

GPT-4V comment est réalisé le modèle IA de la multimodalité ChatGPT
ChatGPT est alimenté par une multitude de systèmes sous-jacents, dont le plus récent est GPT-4V, ou Vision GPT-4, ce qui lui confère des capacités multimodales. Après la publication du modèle fin septembre, des chercheurs de Microsoft, principal investisseur et partenaire d’OpenAI, ont effectué une série de tests pour évaluer ses capacités. Ils ont constaté qu’il présente « des capacités remarquables, dont certaines n’ont pas été étudiées ou démontrées dans les approches existantes », selon l’article « The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) ».
Le GPT-4V est décrit comme un modèle « puissant » avec une « capacité sans précédent à traiter des entrées multimodales arbitrairement entrelacées ».
Qu’est-ce que GPT-4V
GPT-4V(ision) est un modèle d’IA multimodal développé par OpenAI. Il permet aux utilisateurs de ChatGPT de poser des questions sur une image téléchargée, un processus appelé réponse visuelle aux questions (VQA). À partir d’octobre, les fonctionnalités GPT-4V sont accessibles via ChatGPT sur la version de bureau ou de l’application iOS pour les abonnés ChatGPT Plus (20 $ par mois) ou Enterprise.
Ce que GPT-4V peut faire
GPT-4V peut analyser du texte et des images entrelacées.

De plus, il peut lire les points saillants des images, y compris les chiffres d’un tableau.

