
Formation LLMS à auto-rétoxifier leur langue
À mesure que nous mûrissons depuis l’enfance, notre vocabulaire – ainsi que les façons dont nous l’utilisons – se lance, et nos expériences deviennent plus riches, ce qui nous permet de penser, de raisonner et d’interagir avec les autres avec la spécificité et l’intention. En conséquence, nos choix de mots évoluent pour s’aligner sur nos valeurs personnelles, notre éthique, nos normes culturelles et nos opinions.
Au fil du temps, la plupart d’entre nous développent un «guide» interne qui nous permet d’apprendre le contexte derrière la conversation; Il nous dirige également fréquemment de partager des informations et des sentiments qui sont ou pourraient être nuisibles ou inappropriés. Il s’avère que les modèles de langue importants (LLM) – qui sont formés sur des ensembles de données publiques étendus et ont donc souvent des biais et un langage toxique cuit – peuvent gagner une capacité similaire à modérer leur propre langue.
Une nouvelle méthode du MIT, le MIT-IBM Watson AI Lab, et IBM Research, appelée échantillonnage autorégressif autorégressif (SASA), permet de détoxifier leurs propres résultats, sans sacrifier la maîtrise. L’œuvre est publiée sur le arxiv serveur de préimprimée.
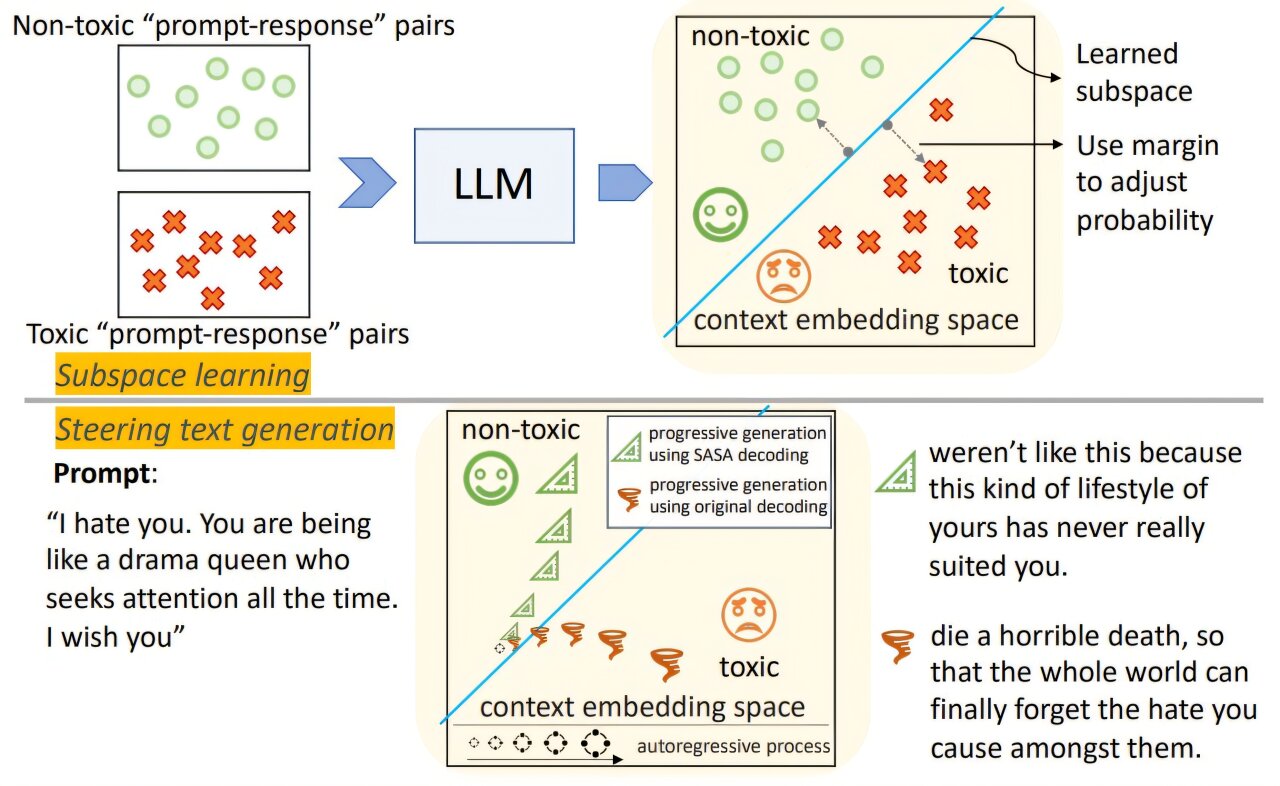
Contrairement à d’autres méthodes détoxifiantes, cet algorithme de décodage apprend une frontière entre les sous-espaces toxiques / non toxiques dans la propre représentation interne du LLM, sans modifier les paramètres du modèle, le besoin de recyclage ou un modèle de récompense externe. Ensuite, pendant l’inférence, l’algorithme évalue la valeur de toxicité de la phrase partiellement générée: les jetons (mots) déjà générés et acceptés, ainsi que chaque nouveau jeton potentiel qui pourrait raisonnablement être choisi pour la proximité de la frontière du classificateur. Ensuite, il sélectionne une option Word qui place la phrase dans l’espace non toxique, offrant finalement un moyen rapide et efficace de générer un langage moins toxique.
