

Google propose une nouvelle méthode permettant à l’IA de consommer beaucoup moins de mémoire. Mauvaise nouvelle pour Micron et SK Hynix
Nous sommes plongés dans une crise de mémoire depuis des mois, mais il existe peut-être une issue. La semaine dernière, Google Research a publié une étude révélant une technique appelée TurboQuant. Il s’agit d’un algorithme de compression capable de compresser la mémoire de travail des modèles d’IA jusqu’à six fois sans perte appréciable de qualité ou de performances. Excellente nouvelle pour les utilisateurs finaux, qui voient une lumière au bout du tunnel, mais terrible nouvelle pour les constructeurs, pour qui cet âge d’or pourrait prendre fin.
Expliquons ce qu’est le cache KV. Pour comprendre TurboQuant, vous devez comprendre quelle est cette mémoire qu’il parvient à compresser. Lorsqu’un modèle de langage traite une longue conversation, il doit se souvenir du contexte. Chaque jeton traité est stocké dans ce que l’on appelle le cache KV, un type de mémoire de travail qui augmente au fur et à mesure que nous discutons. Plus la conversation est longue, plus le modèle nécessite de mémoire.
Compresser ce qu’est un gérondif. C’est l’un des principaux goulots d’étranglement dans la phase d’inférence de l’IA (c’est-à-dire lorsque nous utilisons les modèles), et l’une des raisons pour lesquelles les centres de données ont besoin d’autant de RAM ou de mémoire HBM. TurboQuant utilise une méthode de quantification vectorielle pour compresser ce cache tout en conservant la précision du modèle.
Joueur de flûte à tarte. Dès la parution de cette étude de Google, les analogies avec l’intrigue de la série « Silicon Valley » ont commencé. Dans ce document, la startup fictive de l’intrigue a réussi à développer un algorithme de compression extraordinairement efficace appelé Pied Piper qui menaçait de révolutionner l’industrie technologique. Ces jours-ci, de multiples références à la série sont apparues sur les réseaux sociaux, déjà qualifiés de visionnaire pour refléter ce qui se passe avec une précision spectaculaire, même lorsque la série était une comédie.
Six fois moins de mémoire. Le document de recherche de Google indique que cette méthode est capable de réduire le cache KV six fois sans différence de performances appréciable lors de longues conversations. Les chercheurs présenteront leurs résultats lors d’un événement le mois prochain et expliqueront les deux méthodes qui permettent de les mettre en pratique. S’ils confirment ce qu’ils ont déjà avancé, les implications sont énormes : moins de mémoire pour l’inférence signifie que les centres de données peuvent faire la même chose avec beaucoup moins de matériel/de mémoire.
Le moment DeepSeek de Google. Cette découverte a amené certains analystes à qualifier cela de « moment DeepSeek » de Google. Il y a un an, la startup chinoise DeepSeek lançait un modèle d’IA qui rivalisait avec les meilleurs mais qui coûtait bien moins cher à développer. Cela a ébranlé l’industrie, et nous revenons maintenant à une prouesse technique qui va dans le même sens. En IA, il est crucial de faire la même chose avec moins, compte tenu des énormes ressources que nécessite cette technologie. Certains ont déjà fait des tests préliminaires avec TurboQuant et ont confirmé que la méthode fonctionne effectivement.
Micron, Samsung et SK Hynix le paient cher. L’impact de cette technique peut être énorme, et cela commence déjà à se constater dans les valorisations boursières des fabricants de mémoires DRAM et de HBM. Des sociétés comme Micron, Samsung, SK Hynix, SanDisk et Kioxia ont sensiblement chuté la semaine dernière par rapport à leurs récents sommets. Le 18 mars, il était d’environ 471 dollars et aujourd’hui, ses actions se situent à 357 dollars, soit une baisse stupéfiante de 24,2 %. La même chose s’est produite avec le reste des constructeurs, qui étaient déjà en baisse depuis cette date, mais ont accéléré cette chute avec le lancement de TurboQuant.
Mais. La technique ne peut théoriquement s’appliquer qu’à la phase d’inférence, mais la phase d’entraînement des modèles d’IA n’est pas affectée par cette technique de compression. Par conséquent, d’énormes quantités de mémoire seront encore nécessaires pendant la phase d’entraînement. De plus, nous devrons attendre que les entreprises d’IA commencent réellement à appliquer ce système s’il s’avère efficace, et ce sera à ce moment-là que nous pourrons voir le véritable impact. Théoriquement, cela donnera une grande marge de manœuvre aux grandes technologies, qui pourront réduire encore davantage les prix des jetons, mais il reste à voir si elles le feront.
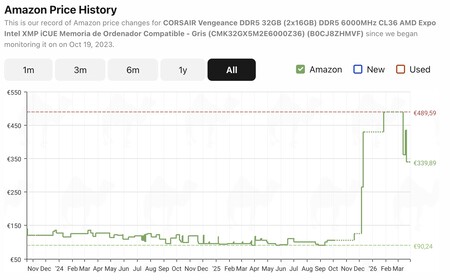
Les mémoires RAM baissent (un peu) de prix. L’impact de TurboQuant a coïncidé avec une certaine baisse des prix des modules de mémoire. Par exemple, les modules Corsair Vengeance DDR5 32 Go 6000 MHz (2×16 Go) étaient à 489,59 euros sur Amazon jusqu’il y a quelques semaines selon CamelCamelCamel, mais en ce moment ils sont à 339,89 euros, une remise notable. Il est vrai que toutes les composantes ne diminuent pas de la même manière, mais il existe effectivement des cas dans lesquels des réductions semblent se produire. Ici, cependant, il convient de noter que TurboQuant affecte les mémoires utilisées dans les accélérateurs d’IA, et non ces composants pour PC ou ordinateurs portables. Les baisses constatées répondent probablement davantage à un cycle d’offre et de demande pour ce type de semi-conducteurs.
À Simseo | La crise de la RAM détruit tous les plans de Valve avec sa Steam Machine