

Le débat sur la quantité de prudence vraiment son AI
5 576 millions de dollars. C’est ce que les créateurs Deepseek V3 affirment qu’ils ont été dépensés pour la formation complète de ce surprenant modèle d’IA. Ils le montrent clairement dans leur rapport technique officiel, qui nous explique comment ils ont utilisé 2 788 millions d’heures de GPU (NVIDIA H800) pour le terminer.
Le croyons-nous? Les comptes leur viennent, bien sûr, mais qu’en est-il du reste du monde? C’est le débat ouvert depuis que ce week-end a explosé la nouvelle du lancement de Deepseek-R1. Ce modèle de raisonnement, dérivé de Deepseek V3, vous concourt de vous avec Openai O1, et qu’il a tellement de choses pour si peu d’entreprises telles que NVIDIA perdent 400 000 millions de dollars en une seule journée en bourse.
Difficile à croire. La question est de savoir si nous pouvons faire confiance aux chiffres que Deepseek offre. Ben Thompson a essayé d’offrir de la lumière à cet égard et a rappelé que dans le rapport technique Deepseek V3, leur responsable décompose le coût de la formation, mais clarifiez quelque chose d’important. Les 5 576 millions de dollars n’incluent pas « les coûts associés aux enquêtes et expériences précédentes dans les architectures, les algorithmes ou les données ».
L’opinion des analystes. Ben Thompson indique dans Stratechery que cela montre clairement que l’on ne peut pas prendre 5,6 millions de dollars et reproduire ce que Deepseek a fait, mais cela ajoute également que « je ne crois toujours pas ce nombre ». D’autres analystes tels que Nathan Lambert, qui dans son bulletin d’interconnexion, ont également débattu à ce sujet.
Il y avait (bien sûr) des dépenses antérieures. Comme expliqué dans Financial Times, il existe d’autres analystes qui doutent également que les données internes en profondeur. Dylan Patel, de la semianalyse, soutient selon les nominations du journal économique que DePseek a eu accès à « des dizaines de milliers » de GPU NVIDIA qui ont été utilisés pour former les modèles qui ont précédé R1.
Mais cela se produit avec d’autres modèles. « Deepseek a clairement dépensé plus de 500 millions de dollars en GPU dans son histoire », a déclaré Patel, « et bien que sa formation ait été très efficace, il a nécessité beaucoup d’expérimentation et de tests pour fonctionner. » C’est une note intéressante, bien qu’il soit également vrai que de nombreuses autres entreprises dépensent des centaines et même des milliards de dollars d’infrastructures pour former leurs modèles et les offrir aux utilisateurs.
Et pas si transparent. Ces 5,6 millions de dollars ne reflètent pas non plus des dépenses supplémentaires telles que celles qui devaient sûrement être supposées lors de l’adaptation de Deepseek V3 – qui est la base – à Deepseek R1. On ne parle pas de salaires, de travail dans l’annotation des données afin qu’ils soient de qualité pour la formation, ou dans d’éventuels processus de formation incomplets ou que pour une raison quelconque, ils ont été interrompus et échoués.
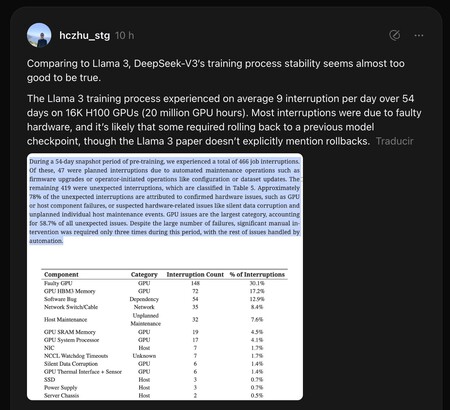
Comparaison avec Flame 3. Un chercheur So-Salled Praneet Rathi (@pseuddd) a publié une analyse très étendue et détaillée du coût de Deepseek V3 671b (avec 37b des actifs, ce qui réduit les besoins pour le former) et l’a comparé à la flamme 3, de finir. Cela indique comment il appelle le 405B, il avait besoin de 30 millions d’heures de GPU, contre 2,8 millions de ceux qui parlent à Deepseek.
Ce n’est peut-être pas. Ici, il a estimé que 1 H800 Hour (plus limité que H100) utilisé dans Deepseek V3 était équivalent à environ 0,75 heures de H100 utilisé dans Flame 3, et après avoir fourni beaucoup plus de données (comme utiliser uniquement l’apprentissage pour le renforcement et la précision FP8, qui sauve Beaucoup de ressources) leurs données semblaient soutenir la thèse selon laquelle le coût de Deepseek est celui qui prétend être. D’autres commentaires avec des arguments similaires dans Reddit semblent également donner de la crédibilité aux chiffres publiés par la startup chinoise. Bien sûr, il est impossible de savoir avec certitude et d’autres utilisateurs commentent des threads car cette comparaison « est trop belle pour être vrai ».
Mais il devient moins cher de former des modèles. La vérité est que l’infrastructure est de plus en plus puissante et les processus les plus efficaces. Non seulement pour Deepseek, mais pour tout le monde. Une analyse récente a estimé que la formation GPT-4 au début de 2023 avait coûté environ 63 millions. Au troisième trimestre de 2023, ce coût aurait été de 20 millions de dollars, et il est raisonnable de penser qu’aujourd’hui ce processus aurait été encore moins cher. Il serait intéressant de savoir ce qu’ils diraient dans Openai de cette estimation.
Est-il possible de reproduire Deepseek R1? Le fait Deepseek-R1 est un modèle open source et que les responsables ont donné tant de données sur la façon dont ils ont réussi à développer ce modèle ouvre la porte à d’autres pour prendre le témoin et développer des modèles similaires, puis les améliorer. C’est précisément ce que le projet Open-R1 dont les participants avancent toujours qu’il y a encore des pièces du puzzle manquant, telles que les données utilisées pour la formation ou avec les « hyperparamètres » qui ont formé le modèle.
Image | Taylor Vick
Dans Simseo | La prochaine phase de l’IA n’est pas de voir qui investit plus mais qui investit moins