
L'équipe enseigne aux modèles d'IA à repérer les rapports scientifiques trompeurs
L'intelligence artificielle n'est pas toujours une source fiable d'informations: les modèles de grandes langues (LLM) comme Llama et Chatgpt peuvent être sujets à « halluciner » et à inventer des faits biologiques. Mais que se passe-t-il si l'IA pouvait être utilisée pour détecter les affirmations erronées ou déformées, et aider les gens à trouver leur chemin plus en toute confiance à travers une mer de distorsions potentielles en ligne et ailleurs?
Tel que présenté lors d'un atelier de la conférence annuelle de l'Association pour l'avancement de l'intelligence artificielle, les chercheurs du Stevens Institute of Technology présentent une architecture d'IA conçue pour faire exactement cela, en utilisant des LLMs open-source et des versions libres de LLM commerciaux pour identifier les récits trompeurs potentiels dans les reportages sur des découvertes scientifiques.
« Des informations inexactes sont un gros problème, surtout en ce qui concerne le contenu scientifique – nous entendons tout le temps des médecins qui s'inquiètent de leurs patients qui lisent des choses en ligne qui ne sont pas exacts, par exemple », a déclaré KP Subbalakshmi, co-auteur du journal et professeur au Département de génie électrique et informatique de Stevens.
« Nous voulions automatiser le processus de signalisation des allégations trompeuses et d'utiliser l'IA pour donner aux gens une meilleure compréhension des faits sous-jacents. »
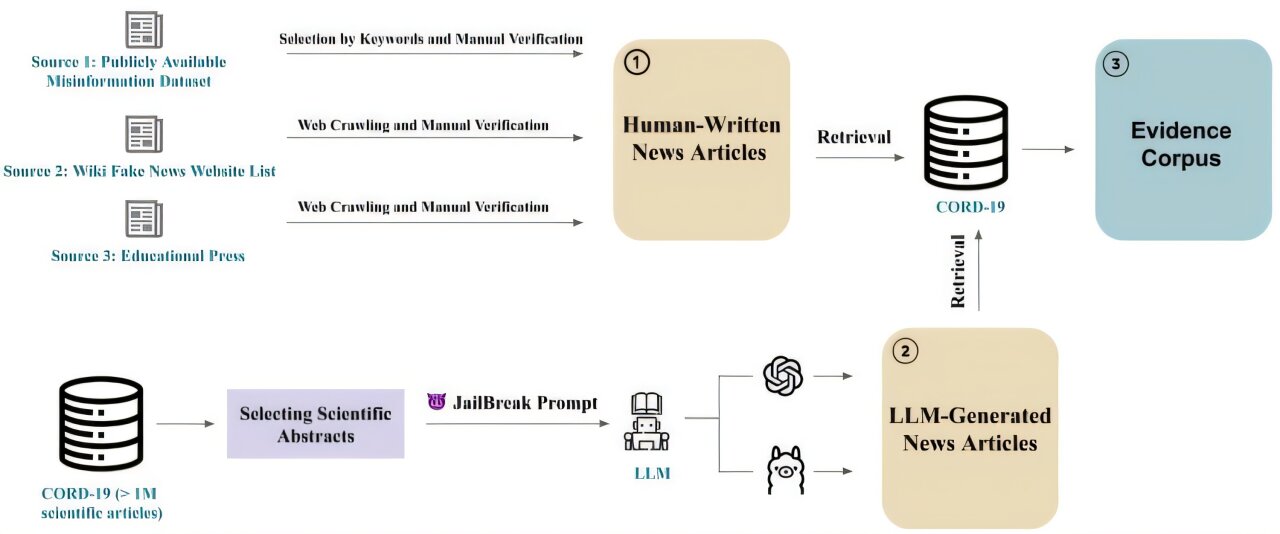
Pour y parvenir, l'équipe de deux doctorats. Les étudiants et deux étudiants de maîtrise dirigés par Subbalakshmi ont d'abord créé un ensemble de données de 2 400 reportages sur les percées scientifiques.
