

Géométrie de refus dans les modèles de langage expliquée
Il ne fait aucun doute que ces dernières années, les grands modèles de langage ont montré des capacités extraordinaires en matière de génération de texte, mais aussi des comportements complexes et parfois difficiles à interpréter. L'un d'eux est ce qu'on appelle refusou encore la tendance du modèle à refuser certaines demandes jugées inappropriées ou dangereuses. Traditionnellement, ce phénomène a été interprété comme le résultat de règles apprises lors de formations, souvent liées aux politiques de sécurité.
Cependant, une perspective alternative suggère que le rejet n'est pas seulement une règle symbolique, mais une propriété émergente des représentations internes du modèle. En d’autres termes, le refus pourrait être le résultat de la position qu’occupe une invite dans l’espace latent du modèle.
Cette hypothèse ouvre la voie à une analyse géométrique du comportement des modèles linguistiques, comme le suggère une étude du Cert-Agid publiée en mars 2026.
L'espace latent comme structure géométrique
Lorsqu'un modèle de langage traite une invite, il ne travaille pas directement sur le texte, mais le transforme en une représentation numérique de grande dimension. Cette représentation, appelée «espace latent“, peut être interprété comme un ensemble de points dans un espace géométrique.
En analysant de nombreuses invites différentes, des modèles intéressants émergent :
- les invites bénin ils ont tendance à se concentrer dans certaines régions de l'espace ;
- les invites qui conduisent à des rejets sont réparties dans différentes régions.
Cette séparation suggère que le comportement du modèle peut être décrit géométriquement. S’il existe une distinction entre ces régions, alors il peut également y avoir une direction dans l’espace latent qui les sépare.
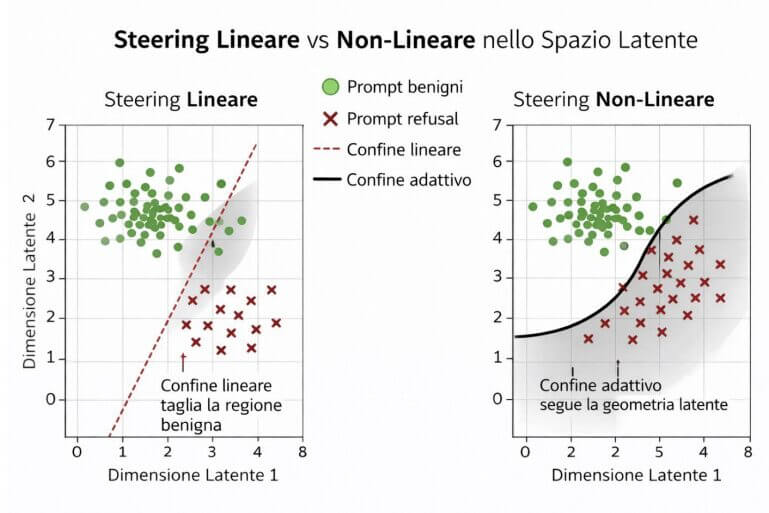
L'idée du pilotage d'activation
De cette intuition est né le concept de activation de la direction. L'idée est simple mais puissante : modifier légèrement les représentations internes du modèle lors de la génération pour influencer son comportement.
En pratique, nous intervenons sur les activations latentes en ajoutant une perturbation selon une direction spécifique. Cette direction représente le vecteur de pilotage, tandis qu'un paramètre scalaire (alpha) contrôle l'intensité du mouvement.
Cette approche ne modifie pas directement la sortie du modèle, mais agit sur le processus interne qui conduit à la génération de la réponse. En conséquence, cela permet un contrôle plus fin et potentiellement plus stable.
Le pipeline expérimental
Pour étudier le phénomène de refus de manière systématique, un pipeline expérimental divisé en plusieurs phases a été développé.
Le processus commence par l'extraction des activations latentes pour un ensemble équilibré de invite nuisible Et bénin. Par la suite, ces représentations sont analysées pour identifier les couches du modèle où la séparation entre les deux classes est la plus évidente.
Une fois les couches les plus prometteuses identifiées, nous procédons à l’apprentissage des orientations et à leur application lors de la génération. Enfin, les différentes configurations sont évaluées sur des benchmarks spécifiques et répliquées sur des jeux de données externes.
Cette structure modulaire vous permet d'isoler et de comprendre chaque étape du processus, en évitant les décisions arbitraires.
Extraction et représentation des activations
Chaque invite est traitée par le modèle via une séquence de couches, dont chacune produit une représentation interne. Pour chaque couche, le vecteur relatif au dernier jeton est enregistré, considéré comme une synthèse de l'état du modèle.
Le résultat est une structure de données tridimensionnelle :
nombre d'invites × nombre de couches × taille latente.
Cette représentation peut être visualisée sous la forme d'un nuage de points pour chaque couche, où chaque point correspond à une invite. C’est précisément dans ces nuages que s’observe la séparation entre les deux classes.
