

La Chine n'est plus composée de s'éloigner de Nvidia. Sa prochaine étape est le cœur de l'IA avec un système qui brise les moules
En 2017, l'article «l'attention est tout ce dont vous avez besoin» de Google a changé la base technique de la génération de langues: les transformateurs ont permis de traiter de longues séquences dans des modèles parallèles et de grimper à des tailles auparavant impossibles. Cette route d'escalade a motivé des architectures telles que GPT et Bert et a transformé l'auto-arrangement en pièce maîtresse de l'IA générative contemporaine.
Mais cette nouvelle approche s'est accompagnée de coûts croissants dans la mémoire et l'énergie lorsque le contexte s'allonge, une limitation qui a motivé la recherche à développer des alternatives. SPIKINGBRAIN-1.0 vise à briser les moules.
De « l'attention est tout ce dont vous avez besoin » pour le cerveau: le nouvel engagement à rompre les limites dans le
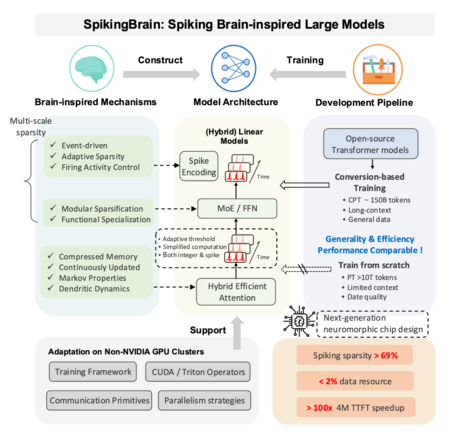
Une équipe de l'Académie chinoise des sciences automatisation vient de présenter Spikingbrain-1.0. Nous parlons d'une famille de modèles épineux visant à réduire les données et le calcul nécessaires pour les tâches avec des contextes très longs. Les experts proposent deux approches: SPIKINGBRAIN-7B, de l'architecture linéaire axée sur l'efficacité, et Spikingbrain-76B, qui combine l'attention linéaire avec le mélange d'experts (MOE) de plus grande capacité.
Les auteurs détaillent qu'une grande partie du développement et des tests ont été effectuées en grappes de GPU Metax C550, avec des bibliothèques et des opérateurs spécialement conçus pour cette plate-forme. Cela fait du projet non seulement une avance prometteuse au niveau du logiciel, mais également une démonstration de capacités matérielles appropriées. Un aspect particulièrement pertinent si les efforts de la Chine sont pris en compte pour réduire sa dépendance à l'égard de Nvidia, une stratégie que nous avons déjà vue avec Deepseek 3.1.

SPIKINGBRAIN-1.0 est directement inspiré par le fonctionnement de notre cerveau. Au lieu d'avoir des neurones qui sont toujours « brûlants » en calculant les nombres, utilise des neurones épineux: des unités qui accumulent les signaux jusqu'à ce qu'ils dépassent un seuil et déclenchent un pic (pic). Entre le pic et le pic, ils ne font rien, ce qui sauve les opérations et, en théorie, l'énergie. La clé est que non seulement peu importe le nombre de pics, mais lorsqu'ils se produisent: le moment exact et l'ordre de ces pics transportent des informations, comme dans le cerveau.
Pour que cette conception fonctionne avec l'écosystème actuel, l'équipe a développé des méthodes qui convertissent les blocs d'auto-agitation traditionnels en versions linéaires, plus faciles à intégrer dans son système épineux et ont créé une sorte de «temps virtuel» qui simule les processus temporaires sans freiner les performances dans GPU. De plus, la version Spikingbrain-76b comprend un mélange d'experts (MOE), un système qui « éveille » uniquement certains sous-modèles lorsque nous avons besoin, que nous avons également vus dans GPT-4O et GPT-5.
Les auteurs suggèrent des applications où la longueur du contexte est décisive: analyse de grands dossiers juridiques, dossiers médicaux complets, séquençage d'ADN et ensembles de données expérimentaux massifs en physique à haute énergie, entre autres. Cette dentelle semble raisonnée dans le document: si l'architecture maintient l'efficacité dans des contextes de millions de jetons, réduirait les coûts et les possibilités ouvertes dans des domaines aujourd'hui limités par l'accès à une infrastructure informatique très coûteuse. Mais la validation dans des environnements réels est en attente en dehors du laboratoire.

L'équipe a publié dans GitHub le code de la version de 7 000 millions de paramètres à côté d'un rapport technique détaillé. Il propose également une interface Web similaire à Chatgpt pour interagir avec le modèle, qui, selon les auteurs, est entièrement déployé dans le matériel national. L'accès, cependant, est limité aux Chinois, ce qui complique son utilisation en dehors de cet écosystème. La proposition est ambitieuse, mais sa véritable portée dépendra de la communauté pour reproduire les résultats et faire des comparaisons dans des environnements homogènes qui évaluent la précision, les latences et la consommation d'énergie dans des conditions réelles.
Images | Simseo avec Gemini 2.5 | Abodi Vesakaran
Dans Simseo | Openai pense avoir découvert pourquoi l'IAS hallucine: ils ne savent pas dire « je ne sais pas »