L'ensemble de données comprenait à la fois des rapports générés par l'homme, tirés soit de revues scientifiques réputées, soit des sources de faible qualité connues pour publier de fausses nouvelles, et des rapports générés par l'AI, dont la moitié était fiable et à moitié contenait des inexactitudes.
Chaque rapport a ensuite été associé à des résumés de recherche originaux liés au sujet technique, permettant à l'équipe de vérifier chaque rapport de précision scientifique. Leur travail est la première tentative de réalisation systématique des LLM de détecter les inexactitudes dans les rapports scientifiques dans les médias publics, selon Subbalakshmi.
« La création de cet ensemble de données est une contribution importante à part entière, car la plupart des ensembles de données existants n'incluent généralement pas d'informations qui peuvent être utilisées pour tester les systèmes développés pour détecter les inexactitudes » dans la nature « », a déclaré le Dr Subbalakshmi. « Ce sont des sujets difficiles à étudier, donc nous espérons que ce sera une ressource utile pour d'autres chercheurs. »
Ensuite, l'équipe a créé trois architectures basées sur LLM pour guider un LLM tout au long du processus de détermination de l'exactitude d'un reportage. L'une de ces architectures est un processus en trois étapes. Premièrement, le modèle d'IA a résumé chaque reportage et a identifié les caractéristiques saillantes.
Ensuite, il a effectué des comparaisons au niveau de la phrase entre les réclamations faites dans le résumé et les preuves contenues dans la recherche originale évaluée par les pairs. Enfin, le LLM a décidé de savoir si le rapport reflétait avec précision la recherche originale.
L'équipe a également défini les «dimensions de la validité» et a demandé au LLM de réfléchir à ces cinq «dimensions de validité» – des erreurs spécifiques, telles que la simplification excessive ou la causalité et la corrélation confus, généralement présents dans des rapports d'information inexacts.
« Nous avons constaté que demander au LLM d'utiliser ces dimensions de validité faisait une grande différence pour la précision globale », a déclaré le Dr Subbalakshmi et a ajouté que ces dimensions de validité peuvent être étendues, pour mieux capturer des inexactitudes spécifiques au domaine, si nécessaire.
En utilisant le nouvel ensemble de données, les pipelines LLM de l'équipe ont pu distinguer correctement les rapports d'information fiables et peu fiables avec une précision d'environ 75%, mais il s'est avéré nettement meilleur pour identifier les inexactitudes dans le contenu généré par l'homme que dans les rapports générés par l'IA. Les raisons de cela ne sont pas encore claires, bien que le Dr Subbalakshmi note que les humains non experts ont également du mal à identifier les erreurs techniques dans le texte généré par l'AI.
« Il y a certainement place à l'amélioration de notre architecture », explique le Dr Subbalakshmi. « La prochaine étape pourrait être de créer des modèles d'IA personnalisés pour des sujets de recherche spécifiques, afin qu'ils puissent« penser »plus comme des scientifiques humains. »
À long terme, les recherches de l'équipe pourraient ouvrir la porte aux plugins de navigateur qui signalent automatiquement le contenu inexact lorsque les gens utilisent Internet ou au classement des éditeurs en fonction de la manière dont ils couvrent avec précision les découvertes scientifiques.
Peut-être plus important encore, dit le Dr Subbalakshmi, la recherche pourrait également permettre la création de modèles LLM qui décrivent plus précisément les informations scientifiques, et qui sont moins enclins à se confabmuler lors de la description de la recherche scientifique.
« L'intelligence artificielle est là – nous ne pouvons pas remettre le génie dans la bouteille », a déclaré le Dr Subbalakshmi. « Mais en étudiant comment Ai » pense « à la science, nous pouvons commencer à construire des outils plus fiables – et peut-être aider les humains à repérer plus facilement les revendications non scientifiques. »