
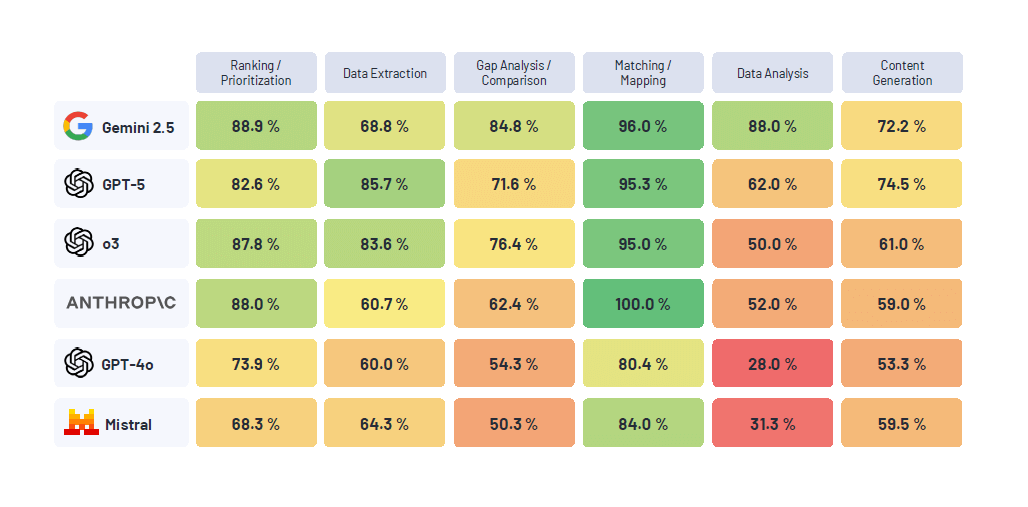
Comment les évaluations stimulent l’introduction de l’IA dans les entreprises
Plus d’un million d’entreprises dans le monde utilisent désormais l’intelligence artificielle pour accroître leur efficacité et leur valeur. Malgré cela, de nombreuses organisations obtiennent des résultats qui ne répondent pas aux attentes. L’une des principales causes est l’absence d’outils permettant de traduire les objectifs stratégiques en comportements modèles fiables.
Le rôle des évaluations selon OpenAI
Dans OpenAI, l'un des outils clés est le évaluations: Méthodes pour mesurer et améliorer la capacité d'un système à répondre à des critères spécifiques. À l'instar d'un document sur les exigences d'un produit, les évaluations éliminent toute ambiguïté, rendant les objectifs concrets et réduisant les erreurs à fort impact, offrant ainsi une voie mesurable vers un retour sur investissement plus élevé.
Évaluations frontalières et évaluations contextuelles
LE évaluations des frontières ils mesurent la qualité des modèles dans divers domaines et accélèrent leur évolution. Cependant, ils ne couvrent pas toutes les nuances nécessaires aux flux opérationnels spécifiques d’une entreprise. C'est pourquoi OpenAI développe également évaluations contextuellesc'est-à-dire des évaluations conçues pour des produits, des flux de travail ou des secteurs spécifiques. C'est une approche que les chefs d'entreprise devraient également adopter, en créant des tests adaptés à leurs besoins.
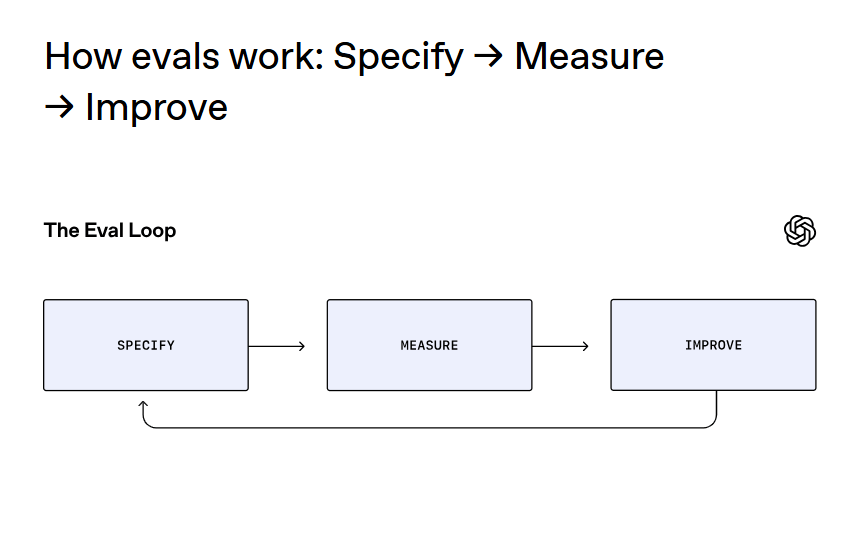
Un cadre pratique : préciser → mesurer → améliorer
Les évaluations suivent un cycle itératif et continu : définir ce que signifie « excellent », mesurer le système dans des conditions réalistes et l'améliorer en fonction des erreurs qui émergent.