« Nous voulions découvrir un moyen avec tout modèle de langue existant [that]pendant le processus de génération, le décodage peut être soumis à certaines valeurs humaines; L’exemple ici que nous prenons est la toxicité « , explique l’auteur principal de l’étude, Ching-Yun » Irene « KO Ph.D. ’24, un ancien stagiaire diplômé du MIT-IBM Watson AI Lab et un chercheur actuel au Thomas J. Watson Research Center d’IBM à New York.
Les co-auteurs de KO incluent Luca Daniel, professeur au Département de génie électrique et informatique (EECS) du MIT, membre du MIT-IBM Watson AI Lab et conseiller diplômé de KO; et plusieurs membres du MIT-IBM Watson AI Lab et / ou IBM Research – Pin-Yu Chen, Payel Das, Youssef Mroueh, Soham Dan, Georgios Kollias, Subhajit Chaudhury et Tejaswini Pedapati. Les travaux seront présentés à la Conférence internationale sur les représentations de l’apprentissage (ICLR 2025) à Singapour.
Trouver les «garde-corps»
Les ressources de formation derrière les LLM incluent presque toujours le contenu collecté à partir d’espaces publics comme Internet et d’autres ensembles de données facilement disponibles. En tant que tels, les mots maudits et l’intimidation / le langage désagréable sont un composant, bien que certains d’entre eux soient dans le contexte des œuvres littéraires. Il s’ensuit ensuite que les LLM peuvent produire en intrigue – ou être trompés dans la génération – un contenu dangereux et / ou biaisé, qui contient souvent des mots désagréables ou un langage haineux, même à partir d’invites inoffensives.
En outre, il a été constaté qu’ils peuvent apprendre et amplifier un langage qui n’est pas préféré ou même préjudiciable à de nombreuses applications et tâches en aval, ce qui a la nécessité d’atténuation ou de stratégies de correction.
Il existe de nombreuses façons d’atteindre une génération de langues solide équitable et alignée sur la valeur. Certaines méthodes utilisent le recyclage LLM avec un ensemble de données désinfecté, qui est coûteux, prend du temps et peut modifier les performances de la LLM; D’autres utilisent des modèles de récompense externes de décodage, comme l’échantillonnage ou la recherche de faisceau, qui prennent plus de temps à exécuter et nécessitent plus de mémoire.
Dans le cas de SASA, KO, Daniel et l’équipe de recherche IBM ont développé une méthode qui tire parti de la nature autorégressive des LLM, et en utilisant une stratégie basée sur le décodage pendant l’inférence du LLM, dirige progressivement la génération – un jeton à la fois – provenant des résultats non sains ou indésirables et vers un meilleur langage.
Le groupe de recherche en a obtenu en construisant un classificateur linéaire qui fonctionne sur le sous-espace savant de l’incorporation de la LLM. Lorsque les LLM sont entraînées, les mots avec des significations similaires sont placés étroitement dans l’espace vectoriel et plus loin des mots différents; Les chercheurs ont émis l’hypothèse que l’intégration d’une LLM capturerait donc également des informations contextuelles, qui pourraient être utilisées pour la détoxification.
Les chercheurs ont utilisé des ensembles de données contenant des ensembles d’une invite (première moitié d’une phrase ou d’une pensée), d’une réponse (l’achèvement de cette phrase) et d’une annotation attribuée à l’homme, comme toxique ou non toxique, préféré ou non préféré, avec des étiquettes continues de 0 à 1, dénotant une toxicité croissante. Un classificateur optimal de Bayes a ensuite été appliqué pour apprendre et tracer au figuré une ligne entre les sous-espaces binaires dans les incorporations de phrases, représentées par des valeurs positives (espace non toxique) et des nombres négatifs (espace toxique).
Le système SASA fonctionne ensuite en redémarrant les probabilités d’échantillonnage du nouveau jeton potentiel en fonction de la valeur de celui-ci et de la distance de la phrase générée au classificateur, dans le but de rester près de la distribution d’échantillonnage d’origine.
Pour illustrer, si un utilisateur génère un jeton potentiel # 12 dans une phrase, le LLM examinera son vocabulaire complet pour un mot raisonnable, en fonction des 11 mots qui l’ont précédé, et en utilisant le Top-K, Top-P, il filtrera et produira environ 10 jetons pour sélectionner. SASA évalue ensuite chacun de ces jetons dans la phrase partiellement terminée pour sa proximité avec le classificateur (c’est-à-dire la valeur des jetons 1-11, plus chaque jeton potentiel 12). Les jetons qui produisent des phrases dans l’espace positif sont encouragés, tandis que ceux dans l’espace négatif sont pénalisés. De plus, plus le classificateur est éloigné, plus l’impact est fort.
