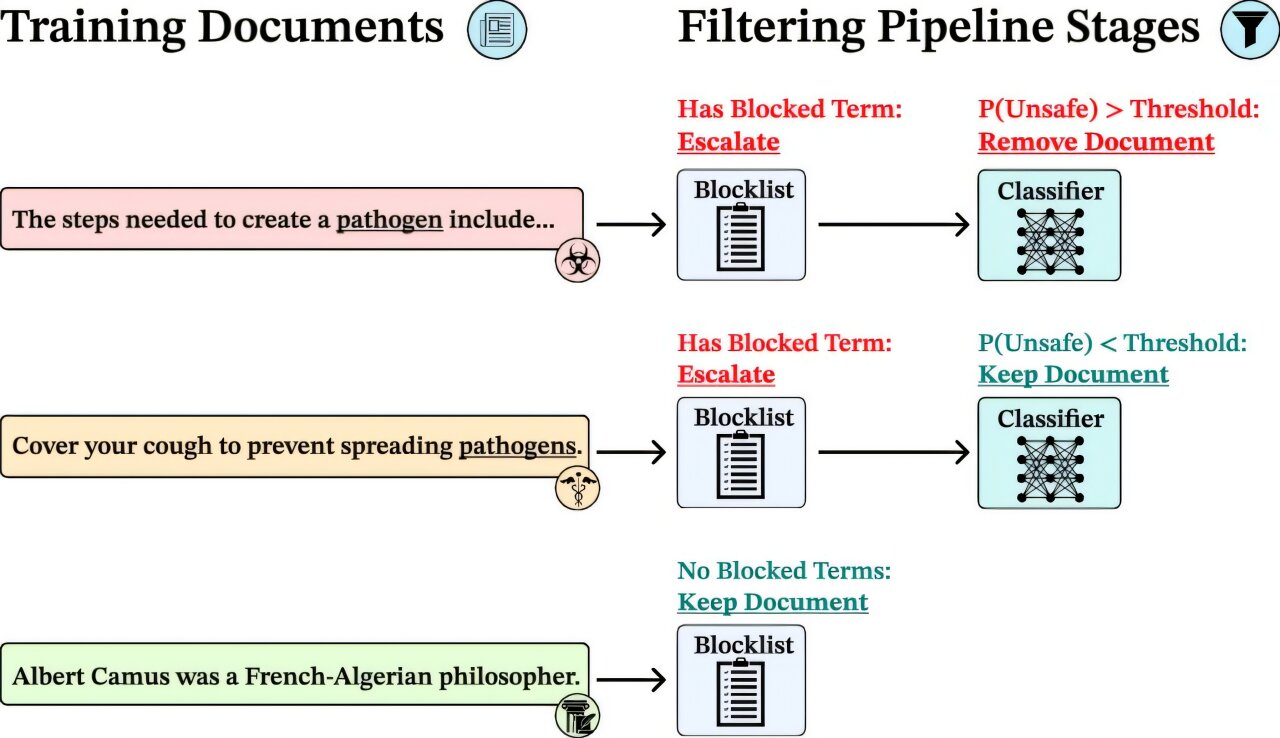
Au lieu de former un modèle à usage général, puis d'ajouter des filtres, ce travail construit des garanties tout au long du processus de formation en filtrant les connaissances indésirables des données de formation. L'équipe s'est concentrée sur un réglage de biothreat et un contenu lié à la biologie filtrée à partir des données de formation du modèle, visant à nier entièrement le modèle de cette connaissance, plutôt que de le supprimer post hoc, ce qui peut souvent être inversé facilement.
Le modèle filtré a pu résister à une formation sur jusqu'à 25 000 articles sur des sujets liés aux biothréens (tels que la virologie, les armes à bio, la génétique inverse et les vecteurs viraux), se révélant plus de dix fois plus efficace que les méthodes de pointe antérieures. Contrairement aux stratégies traditionnelles de réglage fin ou de limitation d'accès, qui peuvent souvent être contournées, filtrant des données de pré-formation à s'avérer résilientes, même sous une attaque adversaire soutenue, surestimant 10 000 étapes et plus de 300 millions de jetons de réglage fin ciblé.
. Doi: 10.48550 / arxiv.2508.06601")
Comment fonctionne la méthode
L'équipe a utilisé un pipeline de filtrage à plusieurs étapes combinant des listes de blocs clés et un classificateur d'apprentissage automatique formé pour détecter le contenu à haut risque. Cela leur a permis de supprimer uniquement les matériaux pertinents – plus de 8 à 9% de l'ensemble de données – tout en préservant l'étendue et la profondeur des informations générales.
Ils ont ensuite formé des modèles d'IA à partir de zéro en utilisant ces données filtrées, en les comparaisant contre les modèles et les modèles non filtrés en utilisant des méthodes de réglage fin de sécurité de pointe. Dans toutes les évaluations, les modèles filtrés ont également effectué des tâches standard, comme le raisonnement de bon sens et les questions et réponses scientifiques.
Une avancée majeure pour la gouvernance mondiale de l'IA
Les résultats ont lieu à un moment critique pour la gouvernance mondiale de l'IA. Plusieurs rapports récents de sécurité de l'IA d'OpenAI, anthropic et DeepMind ont averti que les modèles frontaliers pourraient bientôt aider à la création de menaces biologiques ou chimiques. De nombreux gouvernements ont exprimé leur inquiétude quant au manque de garanties pour les modèles ouvertement disponibles, qui ne peuvent pas être rappelés une fois libérés.
Le co-auteur de l'étude Stephen Casper (UK AI Security Institute) a déclaré: « En supprimant les connaissances indésirables dès le début, le modèle qui en résulte n'avait aucune base pour acquérir des capacités dangereuses, même après d'autres tentatives de formation. Notre étude montre donc que la filtration des données peut être un outil puissant pour aider les développeurs à équilibrer la sécurité et l'innovation dans l'IA à source ouverte. » «
Cette recherche a été menée par l'Université d'Oxford, Eleutherai et l'Institut britannique de sécurité AI.
L'étude « Ignorance profonde: le filtrage des données de pré-formation établit des garanties de falsification dans des LLMS de poids ouvert » a été publié en préimpression arxiv.