

Le pari de Mistral avec Small 4 est de faire plus avec moins de choses
La course à l’intelligence artificielle est souvent présentée comme une compétition visant à déterminer qui construit le modèle le plus puissant ou celui qui domine le plus les benchmarks. Au milieu de ce forum, la startup française Mistral AI vient de présenter Mistral Small 4, une proposition qui tente d'occuper une place différente dans cette conversation. Il n'est pas présenté comme un modèle limité à une seule fonction, mais comme un modèle qui, selon l'entreprise, cherche à rassembler plusieurs capacités avancées au sein d'un même outil.
Qu'est-ce que Small 4 exactement. L'entreprise le présente comme la nouvelle grande itération de sa famille Mistral Small et, surtout, comme le premier modèle de la maison qui rassemble des capacités auparavant réparties sur plusieurs lignes. Concrètement, il intègre les fonctions associées à Magistral, Pixtral et Devstral ainsi qu'à celles de la série Small elle-même.
Moins de modèles, plus de fonctions. L'une des idées centrales de l'annonce est de concentrer les tâches qui sont normalement résolues avec différents outils dans un seul système. Selon Mistral, l'objectif est qu'un même modèle puisse être utilisé pour converser, analyser des informations complexes, travailler avec des images ou aider à la programmation sans avoir à basculer entre plusieurs systèmes spécialisés.
Les chiffres derrière Small 4. Le modèle est basé sur une architecture Mixture of Experts, une conception qui répartit le traitement entre différents sous-modèles spécialisés et qui apparaît aujourd'hui dans plusieurs systèmes d'intelligence artificielle. Dans le cas de Small 4, Mistral indique que le système compte 128 experts et que seulement quatre participent à chaque jeton généré. Selon la société, le modèle atteint 119 milliards de paramètres au total, avec 6 milliards d'actifs par jeton, et offre une fenêtre contextuelle allant jusqu'à 256 000.
A qui est destiné ce modèle ? Au-delà de son architecture, Mistral décrit aussi assez clairement les scénarios dans lesquels il imagine l'utilisation du Small 4. Voyons voir.
- Développeurs : automatisez les tâches de programmation, explorez les bases de code et les flux de travail des agents de code
- Entreprises : assistants conversationnels, compréhension documentaire et analyse multimodale
- Recherche : mathématiques, tâches complexes d'analyse et de raisonnement
L'idée sous-jacente est que le modèle peut évoluer entre des besoins assez différents sans vous obliger à changer de système en fonction du type de travail.
Les graphismes. Dans le matériel accompagnant l'annonce, Mistral inclut plusieurs graphiques dans lesquels il compare le Small 4 avec d'autres modèles dans différents benchmarks. Ces comparaisons ne se limitent pas au score obtenu à chaque test. Ils montrent également la longueur moyenne des réponses générées par chaque système, une donnée que l'entreprise utilise pour illustrer la quantité de texte que chaque modèle doit produire pour obtenir certains résultats.
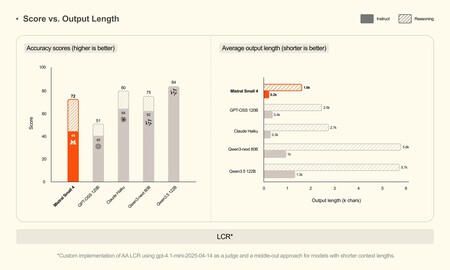
L'un des graphiques de l'annonce correspond au benchmark AA LCR, où Mistral compare les scores de différents modèles et la longueur moyenne des réponses qu'ils génèrent pour résoudre les mêmes tâches. Les données publiées par la société sont les suivantes :
• Mistral Small 4 : score de 0,72 avec 1 600 caractères
• GPT-OSS 120B : 0,51 avec 2 500 caractères
• Claude Haiku : 0,80 avec 2 700 caractères
• Qwen3-next 80B : 0,75 avec 5 800 caractères
• Qwen3.5 122B : 0,84 avec 5 700 caractères
La comparaison. Small 4 n’est pas le modèle le plus performant. Les modèles Claude Haiku et Qwen apparaissent tous deux plus élevés dans cet indicateur. Cependant, Mistral met en avant un autre aspect de la comparaison : la longueur des réponses. Selon la société, son modèle parvient à cette combinaison de score et de longueur de sortie en générant beaucoup moins de texte que plusieurs de ses concurrents, ce qui est lié à une latence plus faible et à un coût d'inférence inférieur.
L'astuce des réponses courtes. Une réponse plus courte n’est pas meilleure simplement parce qu’elle prend moins de place. Ce n'est que s'il parvient à résoudre la tâche avec un niveau de qualité comparable à celui d'une réponse plus longue. C’est là que Mistral tente de mettre l’accent : si un modèle obtient un résultat compétitif en générant moins de texte, il peut répondre plus rapidement, consommer moins de ressources et réduire le coût d’inférence. En d’autres termes, l’avantage n’est pas d’être plus concis, mais de nécessiter moins de production pour obtenir un résultat utile.

Comment accéder au nouveau modèle. Small 4 ne peut pas être utilisé uniquement via l'API et AI Studio. Publié sous licence Apache 2.0, il se présente également comme un modèle ouvert pouvant être téléchargé, ajusté et déployé dans vos propres environnements. La société ajoute qu'il peut être essayé gratuitement sur build.nvidia.com, en plus de le proposer en production sous le nom de NVIDIA NIM.
Images | Mistral
À Simseo | Cela fait des années qu'OpenAI veut être la mariée au mariage et le mort aux funérailles : elle a enfin défini sa priorité