
GeneBench-Pro : Que vaut l’IA en biologie computationnelle
OpenAI tente de faire passer le débat sur l’intelligence artificielle en biologie d’une question technique à une question économique : que vaut un modèle capable de naviguer dans des données sales, des hypothèses incertaines et des décisions à fort impact, en termes de temps, de coût et de productivité de la recherche ? La réponse proposée avec GeneBench-Pro, annoncée le 30 juin 2026, est que le goulot d’étranglement de la génomique ne réside plus seulement dans la collecte ou le séquençage d’échantillons, mais dans l’analyse en aval. C’est ici que se concentrent aujourd’hui les délais longs, les travaux spécialisés et les coûts élevés.
Une référence construite pour le vrai travail
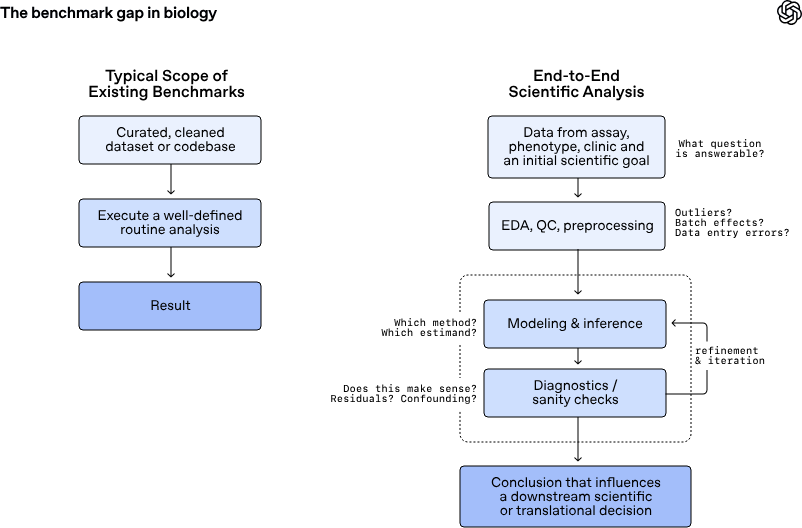
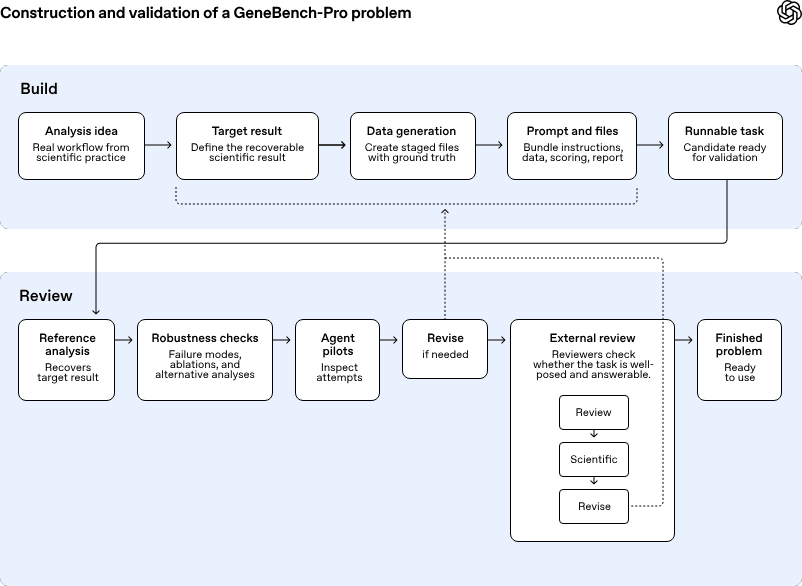
GeneBench-Pro est une référence de niveau recherche conçue pour tester les agents d’IA sur des tâches de biologie computationnelle qui ressemblent au travail de laboratoire et d’analyse effectué quotidiennement par les chercheurs, les biostatisticiens et les équipes translationnelles. OpenAI le décrit comme un système permettant de mesurer non pas la simple capacité à mémoriser des notions ou à appliquer des pipelines standards, mais le jugement scientifique : comprendre si un modèle est un signal ou un bruit, décider si les données soutiennent réellement une question de recherche, changer de méthode lorsque les diagnostics indiquent que la première approche est erronée.
