
Comment l'architecture LLM et les données de formation façonnent le biais de position de l'IA
La recherche a montré que les modèles de langues importants (LLMS) ont tendance à surestimer les informations au début et à la fin d'un document ou d'une conversation, tout en négligeant le milieu.
Ce « biais de position » signifie que si un avocat utilise un assistant virtuel propulsé par LLM pour récupérer une certaine phrase dans un affidavit de 30 pages, le LLM est plus susceptible de trouver le bon texte s'il est sur les pages initiales ou finales.
Les chercheurs du MIT ont découvert le mécanisme derrière ce phénomène.
Ils ont créé un cadre théorique pour étudier comment l'information traverse l'architecture d'apprentissage automatique qui forme l'épine dorsale de LLMS. Ils ont constaté que certains choix de conception qui contrôlent comment le modèle traite les données d'entrée peut provoquer un biais de position.
Leurs expériences ont révélé que les architectures du modèle, en particulier celles affectant la façon dont les informations sont réparties sur les mots d'entrée dans le modèle, peuvent donner lieu à ou intensifier le biais de position, et que les données de formation contribuent également au problème.
L'œuvre est publiée sur le arxiv serveur de préimprimée.
En plus de pivoter les origines du biais de position, leur cadre peut être utilisé pour le diagnostiquer et le corriger dans les futurs conceptions de modèles.
Cela pourrait conduire à des chatbots plus fiables qui restent sur le sujet lors de longues conversations, à des systèmes d'IA médicaux qui raisonnent plus équitablement lors de la gestion d'une mine de données sur les patients et des assistants de code qui accordent une attention particulière à toutes les parties d'un programme.
« Ces modèles sont des boîtes noires, donc en tant qu'utilisateur LLM, vous ne savez probablement pas que le biais de position peut rendre votre modèle incohérent. Vous lui alimentez simplement vos documents dans tous les commandes que vous voulez et s'attendre à ce qu'il fonctionne. Mais en comprenant le mécanisme sous-jacent de ces modèles de boîte noire, nous pouvons les améliorer Systèmes de décision (liouges) et premier auteur du journal.
Ses co-auteurs incluent Yifei Wang, un MIT Postdoc; et les auteurs principaux Stefanie Jegelka, professeur agrégé de génie électrique et informatique (CEE) et membre de l'IDSS et du Laboratoire d'intelligence informatique et artificielle (CSAIL); et Ali Jadbabaie, professeur et chef du Département de génie civil et environnemental, membre de base du corps professoral de l'IDSS et chercheur principal dans les couvercles. La recherche sera présentée à la Conférence internationale sur l'apprentissage automatique.
Analyser l'attention
Les LLM comme Claude, Llama et GPT-4 sont alimentées par un type d'architecture de réseau neuronal connu sous le nom de transformateur. Les transformateurs sont conçus pour traiter les données séquentielles, codant pour une phrase en morceaux appelés jetons, puis apprendre les relations entre les jetons pour prédire quels mots viennent ensuite.
Ces modèles sont devenus très bons à ce sujet en raison du mécanisme d'attention, qui utilise des couches interconnectées de nœuds de traitement des données pour donner un sens au contexte en permettant aux jetons de se concentrer sélectivement sur ou à s'occuper de jetons connexes.
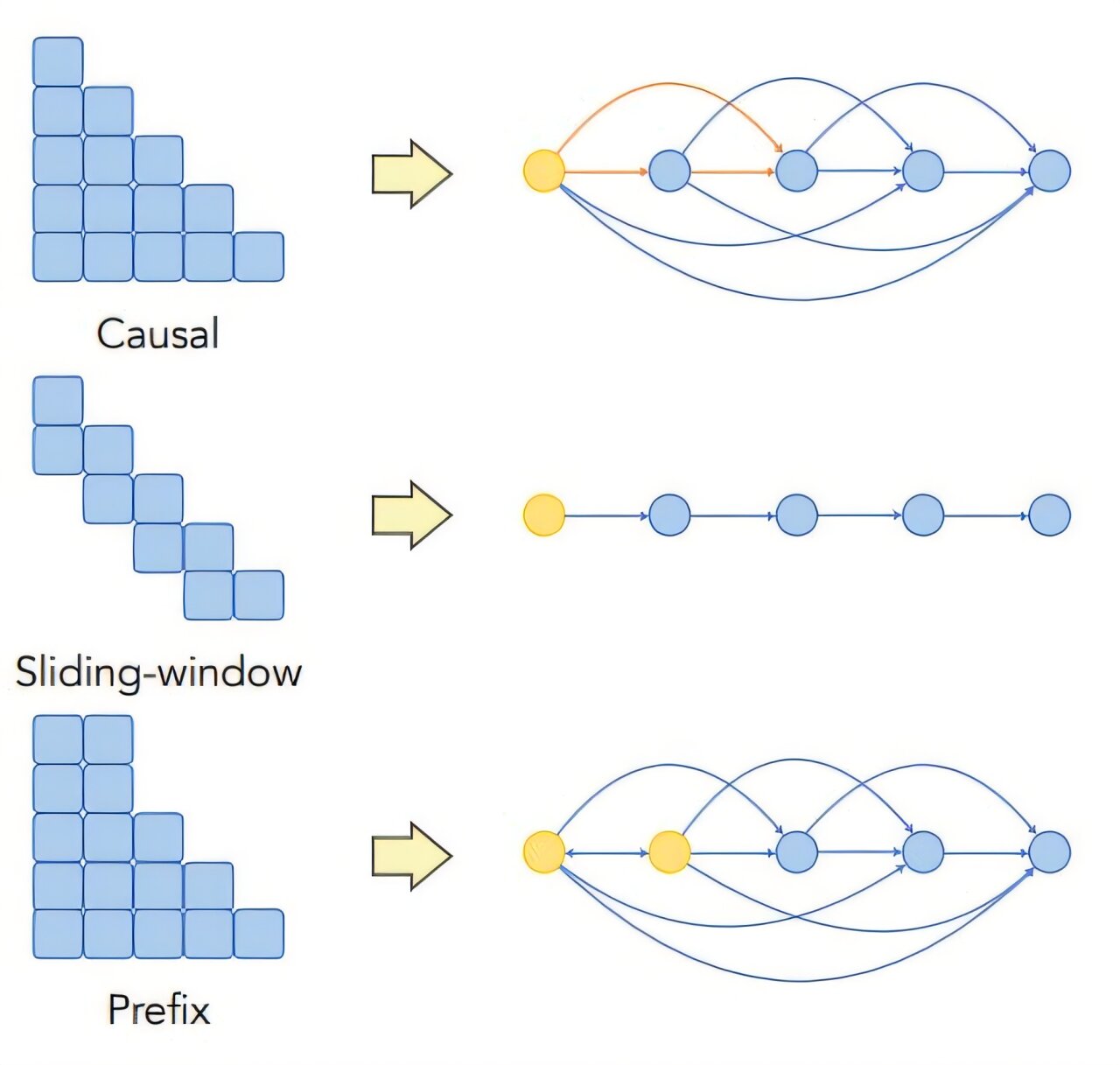
Mais si chaque jeton peut s'occuper de tous les autres jetons dans un document de 30 pages, cela devient rapidement intraitable. Ainsi, lorsque les ingénieurs construisent des modèles de transformateurs, ils emploient souvent des techniques de masse d'attention qui limitent les mots auxquels un jeton peut y assister. Par exemple, un masque causal permet uniquement aux mots de s'occuper de ceux qui l'ont précédé.
Les ingénieurs utilisent également des encodages de position pour aider le modèle à comprendre l'emplacement de chaque mot dans une phrase, améliorant les performances.