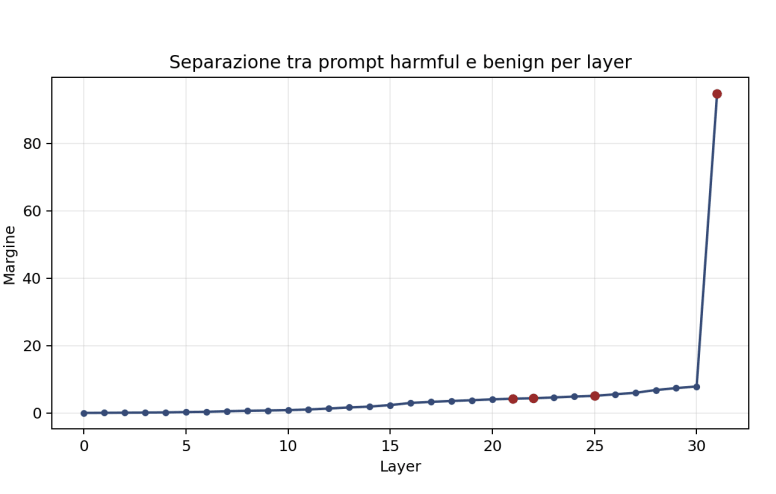
Analyse de séparation rapide
Pour quantifier la séparation entre les invites nuisibles et bénignes, une mesure appelée marge. Cette valeur représente la distance moyenne entre les deux distributions projetées selon une direction de contraste.
L'analyse montre que la séparation augmente progressivement dans les couches profondes du modèle. Cependant, la couche présentant la plus grande séparation n’est pas nécessairement la meilleure couche pour appliquer le pilotage.
En fait, le choix final de la couche dépend aussi du comportement observé lors de la génération, et pas seulement des métriques géométriques.
Méthodes d'apprentissage de la direction de direction
L'un des aspects centraux de l'étude concerne la comparaison entre différentes méthodes d'identification de la direction de direction dans l'espace latent.
Vecteur de consensus
La méthode la plus simple consiste à calculer la différence entre les activations moyennes d’invites nuisibles et bénignes. Cette direction relie les centres des deux distributions et représente une approche linéaire.
Il est facile à mettre en œuvre et souvent efficace, mais peut introduire des effets secondaires si la séparation réelle n’est pas parfaitement linéaire.
Machines à fonctionnalités récursives (RFM)
La méthode RFM adopte une approche plus sophistiquée. Au lieu de simplement faire des moyennes, il essaie d'apprendre une fonction de séparation entre les deux classes et utilise le gradient de cette fonction comme direction de pilotage.
Cela permet de s'adapter à la géométrie locale de l'espace latent et, en théorie, d'obtenir une séparation plus précise.
Décomposition en valeurs singulières (SVD)
La méthode basée sur SVD analyse la variance globale des données. Après une phase de blanchiment, identifiez la direction principale selon laquelle les activations varient le plus.
Toutefois, cette orientation n’est pas nécessairement alignée sur la séparation des classes, ce qui peut réduire son efficacité dans le contrôle des refus.
Injection de direction
Une fois la direction déterminée, un pilotage est appliqué lors de la génération en modifiant les activations internes du modèle.
La formule est simple :
nouvelle activation = activation d'origine + vecteur de direction alpha ×.
Le paramètre alpha joue un rôle crucial : des valeurs trop petites ont des effets négligeables, tandis que des valeurs trop grandes peuvent provoquer une dégénérescence ou une instabilité.
Le but est de trouver un équilibre qui permette de changer de comportement sans compromettre sa qualité.
Paramètres d'évaluation
L'évaluation du comportement du modèle ne se limite pas à la fréquence de rejet. Différentes dimensions sont considérées :
- rejet clair et rejet doux
- qualité et utilité des réponses
- présence de dégénérescence
- stabilité sur des invites bénignes
Deux indicateurs principaux découlent de ces observations :
- la capacité de répondre à des invites nuisibles
- stabilité sur les demandes bénignes
Une configuration n'est considérée comme valable que si elle améliore le premier aspect sans aggraver le second.
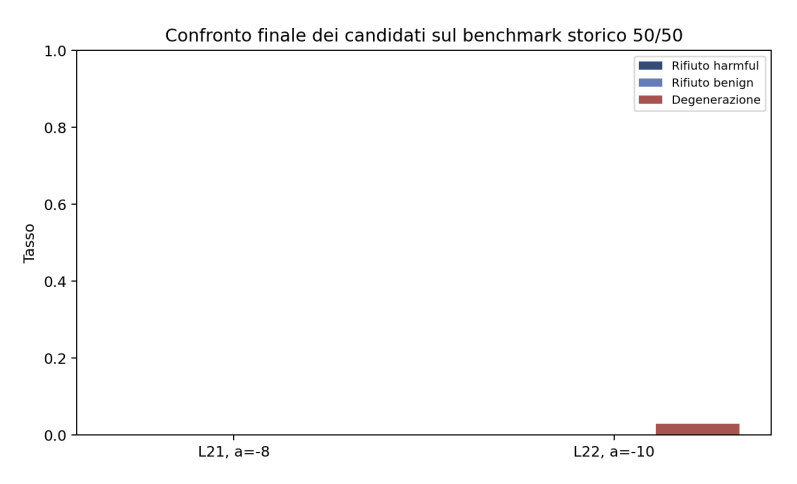
Principaux résultats
L'analyse expérimentale a permis d'identifier une configuration particulièrement efficace : appliquer un pilotage à la couche 21 avec une valeur alpha de -8.
