
Comme les cerveaux humains, les modèles de langues importants sont des raisons de diverses données de manière générale
Alors que les premiers modèles de langue ne pouvaient traiter que du texte, les modèles contemporains de grande langue effectuent désormais des tâches très diverses sur différents types de données. Par exemple, les LLM peuvent comprendre de nombreuses langues, générer du code informatique, résoudre des problèmes mathématiques ou répondre aux questions sur les images et l’audio.
Des chercheurs du MIT ont sondé le fonctionnement interne des LLM pour mieux comprendre comment ils traitent ces données assorties et ont trouvé des preuves qu’ils partagent certaines similitudes avec le cerveau humain.
Les neuroscientifiques croient que le cerveau humain a un « hub sémantique » dans le lobe temporal antérieur qui intègre les informations sémantiques de diverses modalités, comme les données visuelles et les entrées tactiles. Ce hub sémantique est connecté à des «rayons» spécifiques à la modalité qui acheminent les informations vers le concentrateur.
Les chercheurs du MIT ont découvert que les LLM utilisent un mécanisme similaire en traitant abstraitement les données de diverses modalités de manière centrale et généralisée. Par exemple, un modèle qui a l’anglais comme langue dominante s’appuierait sur l’anglais en tant que support central pour traiter les entrées en japonais ou la raison de l’arithmétique, du code informatique, etc.
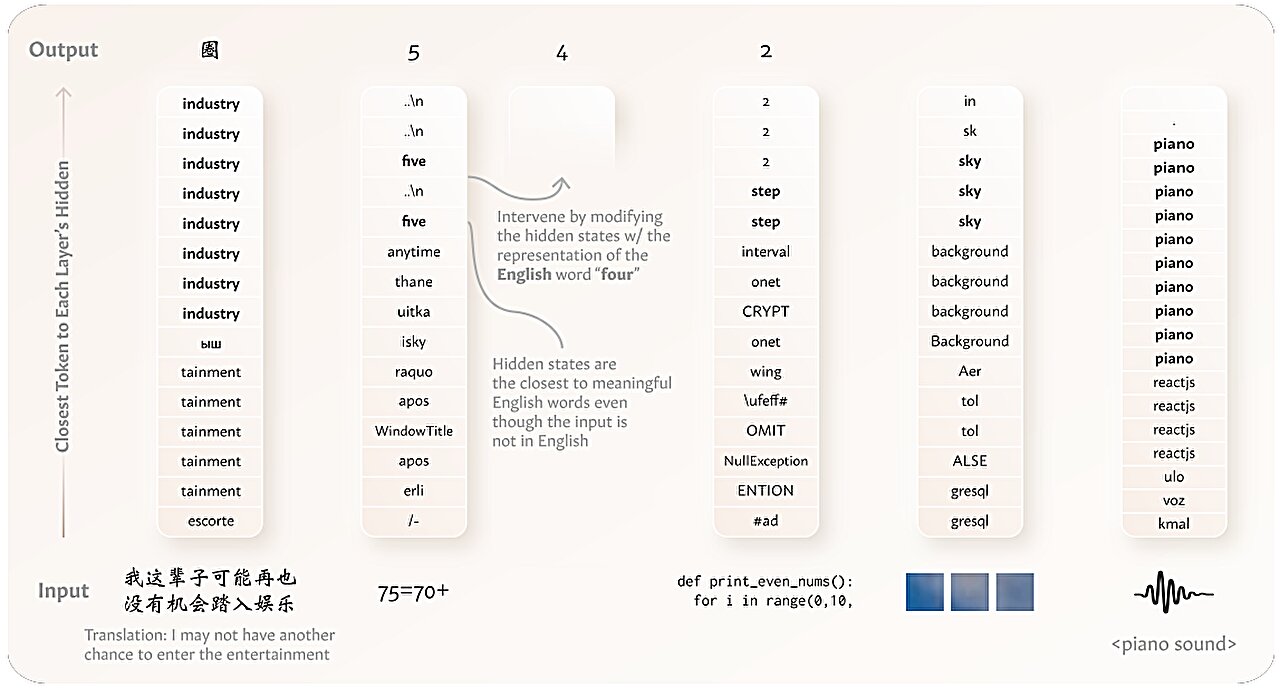
En outre, les chercheurs ont démontré qu’ils peuvent intervenir dans le centre sémantique d’un modèle en utilisant du texte dans le langage dominant du modèle pour modifier ses sorties, même lorsque le modèle traite les données dans d’autres langues.
Ces résultats pourraient aider les scientifiques à former les futurs LLM qui sont mieux en mesure de gérer diverses données.
« Les LLM sont de grandes boîtes noires. Ils ont réalisé des performances très impressionnantes, mais nous avons très peu de connaissances sur leurs mécanismes de travail internes. J’espère que cela peut être une étape précoce pour mieux comprendre comment ils fonctionnent afin que nous puissions les améliorer et mieux les contrôler En cas de besoin « , explique Zhaofeng Wu, un étudiant diplômé en génie électrique et en informatique (EECS) et auteur principal d’un article sur cette recherche publié sur la arxiv serveur de préimprimée.
