

Deepseek: Piccolo ne signifie pas moins de consommation d’énergie
Dvedette Il a apporté un désordre au panorama de l’intelligence artificielle mondiale, avec son « petit et économique et beau ». Parmi les nouvelles associées qui se sont propagées, plus ou moins dotées de validité, il y a que l’intelligence artificielle pourrait Je n’ai pas besoin d’avaler les énormes quantités d’énergie qu’elle utilise actuellement. Mais les données d’une étude publiée par Revue de la technologie du MIT Ils montrent que ce n’est pas vrai.
Ces premières données, sur la base des performances de l’un des plus petits modèles de Deepseek sur un nombre limité de demandes, suggèrent que Il pourrait même être plus cher en termes d’énergie lors de la génération de réponses que le modèle de taille équivalente de la destination.
Le problème pourrait être que L’énergie qui économise dans la formation est compensée par les techniques les plus intensives pour répondre aux questions et aux longues réponses qu’elle produit.
Si cela ajoute à cela que d’autres sociétés technologiques, inspirées par l’approche Deepseek, pourraient commencer à construire des modèles de raisonnement similaires à faible coût, les perspectives de consommation d’énergie semblent déjà beaucoup moins roses.
Dépenses pour la formation et l’inférence
Le cycle de vie de tout modèle d’intelligence artificielle prévoit deux phases: formation et inférence. La formation est le processus, souvent de longs mois, dans lesquels le modèle apprend des données. Le modèle est donc prêt pour l’inférence, qui se déroule chaque fois que quelqu’un lui demande quelque chose. Les deux processus se déroulent généralement dans les centres de données, où il est nécessaire Beaucoup d’énergie pour faire fonctionner les puces et refroidir les serveurs.
En ce qui concerne la formation du modèle R1, l’équipe Deepseek a amélioré la technique SO-appelée Mélange d’expertsdans lequel seule une partie des milliards de paramètres d’un modèle – les « boutons » qu’un modèle utilise pour obtenir de meilleures réponses – est activé à un certain moment pendant la formation. En particulier, avoir un apprentissage amélioré pour le renforcementdans lequel les résultats d’un modèle sont évalués et donc utilisés pour l’améliorer. Souvent, cette tâche est effectuée par des annotarers humains, mais L’équipe Deepseek a réussi à l’automatiser.
L’introduction d’une méthode pour rendre la formation plus efficace pourrait nous faire penser que les entreprises utiliseront moins d’énergie pour amener leurs modèles à un certain niveau. En réalité, cependant, ce n’est pas ainsi que cela fonctionne.
« Puisque la valeur d’un système intelligent est si élevée », a-t-il écrit Dario Amodeico-fondateur de Anthropiquesur son blog, «les entreprises dépensent de pluspas moins, pour former les modèles. Si les entreprises obtiennent plus pour leur argent, elles trouveront commode de dépenser plus et donc d’utiliser plus d’énergie. « Les gains en termes de rentabilité finissent par être entièrement dédiés à la formation de modèles plus intelligents, limité uniquement par les ressources financières de la société », a-t-il écrit. C’est un exemple du SO-appelé Paradoxe de Jevons.
Mais cela est vrai en ce qui concerne l’entraînement depuis le début de la course à l’intelligence artificielle. L’énergie requise pour l’inférence est le point où les choses sont les plus intéressantes.
Deepseek a été conçu comme modèle de raisonnementce qui signifie qu’il a été conçu pour obtenir de bons résultats dans des tâches telles que la logique, la recherche de modèles, les mathématiques et d’autres tâches avec lesquelles les modèles typiques de génératif ont des difficultés. Les modèles de raisonnement font cela en utilisant quelque chose appelé Chaîne de sondage, « Chaîne arrière ». Cela permet au modèle d’intelligence artificielle de diviser sa tâche en parties et de les travailler dans un ordre logique avant de parvenir à la conclusion.
Vous pouvez le voir avec Deepseek. Si nous demandons s’il est juste de mentir pour protéger les sentiments de quelqu’un, le modèle fait d’abord face à la question avec l’utilitarisme, évaluant le bien immédiat par rapport aux dommages futurs potentiels. Considérez ensuite l’éthique kantienne, qui propose d’agir selon les maximes qui pourraient être des lois universelles. Il prend en considération ces nuances et d’autres avant de partager ses conclusions.
Les modèles de chaîne de réflexion ont tendance à obtenir de meilleurs résultats dans certains référence, comme MMLUqui teste les connaissances et la résolution des problèmes chez 57 sujets. Mais, comme il devient clair avec Deepseek, Ils ont également besoin de beaucoup plus d’énergie pour obtenir leurs réponses. Nous avons quelques premiers indices sur la plus grande partie.