Le benchmark contient 129 problèmes répartis dans 10 domaines et 21 sous-domaines, notamment la génétique statistique, la génomique oncologique, la pharmacogénomique, la protéomique, la génomique microbienne et le diagnostic clinique. Chaque problème place le modèle devant un ensemble de données réalistes, un contexte expérimental synthétique mais plausible et une estimation finale à produire sur la base d’une décision concrète.
OpenAI prétend avoir construit les tâches sous une forme synthétique précisément pour éviter deux défauts fréquents des repères scientifiques : la dépendance à des choix arbitraires de l’auteur et la possibilité d’arriver à un résultat formellement acceptable malgré une erreur d’analyse.
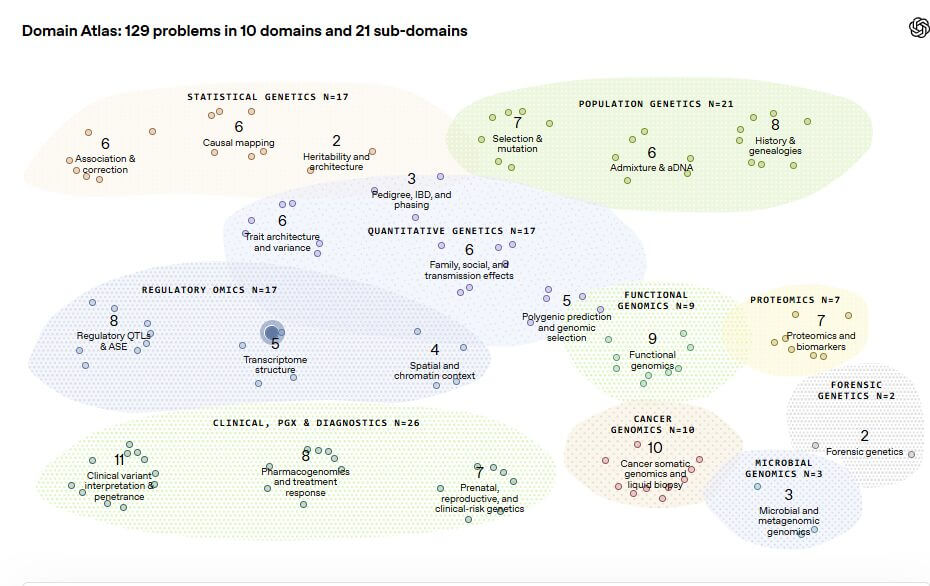
Pour valider le projet, 82 des 129 questions ont été soumises à une évaluation externe par des doctorants, des chercheurs post-doctoraux, des scientifiques industriels et des professeurs. Le point pertinent, au niveau industriel, est qu’OpenAI ne présente pas GeneBench-Pro comme un test académique abstrait, mais comme une mesure de la valeur potentielle d’une automatisation partielle dans des contextes où le travail humain expert est coûteux et difficile à mettre à l’échelle.
