

La technologie gaspille une fortune dans de grands modèles d'IA. Les petits gagnent le jeu
L'IA ne semble pas avancer beaucoup. Au moins la « grande » AI. Les meilleurs modèles de marché sont à peine gérés à faire des sauts qualitatifs pertinents, et cela, bien qu'il soit gigantesque et de l'argent, du temps et des talents que les entreprises investissent dans leur création. Nous l'avons vu avec Flame 4, Claude 4 ou le GPT-5 récent (et décevant). Mais alors que les modèles gigantesques esots sont de moins en moins surprise, les modèles Diminutos deviennent de plus en plus. Quelque chose (petit) bouge.
Google Moves déposer Fichita la semaine dernière, Google nous a tous surpris avec le lancement d'un petit modèle d'IA. Eh bien, pas: minuscule. On pourrait presque dire que c'est un « nanomodel ». Gemma 3 270m est une version extrêmement compacte avec seulement 270 millions de paramètres. À quel point est-ce petit? Il est facile de comprendre lorsque nous comparons ce modèle avec l'un des modèles open source les plus réputés:
- Appel 4: Dans sa version du géant, 288b (1 066 fois plus grand)
- Qwen 3 235b (870 fois plus grand)
- Deepseek R1 671B (2485 fois plus grand)
Un modèle hydratant. Les propres de Google ont clairement indiqué que ce modèle ne peut pas rivaliser avec les grands modèles d'IA, mais ce n'était pas leur objectif. Son objectif est d'être hyperffictif et, à l'attention, hyperspécifique. Ce qui est poursuivi ici est de transformer Gemma 3 270m en pilier de nombreux modèles adaptés à des tâches très spécifiques et en béton.
Le secret est appelé ajustement fin. Gemma 3 270m, insisté sur le fait que ces ingénieurs, sont un modèle parfait pour les processus de réglage fin (réglage fin) dans des tâches très spécifiques. Une entreprise (ou un développeur) n'importe qui peut prendre un petit modèle, comme celui-ci, et le former avec ses propres données et les affiner pour une tâche spécifique en suivant les instructions de Google pour étreindre le visage. Par exemple, pour générer des histoires pour lire les enfants la nuit (code), pour convertir le texte confus en données structurées, pour personnaliser les messages, pour classer les e-mails ou prendre en charge les billets, ou même pour jouer aux échecs de manière décente.
Petits modèles à alimenter. Google a déjà opté pour ce type de petits modèles lorsqu'il a présenté Gemma 3 en mars. À cette époque, les versions présentées étaient 1b, 4b, 12b et 27b, étant la dernière vraiment « géniale » en termes absolus. Le reste pourrait être exécuté dans des machines locales avec 16 Go de mémoire graphique, comme un Mac Mini M4. C'est précisément ce que nous pourrions vérifier auprès de GPT-ASS-20B (le téléchargement est d'environ 12 Go), le modèle open source récemment lancé par OpenAI qui s'est comporté remarquablement. Mais même ce dernier pourrait être considéré comme « génial », et ces dernières semaines et mois, nous avons vu de plus en plus de modèles « minuscules » qui encouragent le marché.
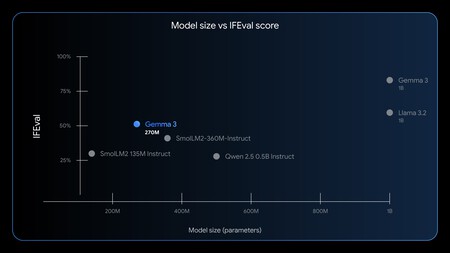
La performance de Gemma 3 270m est surprenante malgré sa petite taille. Et pourtant, le meilleur de tous n'est pas cela: c'est sa capacité à l'adapter à une tâche spécifique.
Exemples partout. Microsoft a déjà opté pour ce type de modèles avec PHI-3 et PHI-4 (14b), qui, dans son lancement, était en concurrence avec le modèle chinois QWEN-2.5-14B, bien que ces modèles aient essayé de proposer des alternatives « mini » à de grands modèles tels que GPT-4O ou Call-3.3 70b. Ils pouvaient être utilisés pour un ajustement fin, mais ils étaient déjà formés pour s'adapter à divers scénarios. D'autres, plus inconnus, sont allés plus loin: le Liquid Startup a lancé un modèle destiné aux environnements visuels appelés LFM2 avec seulement 440 m de paramètres, et NVIDIA vient de lancer Nemotron -Nano-9B, qui parvient à améliorer les performances de QWEN3-8B dans divers benchmarks.
Parfait pour les mobiles et les montres intelligentes. Un autre avantage de ces modèles est que grâce à leur petite taille peut fonctionner sur de nombreux autres appareils, mais modestes. Ils sont idéaux pour pouvoir être utilisés par exemple dans nos mobiles, nos montres intelligentes ou des produits encore plus limités. Son efficacité est l'ordre du jour: comme Google l'a souligné, dans un Pixel 9 Pro, une version quantifiée (INT4) de Gemma 3 270m peut gérer 25 « conversations » (chats) en utilisant seulement 0,75% de la batterie mobile. Il est si petit qu'il peut même être exécuté dans un onglet de navigateur comme si nous chargeons un site Web (lourd) plus, comme l'exemple de l'application Web qui génère des histoires de couchage aux enfants ou à celle qui nous montre comment le modèle commence à se séparer, mais de manière amusante et dont le code est disponible.
Un avenir prometteur. Le modèle Google, comme des similaires, soulève cet autre côté que Google a parlé. Plus qu'un modèle hors route, ce qu'ils offrent est une base sur laquelle construire « le bon outil pour le travail ». Ces types de petits modèles, bien raffinés et formés, peuvent être à la base de la conception de tous les types de petites applications et d'agents d'IA qui finissent ensuite par l'interconnexion et cette fonction très, très efficacement. Il était peut-être vrai que les meilleures essences sont vendues dans de petites bouteilles.
Image | Amanz
Dans Simseo | Si la question est laquelle des grandes technologies gagne la carrière de l'IA, la réponse est: aucune