
Le framework AI d’inspiration neuro-inspirée utilise l’apprentissage des commandes inverses pour améliorer la génération de code
Les modèles de grands langues (LLM), tels que le modèle derrière la plate-forme populaire de Chatgpt d’Openai, s’attaquent à une large gamme de tâches de traitement des langues et de génération de texte. Certains de ces modèles ont également montré une certaine promesse pour la génération de code de programmation, en particulier lorsqu’ils sont déployés dans des ensembles dans le cadre de systèmes dits multi-agents.
Des chercheurs de l’Université de Jilin et de l’Université des sciences et de la technologie de Hong Kong ont récemment développé Cogito, un nouveau système multi-agents qui pourrait améliorer la génération automatisée et basée sur l’IA du code de programmation. Ce système, présenté dans un article publié sur le arxiv Preprint Server, s’inspire des processus neurobiologiques qui permettent aux humains de terminer des tâches complexes étape par étape, suivant une approche structurée.
« Sous la direction de l’auteur correspondant, le professeur Wang Qi, nous avons décidé de concentrer nos recherches sur les tâches de génération de code de LLM-Agent », a déclaré à Tech Xplore Yanlong Li, premier auteur du journal. « La psychologie et le processus de croissance humaine nous ont inspirés à terminer cette recherche, et les résultats ont été assez prometteurs. »
L’objectif principal des travaux récents du professeur Qi, Li et leurs collègues était d’améliorer les performances des LLM sur les tâches de génération de code de programmation. Pour ce faire, les chercheurs ont développé un nouveau système qui inverse la séquence typique dans laquelle des sous-tâches de génération de code sont effectuées.
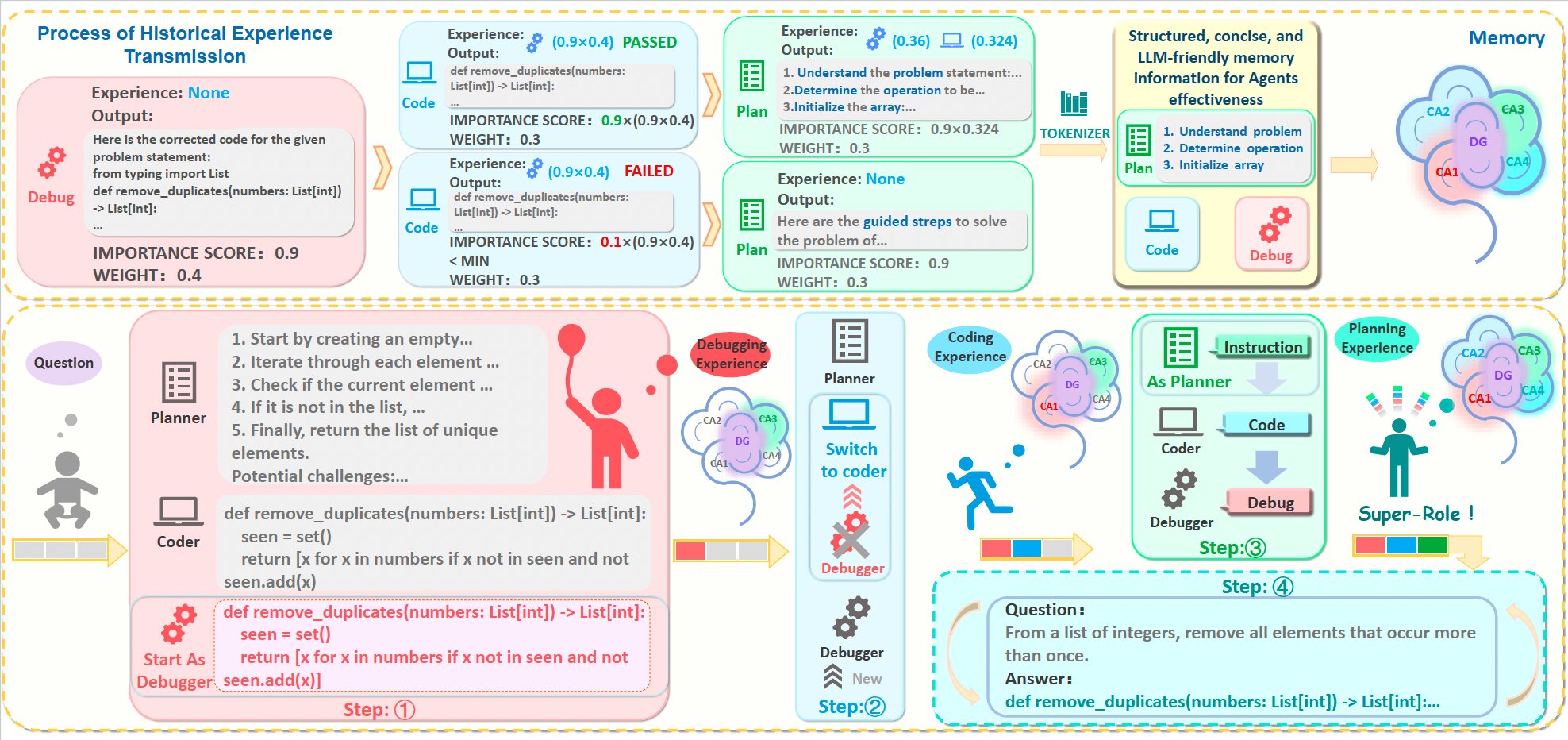
En règle générale, la génération de code de programmation commence par la planification (c’est-à-dire la structuration de la logique globale du code), suivie du processus de codage et du dégraissant (c’est-à-dire de fixer des erreurs dans le code). Le nouveau cadre développé par ce groupe de recherche inverse cette séquence, à partir du débogage, pour produire ensuite du code et planifier par la suite des changements visant à le raffiner.
