
Le LLM basé sur l’apprentissage du programme montre les avantages du raisonnement étape par étape dans les systèmes d’IA
Une équipe de chercheurs en IA de l’Université d’IA Mohamed bin Zayed, à Abu Dhabi, en collaboration avec un collègue de l’Université de Floride centrale, a développé un LLM basé sur l’apprentissage du programme, appelé LlamaV-o1, qui, selon ses créateurs, montre les avantages de raisonnement étape par étape dans les systèmes d’IA. Dans leur étude, publiée sur le arXiv serveur de prépublication (et également sur GitHub), le groupe a construit son LLM avec un nouveau niveau de raisonnement étape par étape pour comprendre comment il arrive à ses réponses.
L’apprentissage par programme, en ce qui concerne l’IA, est une stratégie de formation par laquelle un LLM est progressivement exposé à des tâches plus complexes alors qu’il tente de résoudre un problème, de la même manière que les humains apprennent. Dans cette nouvelle étude, l’équipe d’Abu Dhabi a mis l’accent sur cette approche dans le cadre de la manière dont son LLM tente de répondre à une requête.
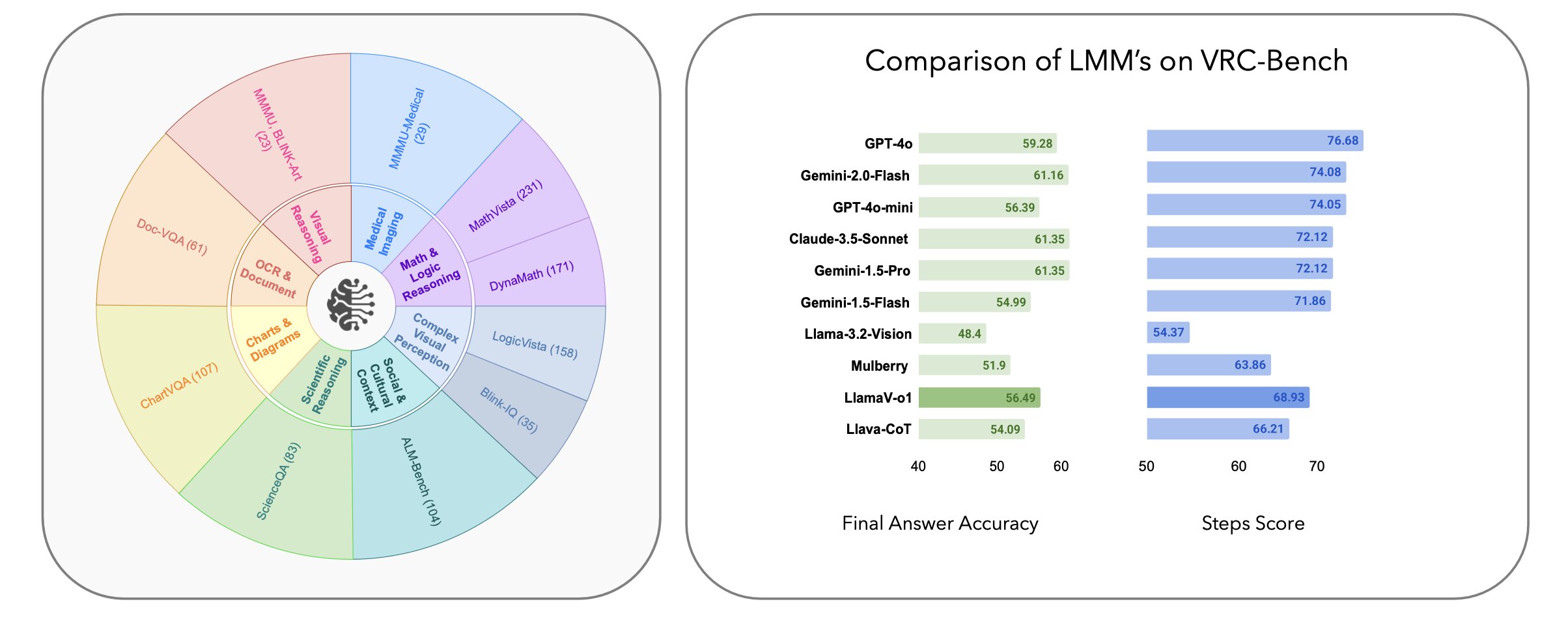
L’approche suit leur objectif global de rendre le processus par lequel un LLM arrive à une réponse plus transparent pour la personne qui a posé la question. Conformément à cet objectif, la même équipe a également publié VRC-Bench, qui, comme son nom l’indique, est une référence conçue pour tester les modèles d’IA sur la manière dont ils raisonnent pour résoudre un problème tout en cherchant une réponse. La principale différence entre VRC-Bench et les autres benchmarks actuellement utilisés réside dans l’accent mis sur le test des modèles d’IA en fonction de leur approche étape par étape de la résolution des requêtes.
L’une des caractéristiques de LlamaV-o1, note l’équipe, est qu’il décrit les étapes de raisonnement qu’il suit pour chercher une réponse. Cette fonctionnalité, suggèrent-ils, devient de plus en plus importante à mesure que les LLM et autres modèles d’IA sont déployés dans des applications critiques telles que la médecine et les prévisions financières. Suivre la logique contribue à renforcer la confiance dans la réponse finale ou met en évidence le moment où une erreur se produit.
Une autre fonctionnalité est l’utilisation de Beam Search, qui est un type d’algorithme de décodage utilisé avec les LLM pour générer un texte cohérent et contextuellement approprié. Dans ce cas, cela permet à LlamaV-o1 de générer plusieurs chemins de raisonnement et de sélectionner celui le plus approprié pour répondre à la requête d’origine, ce qui entraîne une précision améliorée.