
Le modèle d'IA qui s'apprend à réfléchir à des problèmes, aucun humain n'est nécessaire
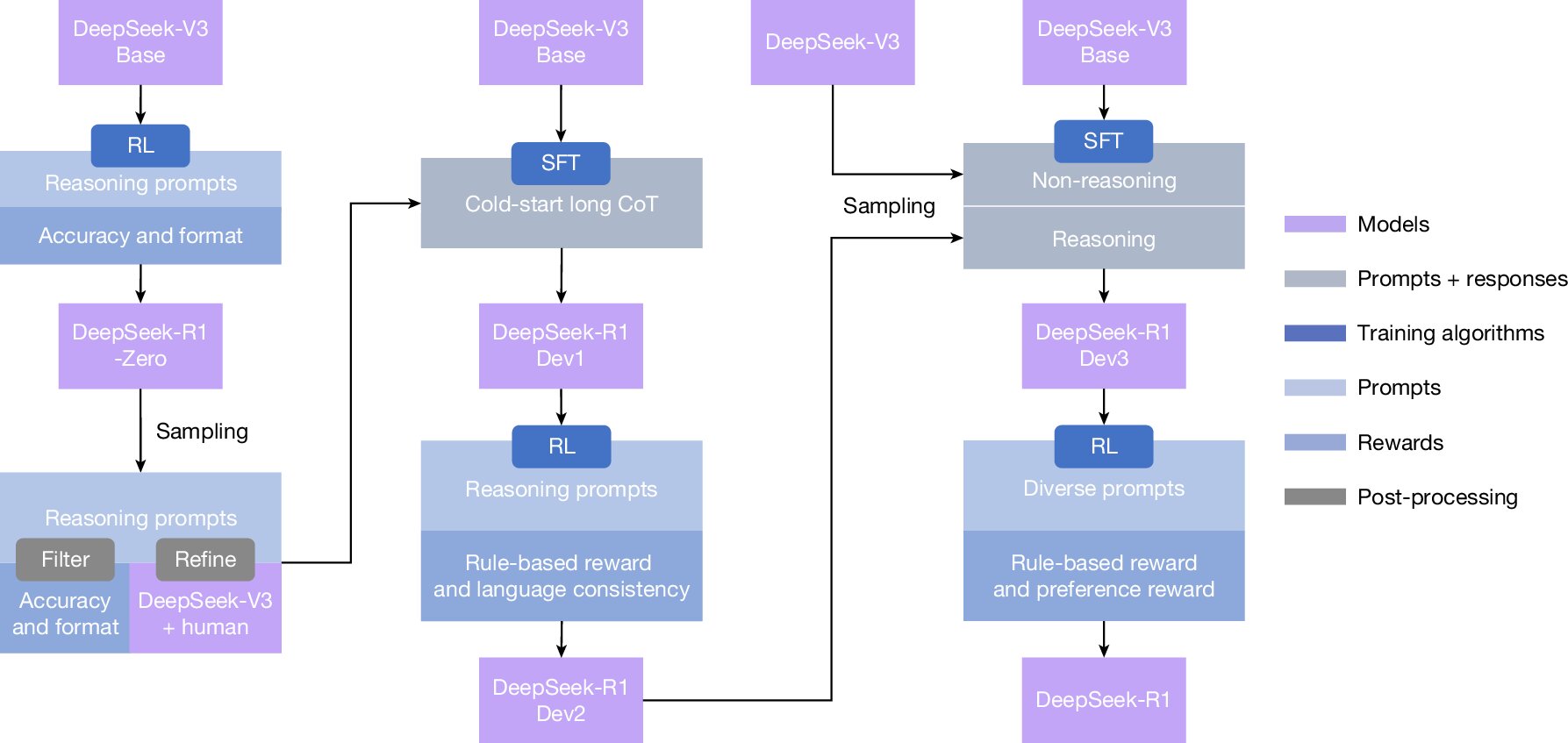
L'intelligence artificielle devient plus intelligente chaque jour, mais elle a toujours ses limites. L'un des plus grands défis a été l'enseignement des modèles d'IA avancés pour raisonner, ce qui signifie résoudre des problèmes étape par étape. Mais dans un nouvel article publié dans la revue Naturel'équipe de Deepseek AI, une entreprise chinoise de renseignement artificiel, rapporte qu'ils ont pu enseigner à leur modèle R1 à raisonner seul sans contribution humaine.
Lorsque beaucoup d'entre nous essaient de résoudre un problème, nous n'obtenons généralement pas la réponse immédiatement. Nous suivons un processus méthodique qui peut impliquer de collecter des informations et de prendre des notes jusqu'à ce que nous arrivions à une solution. Traditionnellement, la formation des modèles d'IA à la raison a impliqué la copie de notre approche. Cependant, il s'agit d'un processus long et réalisé où les gens montrent un modèle d'IA d'innombrables exemples de comment résoudre un problème. Cela signifie également que l'IA n'est aussi bonne que les exemples qu'il est donnés et peut reprendre les biais humains.
Au lieu de montrer le modèle R1 à chaque étape, les chercheurs de Deepseek IA ont utilisé une technique appelée apprentissage par renforcement. Cette approche d'essai et d'erreur, en utilisant des récompenses pour des réponses correctes, a encouragé le modèle à raisonner.
« Plutôt que d'enseigner explicitement au modèle comment résoudre un problème, nous lui fournissons simplement les bonnes incitations et il développe de manière autonome des stratégies de résolution de problèmes avancées », a écrit les chercheurs dans leur article.
Le modèle R1 de Deepseek a été formé sur des problèmes de mathématiques, de codage et de science difficiles. La seule récompense qu'il a reçue était un signal que sa réponse finale était correcte. Au cours de sa formation, les chercheurs l'ont vu développer des compétences telles que la vérification de son propre travail et l'exploration de différentes stratégies pour trouver une solution. Il a même commencé à utiliser des mots comme « attendre » en réfléchissant à son propre processus de réflexion. Si un chemin conduisait à la bonne réponse, cette stratégie a été renforcée. Si c'était faux, le modèle a appris à ne pas le répéter. Il y a eu une intervention humaine, mais uniquement pour polir les compétences de R1 plus tard dans le processus.
. Doi: 10.1038 / S41586-025-09422-Z")
Les résultats étaient impressionnants. R1 a mieux fonctionné sur les tâches de mathématiques, de codage et de science que les modèles plus anciens formés avec les conseils humains. L'un des résultats les plus remarquables a été qu'il a obtenu une précision de 86,7% sur l'American Invitational Mathematics Examination (AIME) 2024, un concours de mathématiques difficiles pour les élèves les plus intelligents du secondaire.
Même avec ces résultats exceptionnels, les chercheurs admettent que leur modèle a certaines limites à travailler. Par exemple, il a parfois mélangé des langues lorsqu'il est donné une invite non anglaise et a rendu certains problèmes simples plus compliqués qu'ils ne devaient l'être. Mais une fois ces problèmes résolus, les chercheurs croient qu'un modèle d'IA qui peut raisonner conduira à une nouvelle ère de modèles plus compétents et autonomes.
Écrit pour vous par notre auteur Paul Arnold, édité par Lisa Lock, et vérifié et révisé par Robert Egan – cet article est le résultat d'un travail humain minutieux. Nous comptons sur des lecteurs comme vous pour garder le journalisme scientifique indépendant en vie. Si ce rapport vous importe, veuillez considérer un don (surtout mensuel). Vous obtiendrez un sans publicité compte comme un remerciement.