Les chiffres : des progrès rapides, une fiabilité encore limitée
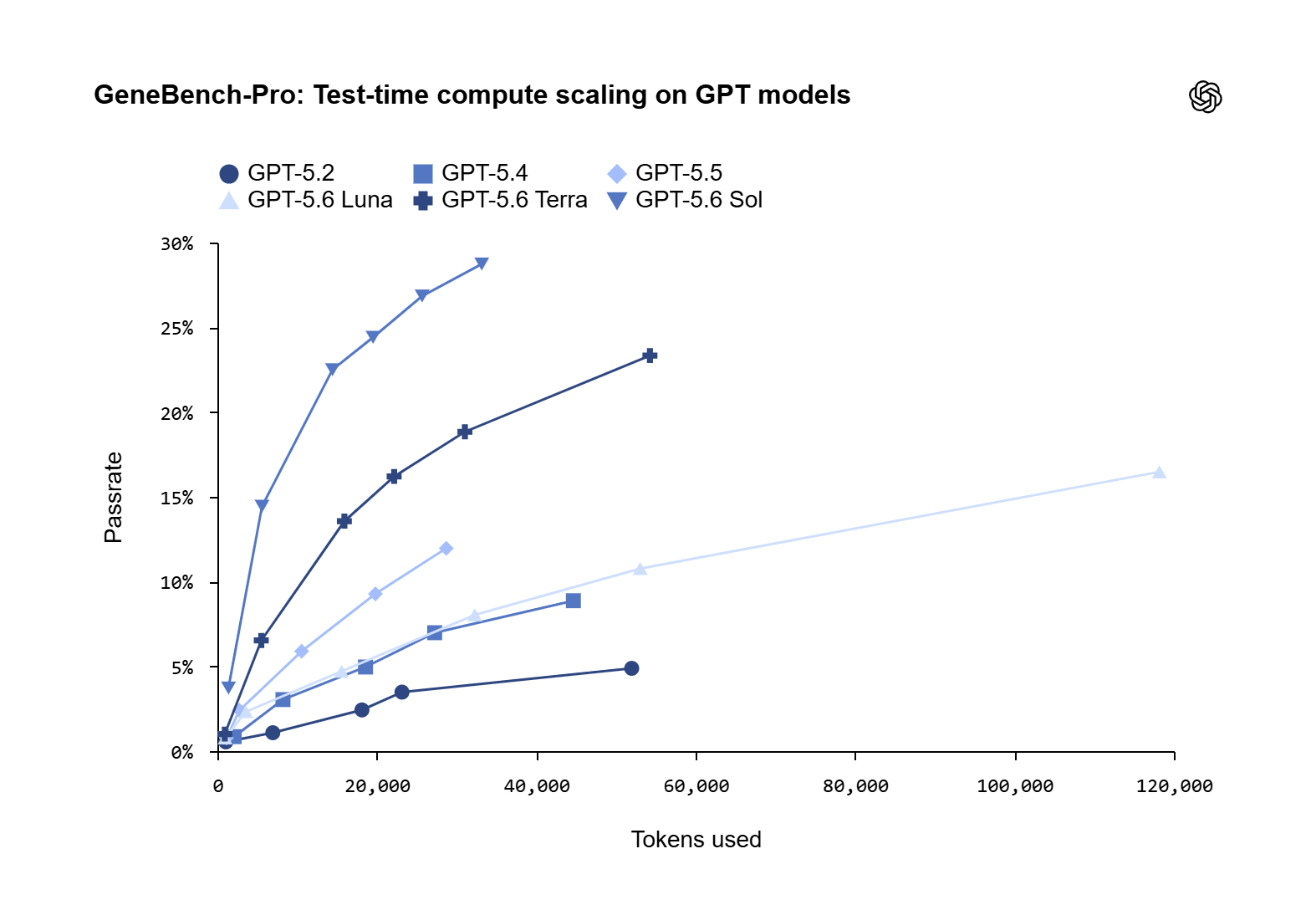
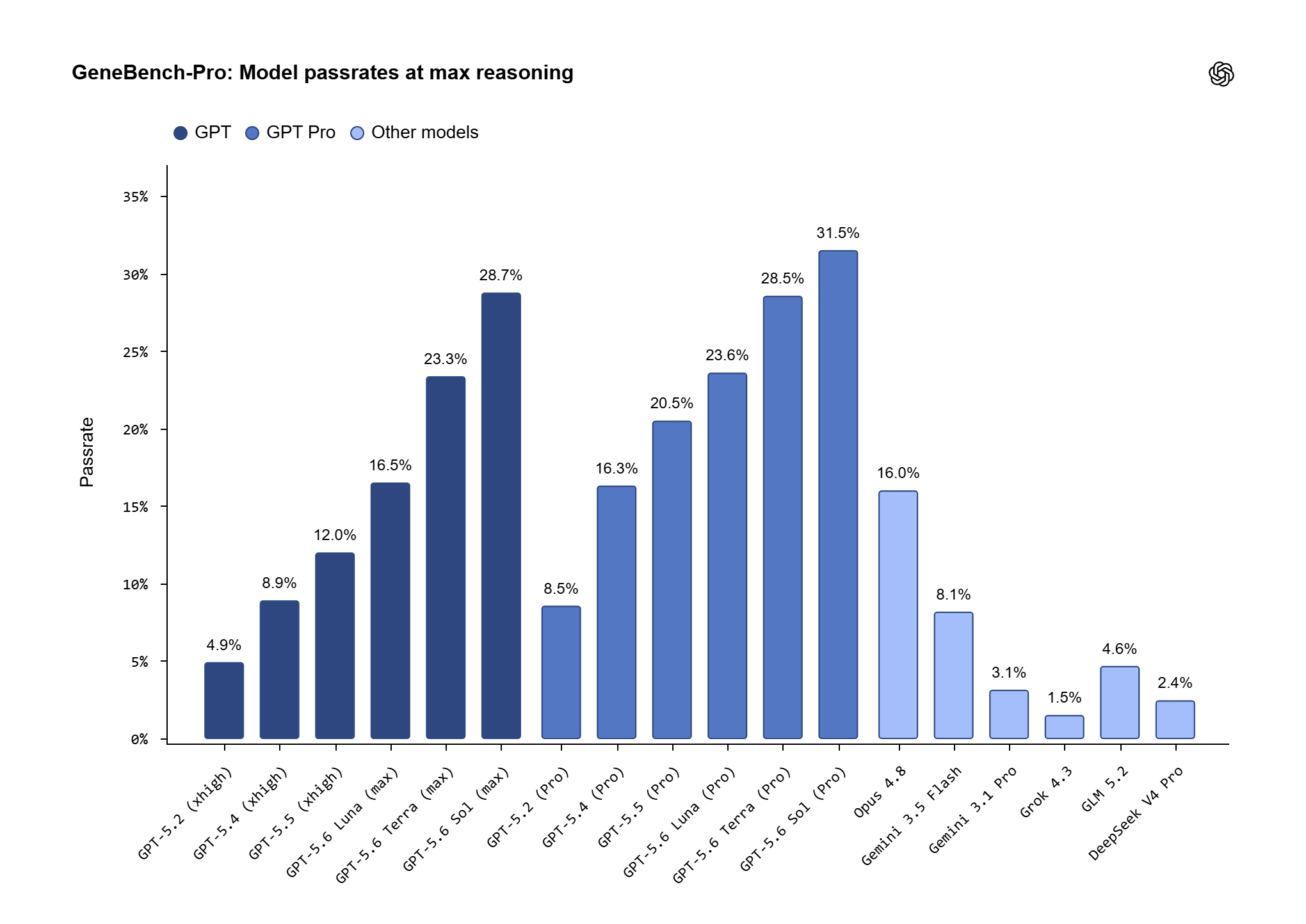
Les résultats publiés par OpenAI montrent que GPT-5.6 Sol atteint un taux de réussite de 28,7 % au niveau de raisonnement maximum, qui s’élève à 31,5 % en mode Pro. La société compare ce chiffre avec le benchmark original GeneBench, où son meilleur modèle frontière au moment de la construction de l’ensemble initial restait inférieur à 5 %. Le saut est clair, mais le fait le plus important en est un autre : même le meilleur système disponible échoue toujours dans plus de deux cas sur trois.
OpenAI associe la croissance des performances à l’augmentation du temps de test de calcul. En d’autres termes, ces systèmes s’améliorent lorsqu’ils peuvent raisonner plus longtemps, explorer davantage d’hypothèses et utiliser davantage de jetons pour parvenir à une conclusion. C’est un signal qui affecte directement ceux qui investissent dans des plateformes d’IA pour la recherche pharmaceutique : les progrès ne dépendent pas uniquement du modèle, mais de la combinaison de la qualité du modèle, du coût de l’inférence et de la capacité à orchestrer des flux de travail complexes.