1. Préciser : définir ce que signifie « grande qualité »
Tout commence avec une petite équipe possédant une expertise technique et métier, capable de décrire simplement la finalité du système d'IA : par exemple, « Convertir les e-mails qualifiés en rendez-vous, en maintenant la cohérence de la marque ».
L'équipe doit cartographier l'ensemble du flux de travail, en identifiant les points de décision et les critères de réussite. Ce processus génère un ensemble doré d'exemples, mis à jour au fil du temps, reflétant le jugement des experts sur ce qui constitue un excellent résultat.
La phase initiale est compliquée et itérative : l’analyse de 50 à 100 résultats initiaux permet de construire une « taxonomie des erreurs », une liste détaillée des problèmes à surveiller.
2. Mesurer : Tester en conditions réelles
La deuxième phase consiste à construire un environnement de test qui reflète les conditions réelles, en évitant les démos simplifiées ou les terrains de jeux rapides. Le système doit être évalué à l’aide de l’ensemble de référence, y compris les cas extrêmes qui pourraient s’avérer coûteux s’ils étaient mal gérés.
Ce sont des grilles utiles pour juger des résultats, mais elles doivent être équilibrées afin de ne pas accorder trop de poids aux détails superficiels. Dans certains cas, des mesures traditionnelles sont nécessaires ; dans d’autres, nous devons en créer de nouveaux.
Certaines notes peuvent être mises à l'échelle à l'aide d'un Évaluatrice LLMc'est-à-dire un modèle qui juge les résultats comme le ferait un expert. Mais l’intervention humaine reste essentielle pour les audits et corrections en cours. Les évaluations et la surveillance doivent se poursuivre même après le lancement du système.
3. Améliorer : apprendre de ses erreurs
L’amélioration continue est au cœur du processus. Les erreurs détectées conduisent à optimiser les invites, les données, les outils ou l'évaluation elle-même. À mesure que de nouvelles catégories d’erreurs émergent, elles sont incorporées pour créer des itérations de plus en plus raffinées.
Construire un volant d'inertie est essentiel : enregistrer les entrées et les sorties, demander à des experts d’examiner les cas ambigus et intégrer ces jugements dans le système. L’entreprise accumule ainsi un ensemble de données riche, contextuelle et difficilement réplicable, un véritable avantage concurrentiel.
Les évaluations doivent être maintenues et soulignées au fil du temps, car les objectifs, les modèles et les données évoluent également.
Evals et A/B testing : pas des alternatives, mais des alliés
Pour les applications externes, les évaluations ne remplacent pas les tests A/B classiques : elles les complètent. Chaque méthode fournit des informations complémentaires sur la manière dont les changements affectent les performances réelles.
Pourquoi les évaluations sont importantes pour les chefs d'entreprise
Chaque révolution technologique redéfinit la notion d’excellence opérationnelle. Si les OKR et les KPI représentaient la boussole à l’ère du big data, les évaluations sont le prolongement naturel de l’ère de l’IA.
Travailler avec des systèmes probabilistes nécessite de nouvelles formes de mesure et compromis plus complexe. La précision n’est pas toujours nécessaire ; parfois, vous avez besoin de flexibilité. Mais la clarté sur les objectifs est toujours nécessaire.
Les évaluations nécessitent rigueur, vision et capacités qualitatives : si elles sont bien mises en œuvre, elles deviennent un avantage concurrentiel unique, transformant le savoir-faire de l'entreprise en un atout évolutif.
À la base, les évaluations enseignent une leçon clé : les compétences en gestion sont également des compétences en IA. Fixer des objectifs clairs, donner du feedback, faire preuve de jugement sont des compétences encore plus importantes à l’ère des modèles génératifs.
Bien que les frameworks soient encore en évolution, vous pouvez déjà vous lancer : définir le problème, identifier un expert du domaine, constituer une petite équipe et, si vous travaillez avec les API OpenAI, consulter la documentation de la plateforme.