« Notre cadre se compose d’un processus de génération de réponses et d’un module de mémoire », a expliqué Li. « Pour une tâche donnée, il y a trois rôles dans le groupe: le planificateur, le codeur et le débogueur, chacun exécutant leurs fonctions respectives pour générer la réponse. Le rôle responsable de la génération de la réponse finale jouera séquentiellement les rôles du débogueur, du codeur et Planificateur dans différents groupes. «
Cogito, le système développé par Li et ses collègues, présente également un module de mémoire qui reflète le fonctionnement de l’hippocampe, une région clé du cerveau humain. Ce module est conçu pour récupérer rapidement les informations acquises dans le passé, pour améliorer le processus d’apprentissage.
Essentiellement, Cogito accumule l’expérience tout en terminant la phase de débogage, de codage et de planification. Par la suite, il tire parti de l’expérience qu’elle a accumulée pour générer une version finale du code de programmation demandé.
« La caractéristique unique du processus est l’utilisation de l’accumulation de l’expérience et de l’apprentissage par ordre inverse (où l’ordre typique est le planificateur, le codeur, le débogueur pour l’apprentissage) », a déclaré Li. « Cette approche permet d’économiser les coûts de communication entre les groupes et améliore la précision des tâches.
« Quant à la mémoire, il est inspiré par l’hippocampe du cerveau humain, où différentes régions stockent des informations sur la base de différentes fonctions, avec une interconnexion entre eux. Cette conception permet à la fois une récupération rapide et une observation du processus global, contrairement à la plupart des œuvres précédentes qui, soit les deux, soit les deux travaux qui, soit Stockez les informations dans son ensemble ou résumez avant de stocker. «
Les chercheurs ont testé leur système multi-agents proposé dans une série d’expériences initiales et ont constaté qu’il a surpassé les modèles basés sur LLM existants sur les tâches de génération de code, faisant moins d’erreurs. À l’avenir, le modèle pourrait être amélioré davantage et testé sur une gamme plus large de tâches de génération de code.
« Je pense que l’aspect le plus notable de notre étude est le processus d’apprentissage inverse et de croissance que nous avons démontré », a ajouté Li. « Jusqu’à présent, nous avons validé son efficacité dans les tâches de génération de code comme Humaneval. À l’avenir, nous pourrions incorporer certains éléments d’apprentissage du renforcement, mais nous ne sommes pas encore entièrement certain, car ce domaine se développe très rapidement. »