Cependant, l’annonce elle-même contient une mise en garde importante. OpenAI écrit que les agents restent trop peu fiables pour remplacer les experts humains, mais note également que l’écart de coûts est déjà important : selon les estimations recueillies dans le cadre du benchmark, un problème typique nécessiterait entre 20 et 40 heures de travail d’un expert humain ; En calculant un taux prudent de 200 dollars de l’heure, le coût par tâche unique atteint plusieurs milliers de dollars, contre quelques dollars d’inférence pour un agent. C’est dans cet espace économique que se joue le jeu de l’automatisation partielle.
Parce que l’enjeu concerne les biotechnologies et les médicaments
L’intérêt pour des benchmarks comme GeneBench-Pro augmente à mesure que le secteur des sciences de la vie tente d’industrialiser l’utilisation de l’IA. Benchling, dans son Rapport 2026 sur l’IA biotechnologique basé sur 100 organisations biotechnologiques et biopharmaceutiques utilisant déjà l’IA, il rapporte que les utilisations les plus adoptées sont l’analyse de la littérature à 76 %, la prédiction de la structure des protéines à 71 %, les rapports scientifiques à 66 % et l’identification de cibles à 58 %. Le même rapport ajoute que les applications les plus efficaces sont celles fondées sur des données claires et vérifiables et intégrées aux flux de travail des chercheurs.
C’est un instantané cohérent avec le message de GeneBench-Pro. Le problème n’est pas seulement d’avoir des modèles brillants, mais de les confronter à des données suffisamment structurées pour permettre des décisions fiables. Benchling le formule directement dans un contenu publié en 2026 : de nombreux projets d’IA en recherche et développement stagnent non pas à cause des limitations du modèle, mais à cause de la qualité de la base de données et de l’infrastructure qui la supporte ; dans certains cas, l’impact mesuré va d’un gain de temps de 50 % à des améliorations du flux de travail entre 7 et 65 fois, mais uniquement lorsque les données ont d’abord été normalisées et gouvernées.
L’IA pour la recherche biomédicale ne remplace pas, du moins pour l’instant, le chercheur. C’est une technologie qui promet de réduire le coût des phases intermédiaires : nettoyage des données, vérification de la cohérence, sélection de la bonne méthode, exclusion des échantillons problématiques, production d’hypothèses et de contre-preuves. Si cela fonctionne, cela réduit le temps passé par les équipes seniors sur des tâches répétitives ou préliminaires. Si cela ne fonctionne pas, cela multiplie les erreurs coûteuses et déplace le risque plus loin, peut-être vers un essai clinique.
Les données croissent plus vite que la capacité de les lire
Le contexte permet de comprendre pourquoi OpenAI insiste sur le thème du « goulot d’étranglement ».
UK Biobank a publié une mise à jour majeure en 2026 : le séquençage complet du génome de 490 640 participants. L’institution affirme que cet ensemble de données, combiné à de riches données phénotypiques, renforce la possibilité de trouver des associations génomiques et de développer des diagnostics, des thérapies et une médecine de précision. (Source : Biobanque britannique)
Aux États-Unis, le programme Nous tous des National Institutes of Health continue d’élargir la portée des données disponibles. Le NIH décrit l’ensemble de données comme une ressource combinant des enquêtes, des dossiers de santé électroniques, des analyses génomiques, des mesures physiques et des données portables, accessibles aux chercheurs via une plateforme cloud sécurisée. Autrement dit : plus de données, plus hétérogènes, plus proches de la pratique clinique réelle. (Source : Instituts nationaux de santé NIH)
À mesure que l’ampleur des données augmente, la valeur économique de ceux qui savent en extraire des signaux robustes augmente également. Un benchmark comme GeneBench-Pro entre ici : il ne mesure pas si un modèle sait comment répondre à un quiz de biologie, mais s’il sait travailler sur du matériel imparfait sans perdre de vue la décision finale. Pour les entreprises pharmaceutiques, de biotechnologie et les plateformes de recherche, c’est ce point qui peut impacter les coûts de découverte, la sélection des cibles et la rapidité avec laquelle une hypothèse passe de la base de données au programme expérimental.