Il peut analyser des images médicales.
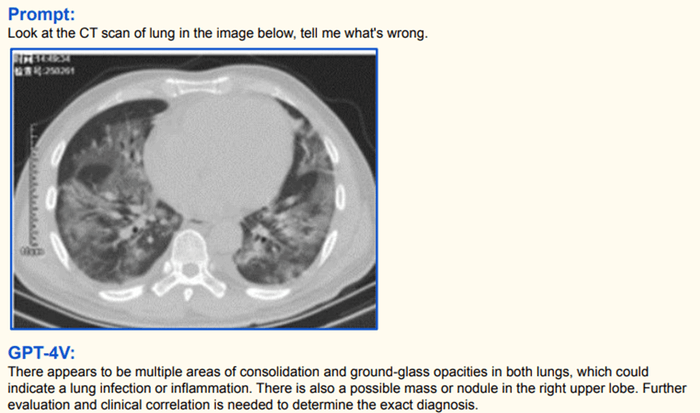
Il est capable d’identifier et de décrire le contenu des images.
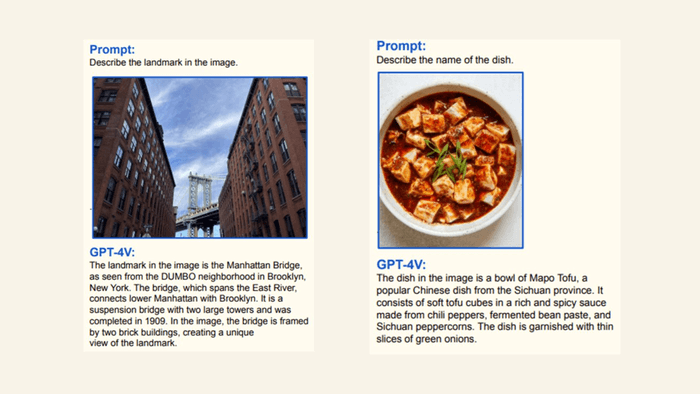
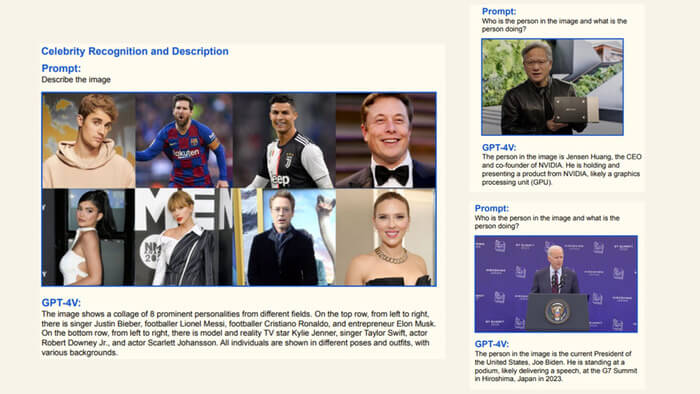
Le modèle peut également comprendre des scènes, telles qu’une vue d’une route depuis la caméra du tableau de bord d’une voiture, et répondre à des questions à leur sujet. Peut identifier correctement des personnes célèbres.
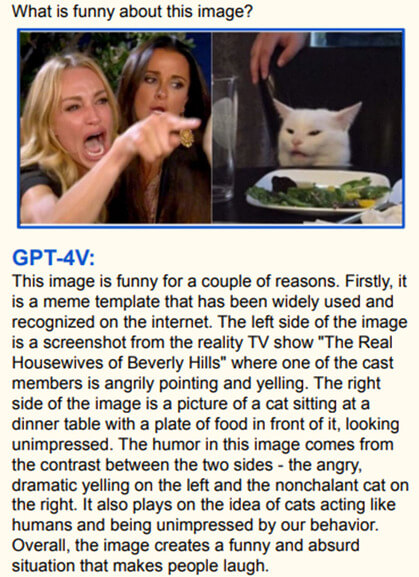
Cela peut expliquer l’humour des mèmes.
Le modèle est également capable de générer des descriptions détaillées et cohérentes du contenu des images, allant au-delà de simples étiquettes. Montre la capacité de raisonner de manière compositionnelle, par exemple en répondant à des questions en identifiant des preuves visuelles pertinentes.
Les principales caractéristiques du GPT-4V
Les principales caractéristiques du GPT-4V sont les suivantes :
Raisonnement visuel: Le modèle peut comprendre les relations visuelles et les nuances contextuelles au-delà du simple étiquetage des objets. Il peut répondre à des questions en raisonnant sur une image, gérer des contrefactuels et de nouveaux scénarios.
Suivez les instructions: Le modèle peut suivre des instructions textuelles pour effectuer de nouvelles tâches en langage visuel sans mettre à jour les paramètres.
Apprendre en contexte: Le GPT-4V a une capacité de apprentissage Dans le contexte quelques clichésc’est-à-dire qu’il est capable de s’adapter à de nouvelles tâches avec peu de démonstration au moment des tests.
Référence visuelle: Le modèle comprend des pointeurs visuels tels que des flèches et des cases directement superposés sur les images pour suivre les instructions.
Légendes denses: GPT-4V génère des descriptions détaillées en plusieurs phrases du contenu des images et de leurs relations.
Compter: Le GPT-4V peut compter les instances d’objets dans une image en fonction d’une requête.
Codage: Le modèle démontre la capacité à générer du code (par exemple, analyse JSON) conditionné par une entrée visuelle.
Selon les scientifiques de Microsoft, le modèle a considérablement amélioré la vision et la compréhension du langage par rapport aux modèles multimodaux précédents.
Quelles sont les limites de GPT-4V
Comme tous les modèles d’IA qui l’ont précédé, GPT-4V a ses limites.
Par exemple, ceux qui espèrent l’utiliser pour des cas d’utilisation manifestement complexes peuvent avoir du mal à faire en sorte que le système réponde à des demandes spécifiquement conçues.
Les performances du GPT-4V peuvent ne pas se généraliser à des échantillons nouveaux ou inconnus, et certains cas complexes peuvent ne fonctionner qu’avec des invites spécialement conçues.
L’essor des grands modèles multimodaux (LMM)
Les modèles d’IA multimodaux représentent la prochaine étape dans l’évolution de l’IA. Les modèles de génération de texte sont désormais enrichis de la capacité d’interagir avec une plus grande polyvalence à travers la multimodalité, en particulier la vision, car l’utilisation d’une image comme invite permet à l’utilisateur d’interroger plus facilement le modèle au lieu d’expliquer maladroitement un problème.
Un ChatGPT intelligent et multimodal rapproche OpenAI de la création d’une intelligence générale artificielle (AGI), qui est l’objectif ultime de la startup et le Saint Graal de la communauté de l’IA depuis des décennies. OpenAI a déclaré vouloir développer une intelligence artificielle générale bénéfique et sûre pour l’humanité – les gouvernements élaborent des réglementations pour garantir cela.
OpenAI n’est pas le seul à rechercher l’IA multimodale. L’armée de chercheurs de Meta, dirigée par le lauréat du prix Turing Yann LeCun, a publié des modèles d’IA multimodaux pour alimenter la vision de l’entreprise de créer un univers métaverse pour tous. Des noms comme SeamlessM4T, AudioCraft et Voicebox contribueront à concrétiser la vision de LeCun selon laquelle la multimodalité offrira un avantage aux utilisateurs d’IA qui souhaitent être créatifs mais manquent de compétences techniques.
Les modèles multimodaux sont également au centre de la recherche sur les modèles de base de nouvelle génération au sein du Frontier Model Forum récemment créé, composé des principaux développeurs d’IA, notamment OpenAI, Microsoft, Google et Anthropic.