Les chercheurs du MIT ont construit un cadre théorique basé sur des graphiques pour explorer comment ces choix de modélisation, masques d'attention et codages de position pourraient affecter le biais de position.
« Tout est couplé et emmêlé dans le mécanisme d'attention, il est donc très difficile d'étudier. Les graphiques sont un langage flexible pour décrire la relation dépendante entre les mots dans le mécanisme d'attention et les tracer sur plusieurs couches », explique Wu.
Leur analyse théorique a suggéré que le masquage causal donne au modèle un biais inhérent vers le début d'une entrée, même lorsque ce biais n'existe pas dans les données.
Si les mots antérieurs sont relativement peu importants pour la signification d'une phrase, le masquage causal peut faire en sorte que le transformateur accorde plus d'attention à son début de toute façon.
« S'il est souvent vrai que les mots antérieurs et les mots ultérieurs d'une phrase sont plus importants, si un LLM est utilisé sur une tâche qui n'est pas une génération de langage naturel, comme le classement ou la récupération de l'information, ces biais peuvent être extrêmement nuisibles », explique Wu.
À mesure qu'un modèle se développe, avec des couches supplémentaires de mécanisme d'attention, ce biais est amplifié car les parties antérieures de l'entrée sont utilisées plus fréquemment dans le processus de raisonnement du modèle.
Ils ont également constaté que l'utilisation d'encodages de position pour relier les mots plus fortement aux mots à proximité peut atténuer le biais de position. La technique recentre l'attention du modèle au bon endroit, mais son effet peut être dilué dans des modèles avec plus de couches d'attention. Ces choix de conception ne sont qu'une cause de biais de position – certaines peuvent provenir des données de formation que le modèle utilise pour apprendre à hiérarchiser les mots dans une séquence.
« Si vous savez que vos données sont biaisées d'une certaine manière, vous devez également Finetune votre modèle en plus d'ajuster vos choix de modélisation », explique Wu.
Perdu au milieu
Après avoir établi un cadre théorique, les chercheurs ont effectué des expériences dans lesquelles ils variaient systématiquement la position de la bonne réponse dans les séquences de texte pour une tâche de récupération de l'information.
Les expériences ont montré un phénomène « perdu dans le milieu », où la précision de la récupération a suivi un motif en U. Les modèles fonctionnaient mieux si la bonne réponse était située au début de la séquence. Les performances ont diminué, il se rapproche du milieu avant de rebondir un peu si la bonne réponse était vers la fin.
En fin de compte, leur travail suggère que l'utilisation d'une technique de masquage différente, l'élimination des couches supplémentaires du mécanisme d'attention ou l'utilisation stratégique des codages positionnels pourrait réduire le biais de position et améliorer la précision d'un modèle.
« En faisant une combinaison de théorie et d'expériences, nous avons pu examiner les conséquences des choix de conception de modèles qui n'étaient pas clairs à l'époque. Si vous souhaitez utiliser un modèle dans des applications à enjeux élevés, vous devez savoir quand cela fonctionnera, quand il ne le fera pas et pourquoi », dit Jadbabaie.
À l'avenir, les chercheurs souhaitent explorer davantage les effets des encodages positionnels et étudier comment le biais de position pourrait être stratégiquement exploité dans certaines applications.
« Ces chercheurs offrent une lentille théorique rare dans le mécanisme d'attention au cœur du modèle de transformateur. Ils fournissent une analyse convaincante qui clarifie les bizarreries de longue date dans le comportement du transformateur, montrant que les mécanismes d'attention, en particulier avec les masques causaux, biaisment des modèles de biais vers le début des séquences. Saberi, professeur et directeur du Stanford University Center for Computational Market Design, qui n'était pas impliqué dans ce travail.