Autres actualités : L’IA pour la biologie entre en phase industrielle
GeneBench-Pro n’arrive pas dans un vide de marché. Dans les mêmes semaines, OpenAI publie deux autres signaux allant dans le même sens : le 17 juin 2026, il annonce LifeSciBench, un benchmark dédié aux tâches de recherche en sciences de la vie, et le même jour il présente un «chimiste en IA quasi-autonome » développé avec Molecule.one, prétendant avoir amélioré une réaction difficile de chimie médicinale. Début juin, la société a également annoncé de nouvelles capacités GPT-Rosalind pour la recherche biologique, la génomique, la chimie médicinale et les flux de travail expérimentaux. (OpenAI)
Sur le plan industriel, Isomorphic Labs a annoncé une levée de fonds de 2,1 milliards de dollars en 2026 pour étendre sa plateforme de conception de médicaments basée sur l’IA et faire progresser son pipeline de candidats. En janvier, la société a également annoncé une collaboration de recherche avec Johnson & Johnson sur plusieurs cibles et différentes modalités thérapeutiques. Ce sont des signes qui montrent à quel point le marché récompense non seulement les modèles fondateurs généralistes, mais également les entreprises qui promettent de traduire l’IA en molécules, candidats cliniques et accords de développement.
Cela ne veut pas dire que le risque a disparu. Au contraire. La leçon implicite du benchmark est que l’industrie a déjà dépassé le stade où il suffisait de montrer une démo convaincante. Ce qui compte désormais, c’est la robustesse, la vérifiabilité, l’audit des étapes analytiques et la capacité à éviter les erreurs lorsque les données sont incomplètes ou contradictoires. En biologie computationnelle, se tromper de seuil ou traiter un signal parasite comme causal n’est pas un problème théorique : cela peut signifier investir des mois sur une mauvaise cible ou arrêter un programme qui ne tient pas le coup tard.
Où la valeur peut naître
L’utilité économique de ces systèmes, du moins à court terme, ne semble pas résider dans une pleine autonomie. Cela réside dans des soins de haut niveau. OpenAI lui-même écrit que des modèles capables de bonnes performances sur GeneBench-Pro pourraient aider les chercheurs à identifier le flux de travail correct, à explorer les données plus rapidement et à augmenter le rythme, la précision et la reproductibilité de la recherche. Il s’agit d’un positionnement moins spectaculaire, mais plus crédible pour ceux qui doivent décider des priorités budgétaires, d’approvisionnement et technologiques.
Pour le marché, la vraie question n’est pas de savoir si l’IA remplacera le biologiste computationnel. La question est de savoir quelle quantité de main-d’œuvre qualifiée peut être compressée sans augmenter le taux d’erreur. Si un agent peut réduire le temps nécessaire pour écarter des hypothèses faibles, diagnostiquer des problèmes de qualité et proposer des analyses correctes, le bénéfice économique est immédiat, même avec des niveaux de précision loin d’être parfaits. Si toutefois cela nécessite une surveillance continue et produit des erreurs opaques, les économies se dissolvent.
GeneBench-Pro mesure précisément ce seuil. Aujourd’hui, le benchmark indique que les modèles se sont améliorés rapidement, mais qu’ils ne sont pas encore suffisamment robustes pour boucler à eux seuls la boucle d’inférence. Pour les entreprises biotechnologiques et pharmaceutiques, c’est une double nouvelle : la promesse reste intacte, mais la valeur se matérialisera surtout là où des données bien organisées existent déjà, des équipes capables de vérifier les résultats et une chaîne décisionnelle prête à utiliser l’IA comme levier de productivité et non comme raccourci.
Lire l’article complet