
De nouvelles pistes métriques où les modèles de raisonnement multimodal tournent mal
Au cours des dernières décennies, les informaticiens ont introduit des modèles basés sur l'apprentissage automatique de plus en plus sophistiqués, qui peuvent performer remarquablement bien sur diverses tâches. Ceux-ci incluent des modèles multimodaux de grande langue (MLLM), des systèmes qui peuvent traiter et générer différents types de données, principalement des textes, des images et des vidéos.
Certains de ces modèles, tels que GPT4 d'OpenAI avec Vision (GPT-4V), Deepseek-R1 et Google Gemini, sont désormais largement utilisés par les utilisateurs du monde entier pour créer un contenu multimodal spécifique, y compris des images pour les publications ou les articles de médias sociaux, ainsi que des textes adaptés à des utilisations spécifiques.
Bien que les capacités de raisonnement de ces modèles se soient considérablement améliorées ces dernières années, ce qui leur permet de résoudre des problèmes mathématiques et de raisonnement, des études ont montré qu'elles répondent parfois à des choses qui ne sont pas fondées sur les données d'entrée, par exemple, en décrivant des détails qui n'existent pas réellement dans une image d'entrée.
Ces hallucinations ont été liées aux priors linguistiques et aux biais internes qu'un modèle peut avoir acquis pendant la formation pendant qu'il analysait de grands ensembles de données de texte. Ces biais peuvent remplacer les informations visuelles fournies au modèle (c.-à-d. Images d'entrée), ce qui fait que le modèle termine mal les tâches qui lui sont attribuées.
Des chercheurs de l'UC Santa Cruz, de l'Université de Stanford et de l'UC Santa Barbara ont récemment développé une métrique et une référence diagnostique qui pourraient aider à étudier ces hallucinations, se concentrant spécifiquement sur la relation entre le raisonnement des MLLM et leur tendance à halluciner lorsqu'on leur a demandé de décrire ce qui est décrit dans une image d'entrée. Ces nouveaux outils de recherche, présentés dans un article sur le arxiv Le serveur préalable pourrait contribuer à l'évaluation et à l'avancement des MLLM.
« Le calcul du temps de test a permis aux modèles multimodaux de langue multimodale de générer des chaînes de raisonnement étendues, ce qui donne de fortes performances sur des tâches telles que le raisonnement mathématique multimodal », a écrit Chengzhi Liu, Zhongxing Xu et leurs collègues dans leur article.
« Cependant, cette capacité de raisonnement améliorée est souvent livrée avec une hallucination accrue: à mesure que les générations deviennent plus longues, les modèles ont tendance à s'éloigner du contenu fondé sur l'image et à s'appuyer plus sur les priors de la langue. »
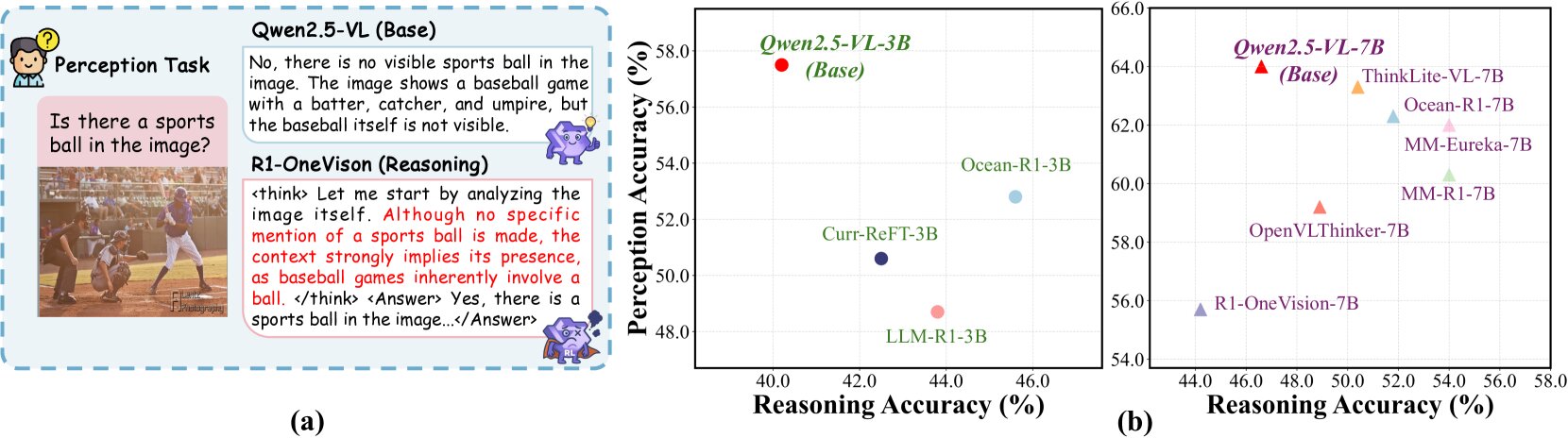
 et 7B (à droite). Des scores plus élevés indiquent une hallucination inférieure. Crédit: ARXIV (2025). Doi: 10.48550 / arxiv.2505.21523")
Les chercheurs ont d'abord évalué les performances des MLLM sur des tâches de raisonnement complexes et ont constaté qu'en tant que chaînes de raisonnement (c'est-à-dire, des séquences d'étapes logiques nécessaires pour résoudre un problème) ont augmenté, la tendance des modèles à halluner a également augmenté. Ils ont suggéré que ces hallucinations ont émergé en raison de l'attention réduite aux stimuli visuels et d'une plus grande dépendance aux priors du langage.
« L'analyse de l'attention montre que les chaînes de raisonnement plus longues conduisent à une concentration réduite sur les entrées visuelles, ce qui contribue à l'hallucination », a écrit Liu, Xu et leurs collègues.
« Pour étudier systématiquement ce phénomène, nous introduisons Rh-AUC, une métrique qui quantifie comment la précision de la perception d'un modèle change avec la longueur du raisonnement, ce qui nous permet d'évaluer si le modèle préserve la mise à la terre visuelle pendant le raisonnement. Nous libérons également Rh-Bench, une référence diagnostique qui s'étend sur une variété de tass multimodaux, conçus pour évaluer la capacité de motivation et les hallucinations. »
Rh-Auc et Rh-Bench, les métriques et les repères développés par Liu, Xu et ses collègues, pourraient bientôt être utilisés par d'autres chercheurs pour évaluer l'interaction entre les capacités de raisonnement de MLLM spécifiques et le risque d'hallucination. De plus, les observations présentées dans l'article de l'équipe pourraient guider les efforts futurs visant à développer des modèles qui peuvent s'attaquer de manière fiable à des tâches de raisonnement complexes sans devenir sujets aux hallucinations.
« Notre analyse révèle que les modèles plus importants atteignent généralement un meilleur équilibre entre le raisonnement et la perception et que cet équilibre est davantage influencé par les types et les domaines des données de formation que par son volume global », a écrit Liu, Xu et leurs collègues. « Ces résultats soulignent l'importance des cadres d'évaluation qui considèrent conjointement à la fois la qualité du raisonnement et la fidélité perceptuelle. »
Écrit pour vous par notre auteur Ingrid Fadelli, édité par Gaby Clark, et vérifié et examiné par Robert Egan – cet article est le résultat d'un travail humain minutieux. Nous comptons sur des lecteurs comme vous pour garder le journalisme scientifique indépendant en vie. Si ce rapport vous importe, veuillez considérer un don (surtout mensuel). Vous obtiendrez un sans publicité compte comme un remerciement.