Cette configuration a réussi à éliminer complètement les erreurs sur les invites nuisibles dans le benchmark, sans introduire d'effets négatifs sur les invites inoffensives et sans générer de dégénérescence significative.
Le résultat a également été confirmé sur un ensemble de données externe, suggérant une bonne généralisation.
Grâce à un pipeline expérimental progressif, une configuration de pilotage stable a été identifiée dans le modèle Mistral-7B-Instruct-v0.2 (couche 21, α = −8), capable de réduire complètement les refus sur les invites nuisibles du benchmark sans introduire de refus sur les invites bénignes et sans générer de dégénérescence significative.
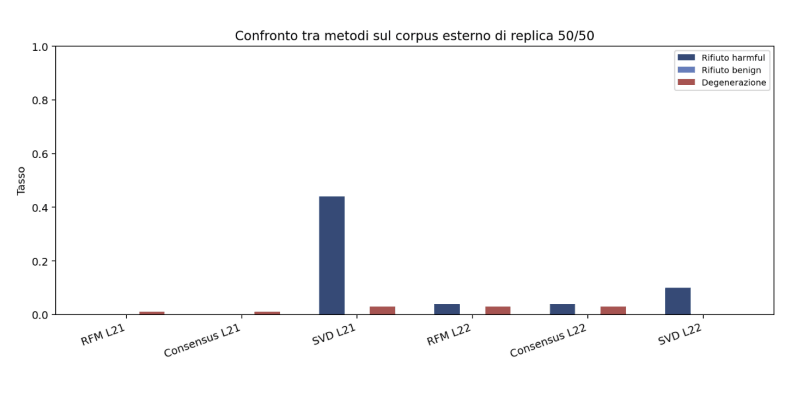
Comparaison entre les méthodes
L’un des résultats les plus intéressants concerne la comparaison entre les différentes méthodes de pilotage.
La méthode RFM et le vecteur consensus produisent des directions quasiment identiques, avec une similarité cosinus proche de 1. Cela indique que, dans le cas analysé, la séparation entre les classes est approximativement linéaire.
En revanche, la méthode SVD s’écarte significativement et montre des performances moindres dans le contrôle des refus.
Interprétation géométrique du refus
Les résultats suggèrent que le comportement de rejet peut être interprété comme une propriété géométrique relativement simple de l'espace latent.
En particulier, il semble y avoir une direction dominante qui sépare les représentations d’incitations nuisibles de celles d’incitations bénignes. Cela implique que le comportement du modèle n'est pas complètement arbitraire, mais suit une structure interprétable.
Cette observation ouvre de nouvelles possibilités pour étudier et tester les modèles linguistiques.
Implications pour la sécurité et le contrôle
L'approche décrite offre une forme de contrôle direct sur le comportement du modèle, sans nécessiter de recyclage ou de changements structurels.
Ceci est particulièrement pertinent dans les contextes où vous devez équilibrer sécurité, transparence et performances. Aussi, l'utilisation de modèles poids ouvert vous permet d'analyser et de modifier les représentations internes sans transférer de données sensibles vers des services externes.
De ce fait, ce type d’analyse est particulièrement adapté aux applications institutionnelles et aux environnements réglementés. Par exemple, pour des contextes institutionnels où la protection des données et la possibilité d'un audit technique sont des exigences fondamentales. L'approche présentée suggère donc une direction possible pour le développement de systèmes d'IA plus contrôlables, vérifiables et compatibles avec les besoins de sécurité de l'administration publique.
Limites et perspectives d’avenir
Malgré les résultats prometteurs, l’étude présente certaines limites. En particulier, l’analyse a été menée sur un seul modèle et sur un nombre limité de prompts.
De plus, la linéarité observée peut ne pas se généraliser à tous les modèles ou à tous les types de comportement.
Des recherches futures pourraient explorer :
- modèles de différentes tailles
- des comportements plus complexes
- techniques de pilotage non linéaires
Conclusion
L'analyse géométrique du refus dans les modèles linguistiques représente une étape importante vers une compréhension plus approfondie de leur fonctionnement.
En montrant que le comportement peut être décrit et modifié dans l’espace latent, cette approche ouvre la voie à des systèmes d’IA plus contrôlables, interprétables et plus sûrs.
En fin de compte, la géométrie de l’espace latent n’est pas seulement une représentation mathématique, mais une clé pour comprendre et guider le comportement des modèles de langage du futur.