
Comme les humains, Chatgpt favorise les exemples et les «souvenirs», pas les règles, pour générer un langage
Une nouvelle étude dirigée par des chercheurs de l’Université d’Oxford et de l’Institut Allen pour l’IA (AI2) a trouvé que les modèles de grande langue (LLMS) – les systèmes d’IA derrière des chatbots comme Chatgpt – généralisent les modèles de langage d’une manière étonnamment humaine: par analogie plutôt que de règles grammaticales strictes.
L’œuvre est publiée dans la revue Actes de l’Académie nationale des sciences.
La recherche remet en question une hypothèse répandue sur les LLM: qu’ils apprennent à générer un langage principalement en déduisant les règles de leurs données de formation. Au lieu de cela, les modèles reposent fortement sur des exemples stockés et tirent des analogies lorsqu’ils traitent des mots inconnus, tout comme les gens.
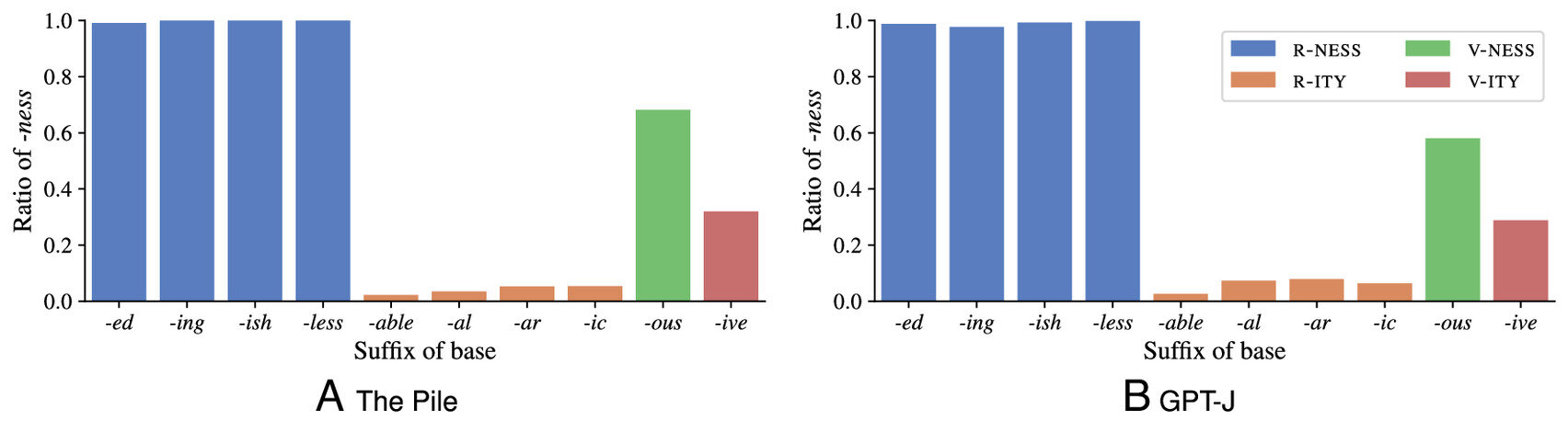
Pour explorer comment les LLM génèrent la langue, l’étude a comparé les jugements portés par les humains à ceux fabriqués par GPT-J (un modèle de grande langue open source développé par Eleutherai en 2021) sur un modèle de formation de mots très commun en anglais, qui transforme les adjectifs en noms en ajoutant le suffixe « -nEST » ou « -ity. » Par exemple, « heureux » devient « bonheur, » et « disponible » devient « disponibilité. »
L’équipe de recherche a généré 200 adjectifs anglais inventés que le LLM n’avait jamais rencontrés auparavant – des mots tels que « cormasif » et « frique. » GPT-J a été invité à transformer chacun en un nom en choisissant entre -ness et -ity (par exemple, décider entre « cormasivité » et « cormasivité »). Les réponses du LLM ont été comparées aux choix faits par les personnes et aux prédictions faites par deux modèles cognitifs bien établis. Un modèle généralise à l’aide de règles et un autre utilise un raisonnement analogique basé sur la similitude avec les exemples stockés.
Les résultats ont révélé que le comportement du LLM ressemblait à un raisonnement analogique humain. Plutôt que d’utiliser des règles, il a basé ses réponses sur des similitudes avec des mots réels qu’il avait rencontrés pendant la formation – un peu que les gens le font en pensant à de nouveaux mots. Par exemple, « frique » est transformé en « fricuise » sur la base de sa similitude avec des mots comme « égoïste, » Alors que le résultat pour « cormasif » est influencé par des paires de mots telles que sensibles, sensibilité.
L’étude a également révélé que les influences omniprésentes et subtiles de la fréquence à laquelle les formes de mots étaient apparues dans les données de formation. Les réponses de la LLM sur près de 50 000 adjectifs en anglais réels ont été sondés, et ses prédictions ont correspondant aux modèles statistiques de ses données de formation avec une précision frappante. Le LLM s’est comporté comme s’il avait formé une trace de mémoire de chaque exemple individuel de chaque mot qu’il a rencontré pendant la formation. S’appuyant sur ces souvenirs stockés pour prendre des décisions linguistiques, il semblait gérer quoi que ce soit de nouveau en se demandant: « Qu’est-ce que cela me rappelle? »
L’étude a également révélé une différence clé entre la façon dont les êtres humains et les LLMS forment des analogies sur des exemples. Les humains acquièrent un dictionnaire mental – un magasin mental de toutes les formes de mots qu’ils considèrent comme des mots significatifs dans leur langue, quelle que soit la fréquence à laquelle ils se produisent. Ils reconnaissent facilement que les formes comme le fricish et le corasive ne sont pas des mots d’anglais pour le moment. Pour faire face à ces néologismes potentiels, ils font des généralisations analogiques basées sur la variété des mots connus dans leurs dictionnaires mentaux.
Le LLMS, en revanche, généralise directement sur toutes les instances spécifiques de mots dans l’ensemble de formation, sans unifier les instances du même mot en une seule entrée de dictionnaire.
L’auteur principal Janet Pierrehumbert, professeur de modélisation linguistique à l’Université d’Oxford, a déclaré, « Bien que les LLM peuvent générer un langage de manière très impressionnante, il s’avère qu’ils ne pensent pas aussi abstraits que les humains. Cela contribue probablement au fait que leur formation nécessite beaucoup plus de données linguistiques que les humains n’ont besoin pour apprendre une langue. »
Le co-dirigeant l’auteur, le Dr Valentin Hofman (AI2 et l’Université de Washington), a déclaré, « Cette étude est un excellent exemple de synergie entre la linguistique et l’IA en tant que domaines de recherche. Les résultats nous donnent une image plus claire de ce qui se passe à l’intérieur des LLM lorsqu’ils génèrent un langage, et prendra en charge les avancées futures en IA robuste, efficace et explicable. »
L’étude a également impliqué des chercheurs de LMU Munich et de l’Université Carnegie Mellon.