Tests de Scott Chamberlin
Scott Chamberlin a passé des années à Microsoft et par la suite à Intel, créant des outils pour aider à révéler les coûts environnementaux de certaines activités numériques. Chamberlin a effectué quelques tests initiaux pour voir Combien d’énergie consomme un GPU lorsque Deepseek vient à sa réponse. L’expérience s’accompagne d’une série d’avertissements: il n’a testé qu’une version de taille moyenne de Deepseek R-1, en utilisant seulement un petit nombre de demandes. Il est également difficile de faire des comparaisons avec d’autres modèles de raisonnement.
Post de Chamberlin sur LinkedIn
«Les déclarations sur la réduction des besoins en calcul et en énergie pour les modèles de type Seek Deep pourraient être exagérées.
La semaine dernière, nous avons commencé à évaluer Deep Seek (comme toute autre chose dans le monde) pour évaluer leurs compétences d’impact énergétique et d’optimisation pour notre plateforme. Voici les résultats de notre suite de tests d’inférence dans le monde réel.
J’ai choisi de comparer Lama 3.3 70b avec Profonde recherche R1 70bcomme ils sont capables de souligner efficacement un seul H100 (Nvidia, ed) avec chacun d’eux sans avoir à recourir à une configuration prolongée. Il existe un élément de comparaison entre les pommes et les oranges; Alors que Deep Seek R1 70b est distillé par Llama 3.3, il est conçu pour fournir une chaîne de réflexion et générer une fenêtre de sortie beaucoup plus longue, tandis que Llama 3.3 est réglé pour le chat et un raisonnement. Je suis principalement intéressé par la consommation d’énergie de chacun et je normaliserai les résultats (les deux ont le même nombre de paramètres, ce qui aide à contrôler cet aspect).
Le résultat net est que les deux modèles ont approximativement la même efficacité énergétique (jetons / ws) avec des performances légèrement plus faibles (4,8% de jetons / s). Cependant, Deep Seek R1 70B a un double temps d’exécution (en raison de la génération d’un si grand nombre de jetons hors de la sortie), avec une consommation d’énergie totale de 87% plus élevée que LLAMA 3.3 sur le même ensemble de demandes. Bien que la production de jeton soit limitée, l’efficacité énergétique du jeton serait similaire, ce qui signifie que l’impact d’énergie totale par rapport aux modèles les plus couramment utilisés est probablement le même (sortie limitée) ou pire (sorties plus longues).
Bien que l’opinion commune si La formation de recherche profonde a probablement utilisé une quantité d’énergie significativement plus faible que les modèles similairesnous croyons que le«L’inférence constituera la plupart des consommateurs d’énergie et de calcul à l’avenir. Les meilleurs modèles seront plus utiles et, bien que nous améliorerons leur efficacité énergétique, nous nous retrouverons probablement devant le paradoxe de Jevon, dans lequel ils seront encore plus utilisés.
En regardant les données, je ne peux que prédire que ces innovations nous amèneront à maintenir les mêmes tendances de croissance de la consommation d’énergie qu’avant la question de Deepseek V3 / R1 « .

Tests de l’Université du Michigan
Deepseek est « vraiment le premier modèle de raisonnement très populaire auquel nous avons tous accès », explique Chamberlin. Le modèle O1 par OpenII C’est son concurrent le plus proche, mais l’entreprise ne la rend pas disponible pour les tests. L’auteur l’a plutôt testé contre un modèle de destination avec le même nombre de paramètres: 70 milliards.
La question se demandait s’il était juste de mentir a généré une réponse de 1 000 mots par le modèle Deepseek, qui Il a demandé 17 800 joule à générer, sur ce qui est nécessaire pour transmettre une vidéo de 10 minutes sur YouTube. C’est environ 41% de plus d’énergie que celle utilisée par le méta-modèle pour répondre à la question. Dans l’ensemble, lorsqu’il a été testé sur 40 demandes, Deepseek en avait un ‘efficacité Une énergie similaire à celle du méta-modèle, mais Deepseek avait tendance à générer des réponses beaucoup plus longues et donc elle a été utilisée pour utiliser 87% d’énergie en plus.
Comment ces données sont-elles par rapport aux modèles qui utilisent le vieil homme à la chaîne de pensée générative et non à la pensée? Les tests effectués en octobre par une équipe de l’Université du Michigan ont révélé que la version de 70 milliards de paramètres de LLAMA 3.1 de Meta ne consommait en moyenne que 512 joules par réponse.
