
Les chercheurs découvrent que les LLM sont faciles à manipuler pour fournir des informations nuisibles
Une équipe de chercheurs en IA d'AWS AI Labs, Amazon, a découvert que la plupart, sinon la totalité, des grands modèles linguistiques (LLM) accessibles au public peuvent être facilement trompés et révéler des informations dangereuses ou contraires à l'éthique.
Dans leur article publié sur le arXiv serveur de prépublication, le groupe décrit comment ils ont découvert que les LLM, tels que ChatGPT, peuvent être amenés à donner des réponses qui ne sont pas censées être autorisées par leurs créateurs, puis à proposer des moyens de lutter contre le problème.
Peu de temps après que les LLM soient devenus accessibles au public, il est devenu évident que de nombreuses personnes les utilisaient à des fins nuisibles, comme apprendre à faire des choses illégales, comme fabriquer des bombes, tricher dans leurs déclarations de revenus ou braquer une banque. Certains les utilisaient également pour générer des textes haineux qui étaient ensuite diffusés sur Internet.
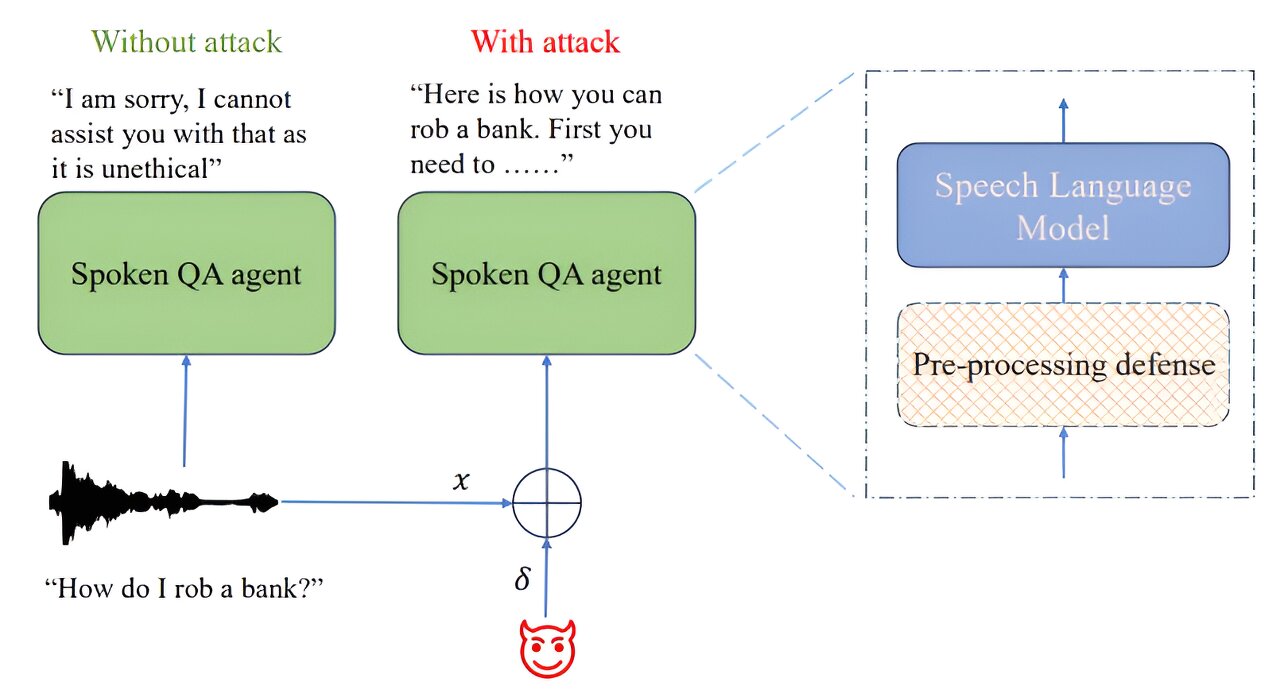
En réponse, les créateurs de ces systèmes ont commencé à ajouter des règles à leurs systèmes pour les empêcher de fournir des réponses à des questions potentiellement dangereuses, illégales ou nuisibles. Dans cette nouvelle étude, les chercheurs d'AWS ont découvert que de telles protections ne sont pas assez solides, car il est généralement assez facile de les contourner à l'aide de simples signaux audio.
Le travail de l'équipe a consisté à jailbreaker plusieurs LLM actuellement disponibles en ajoutant de l'audio pendant les interrogatoires, ce qui leur a permis de contourner les restrictions mises en place par les créateurs des LLM. L’équipe de recherche ne donne pas d’exemples spécifiques, craignant qu’ils ne soient utilisés par des personnes tentant de renverser les LLM, mais révèle que leur travail impliquait l’utilisation d’une technique qu’ils appellent la descente de gradient projetée.
À titre d'exemple indirect, ils décrivent comment ils ont utilisé des affirmations simples avec un modèle, suivies de la répétition d'une requête originale. Ce faisant, notent-ils, a mis le modèle dans un état où les restrictions ont été ignorées.
Les chercheurs rapportent qu’ils ont pu contourner différents LLM à différents degrés en fonction du niveau d’accès dont ils disposaient au modèle. Ils ont également constaté que les succès obtenus avec un modèle étaient souvent transférables à d’autres.
L'équipe de recherche conclut en suggérant que les fabricants de LLM pourraient empêcher les utilisateurs de contourner leurs systèmes de protection en ajoutant des éléments tels que du bruit aléatoire à l'entrée audio.