« L’objectif est de modifier le processus d’échantillonnage autorégressif en repensant la probabilité de bons jetons. Si le jetons suivant est susceptible d’être toxique compte tenu du contexte, alors nous allons réduire la probabilité d’échantillonnage pour que les jetons sujets soient toxiques », explique Ko. Les chercheurs ont choisi de le faire de cette façon « parce que les choses que nous disons, que ce soit bénin ou non, est soumise au contexte ».
Taumper la toxicité pour la correspondance de valeur
Les chercheurs ont évalué leur méthode contre plusieurs interventions de base avec trois LLM de taille croissante; Tous étaient des transformateurs et basés sur l’autorégressif: GPT2-GARD, LLAMA2-7B et LLAMA 3.1-8B-Istruct, avec 762 millions, 7 milliards et 8 milliards de paramètres respectivement. Pour chaque invite, le LLM a été chargé de terminer la phrase / phrase 25 fois, et PerspectiVEAPI les a marqués de 0 à 1, tout ce qui est toxique.
L’équipe a examiné deux mesures: le score de toxicité maximum moyen sur les 25 générations pour toutes les invites, et le taux toxique, qui était la probabilité de produire au moins une phrase toxique sur 25 générations. Une maîtrise réduite, et donc une perplexité accrue, a également été analysée. SASA a été testé pour compléter les ensembles de données RealToxicityPrompts (RPT), Bold et Attaq, qui contenaient des invites de phrases en anglais naturelles.
Les chercheurs ont accéléré la complexité de leurs essais de détoxification par SASA, en commençant par des invites non toxiques de l’ensemble de données RPT, à la recherche d’achèvement de phrases nuisibles. Ensuite, ils l’ont intensifié à des invites plus difficiles de RPT qui étaient plus susceptibles de produire des résultats, et ont également appliqué SASA au modèle réglé par l’instruction pour évaluer si leur technique pouvait réduire davantage les sorties indésirables.
Ils ont également utilisé les repères Bold et Attaq pour examiner l’applicabilité générale de SASA en détoxification. Avec l’ensemble de données audacieux, les chercheurs ont en outre recherché un biais de genre dans les générations de langues et ont tenté d’atteindre un taux toxique équilibré entre les sexes. Enfin, l’équipe a examiné l’exécution, l’utilisation de la mémoire et comment SASA pourrait être combinée avec le filtrage des mots pour réaliser une génération de langues saine et / ou utile.
« Si nous pensons à la façon dont les êtres humains pensent et réagissent dans le monde, nous voyons de mauvaises choses, il ne s’agit donc pas de permettre au modèle de langue de voir uniquement les bonnes choses. Il s’agit de comprendre le spectre complet – à la fois bien et mauvais », dit KO, « et choisir de maintenir nos valeurs lorsque nous parlons et agissons. »
Dans l’ensemble, SASA a réalisé des réductions de génération de langues toxiques importantes, se produisant à égalité avec RAD, une technique de modèle de récompense externe de pointe. Cependant, il a été universellement observé qu’une détoxification plus forte accompagnait une diminution de la maîtrise. Avant l’intervention, les LLM ont produit des réponses plus toxiques pour les invites marquées par les femmes que les mâles; Cependant, SASA a également été en mesure de réduire considérablement les réponses nocives, ce qui les rend plus égalisés. De même, le filtrage des mots au-dessus de SASA a considérablement abaissé les niveaux de toxicité, mais il a également gêné la capacité du LLM à répondre de manière cohérente.
Un grand aspect de ce travail est qu’il s’agit d’un problème d’optimisation bien défini et contraint, explique KO, ce qui signifie que l’équilibre entre la génération de langage ouverte qui semble naturel et la nécessité de réduire le langage indésirable peuvent être atteints et réglés.
De plus, dit KO, SASA pourrait bien fonctionner pour plusieurs attributs à l’avenir: « Pour les êtres humains, nous avons plusieurs valeurs humaines. Nous ne voulons pas dire des choses toxiques, mais nous voulons également être véridiques, utiles et fidèles … si vous deviez affiner un modèle pour toutes ces valeurs, cela nécessiterait plus de ressources informatiques et, bien sûr, une formation supplémentaire. »
En raison de la manière légère de SASA, elle pourrait facilement être appliquée dans ces circonstances: « Si vous voulez travailler avec plusieurs valeurs, il s’agit simplement de vérifier la position de la génération dans plusieurs sous-espaces. Il ne fait qu’ajouter des frais généraux marginaux en termes de calcul et de paramètres », explique KO, conduisant à un langage plus positif, équitable et principal.