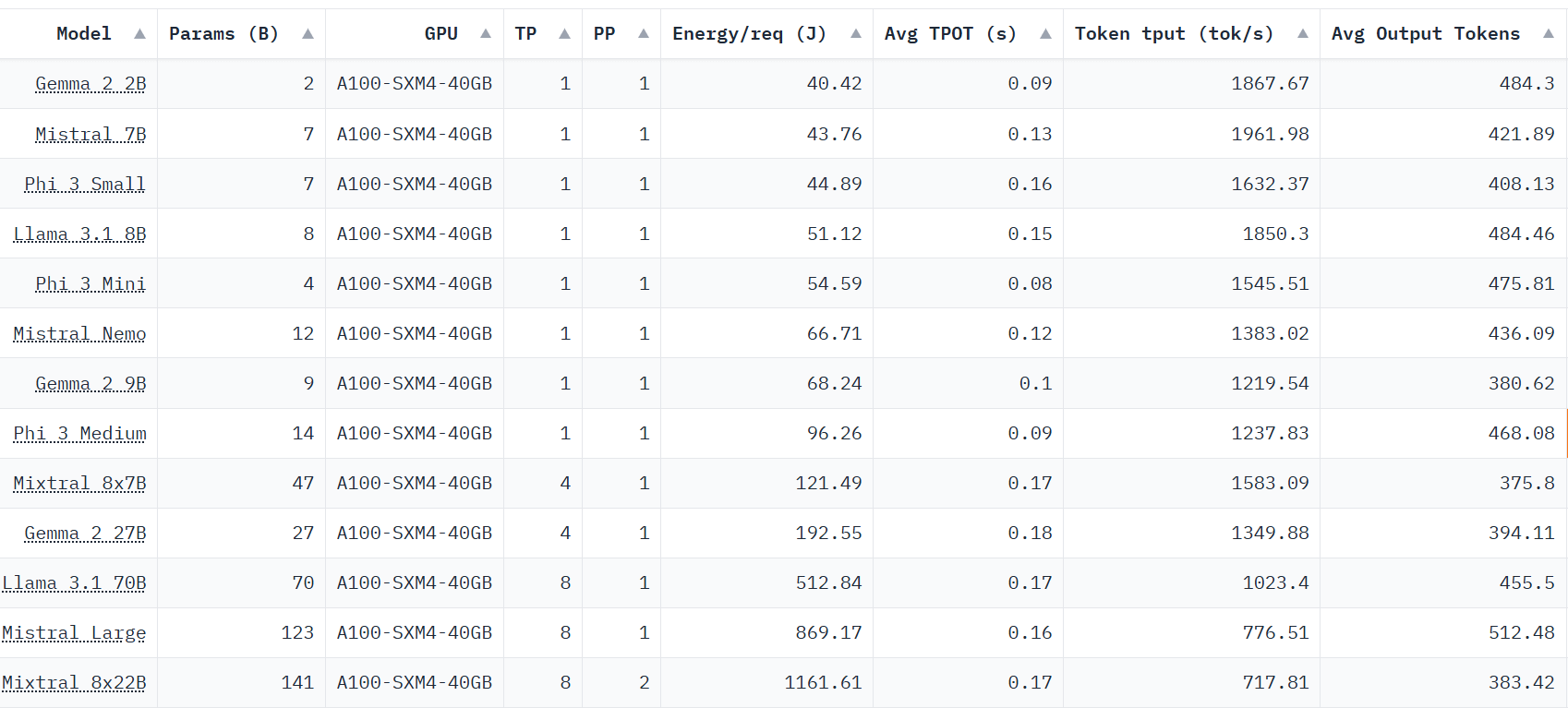
Processeur A100-SXM4-40 Go
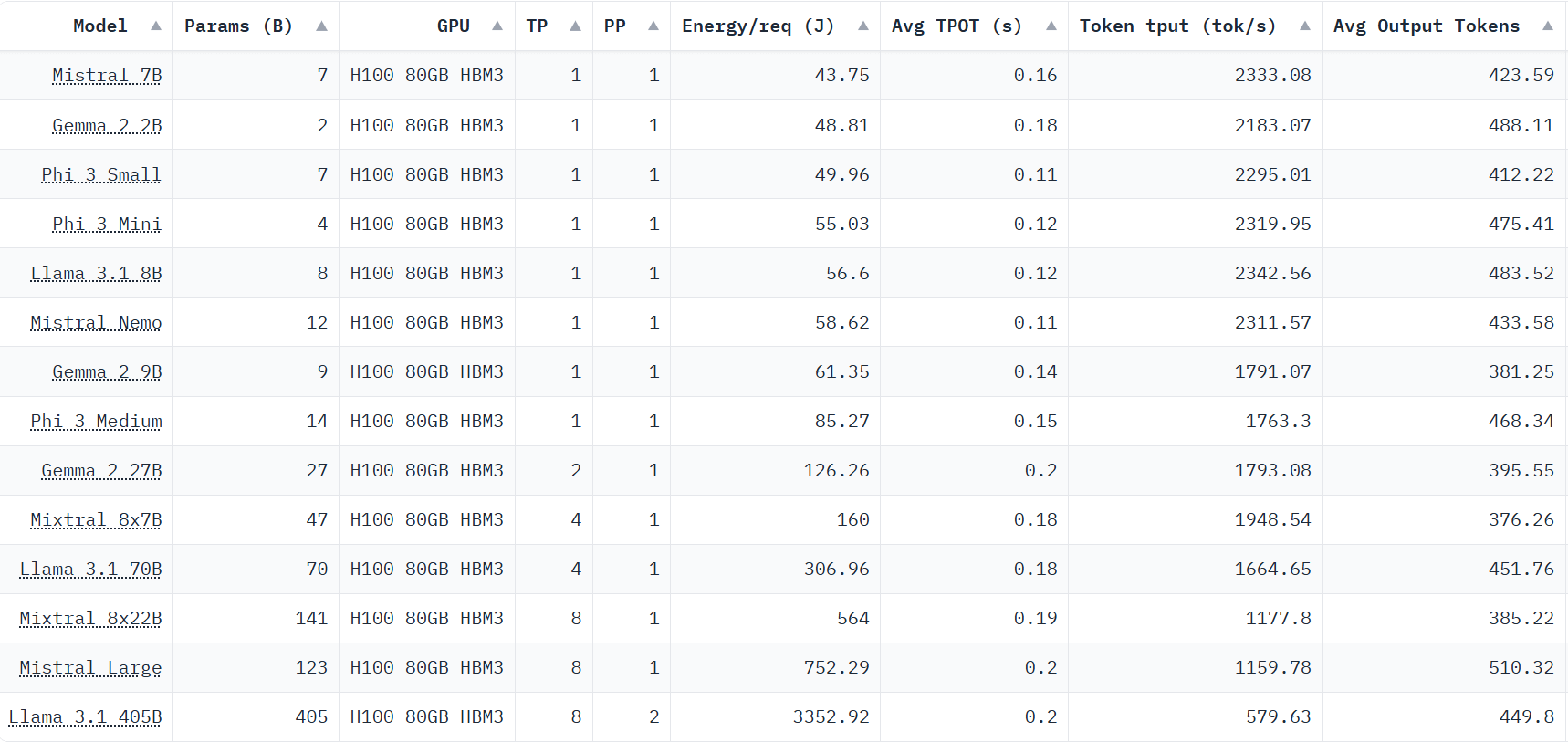
Processeur H100 80 Go HBM3
Encore une fois: les incertitudes abondent. Ce sont des modèles différents, à des fins différentes, et une étude scientifiquement valide n’a pas été réalisée sur la quantité d’énergie utilisée par Deepsek par rapport aux concurrents. Mais il est clair, basé uniquement sur l’architecture des modèles, que les modèles de chaîne de réflexion utilisent beaucoup plus d’énergie pour obtenir des réponses plus fiables.
Sasha Luccionichercheur de l’intelligence artificielle et directeur du climat à Hugging Face, craint que l’enthousiasme de Deepseek puisse conduire à une race pour insérer cette approche dans tout, même où elle n’est pas nécessaire.
« Si nous commencions à adopter ce grand paradigme à l’échelle, l’utilisation de l’énergie pour l’inférence allait sur les étoiles », dit-il. «Si tous les modèles libérés sont plus intensifs du point de vue du calcul et deviennent des chaînes de pensée, Ensuite, tout gain est complètement annulé en termes d’efficacité « .
Avant le lancement du Chatgpt en 2022, le nom du jeu dans l’IA était extractifou trouver des informations dans beaucoup de texte ou catégoriser les images. Mais en 2022 L’attention est passée de l’extraction à l’IA générativequi est basé sur l’élaboration de prévisions toujours meilleures. Cela nécessite plus d’énergie.
« Il s’agit du premier changement de paradigme », explique Luccioni. Selon ses recherches, ce changement a conduit à utiliser davantage de commandes d’énergie pour effectuer des tâches similaires.
Si la ferveur autour de Deepseek continue, selon Luccioni, les entreprises pourraient être poussées à insérer ses modèles dans le style de la chaîne de pensées dans tout, tout comme le générateur a été ajouté à tout, de la recherche sur Google à des applications de messagerie.
Il semble que nous nous dirigeons vers un plus grand nombre de modèles de raisonnement de la chaîne de pensées: OpenII a annoncé le 31 janvier 2025 qu’il aurait étendu l’accès à son modèle de raisonnement, O3.
Mais nous n’en saurons pas plus sur les coûts énergétiques tant que Deepseek et d’autres modèles similaires ne seront pas mieux étudiés.