Ses co-auteurs incluent Xinyan Velocity Yu, étudiant diplômé à l’Université de Californie du Sud (USC); Dani Yogatama, professeur agrégé à l’USC; Jiasen Lu, chercheuse scientifique chez Apple; et l’auteur principal Yoon Kim, professeur adjoint d’EECS au MIT et membre du Laboratoire d’intelligence informatique et d’intelligence artificielle (CSAIL). La recherche sera présentée à la Conférence internationale sur les représentations de l’apprentissage (ICLR 2025), qui s’est tenue à Singapour du 24 au 28 avril.
Intégrer diverses données
Les chercheurs ont basé la nouvelle étude sur des travaux antérieurs qui ont laissé entendre que les LLM centrées sur l’anglais utilisent l’anglais pour effectuer des processus de raisonnement sur diverses langues.
Wu et ses collaborateurs ont élargi cette idée, lançant une étude approfondie dans les mécanismes que les LLM utilisent pour traiter diverses données.
Un LLM, qui est composé de nombreuses couches interconnectées, divise le texte d’entrée en mots ou sous-mots appelés jetons. Le modèle attribue une représentation à chaque jeton, ce qui lui permet d’explorer les relations entre les jetons et de générer le mot suivant dans une séquence. Dans le cas des images ou de l’audio, ces jetons correspondent à des régions particulières d’une image ou des sections d’un clip audio.
Les chercheurs ont constaté que les couches initiales du modèle traitent les données dans sa langue ou sa modalité spécifique, comme les rayons spécifiques à la modalité dans le cerveau humain. Ensuite, le LLM convertit les jetons en représentations agnostiques de modalité car il les raisonne à leur sujet dans ses couches internes, semblable à la façon dont le centre sémantique du cerveau intègre diverses informations.
Le modèle attribue des représentations similaires aux entrées avec des significations similaires, malgré leur type de données, y compris les images, l’audio, le code informatique et les problèmes arithmétiques. Même si une image et sa légende de texte sont des types de données distincts, car ils partagent la même signification, le LLM leur attribuerait des représentations similaires.
Par exemple, un LLM dominant en anglais « pense » à une entrée de texte chinois en anglais avant de générer une sortie en chinois. Le modèle a une tendance de raisonnement similaire aux entrées non textes comme le code informatique, les problèmes mathématiques ou même les données multimodales.
Pour tester cette hypothèse, les chercheurs ont passé une paire de phrases à la même signification mais écrites dans deux langues différentes à travers le modèle. Ils ont mesuré à quel point les représentations du modèle étaient similaires pour chaque phrase.
Ensuite, ils ont mené un deuxième ensemble d’expériences où ils ont nourri un texte de modèle à dominante anglais dans une langue différente, comme le chinois, et ont mesuré à quel point sa représentation interne était similaire à l’anglais par rapport au chinois. Les chercheurs ont mené des expériences similaires pour d’autres types de données.
Ils ont constamment constaté que les représentations du modèle étaient similaires pour les phrases avec des significations similaires. De plus, sur de nombreux types de données, les jetons traités par le modèle dans ses couches internes ressemblaient davantage à des jetons centrés sur l’anglais que le type de données d’entrée.
« Beaucoup de ces types de données d’entrée semblent extrêmement différents de la langue, nous avons donc été très surpris que nous puissions sonder les greffes anglaises lorsque le modèle traite, par exemple, des expressions mathématiques ou codantes », explique Wu.
Tirer parti du centre sémantique
Les chercheurs pensent que les LLM peuvent apprendre cette stratégie sémantique du hub pendant la formation car c’est un moyen économique de traiter des données variées.
« Il existe des milliers de langues, mais beaucoup de connaissances sont partagées, comme les connaissances de bon sens ou les connaissances factuelles. Le modèle n’a pas besoin de reproduire ces connaissances entre les langues », explique Wu.
Les chercheurs ont également essayé d’intervenir dans les couches internes du modèle en utilisant du texte anglais lorsqu’il traitait d’autres langues. Ils ont constaté qu’ils pouvaient modifier de manière prévisible les sorties du modèle, même si ces sorties se trouvaient dans d’autres langues.
Les scientifiques pourraient tirer parti de ce phénomène pour encourager le modèle à partager autant d’informations que possible dans divers types de données, ce qui augmente potentiellement l’efficacité.
Mais d’un autre côté, il pourrait y avoir des concepts ou des connaissances qui ne sont pas traduites entre les langues ou les types de données, comme des connaissances culturellement spécifiques. Les scientifiques pourraient vouloir que les LLM ont des mécanismes de traitement spécifiques au langage dans ces cas.
« Comment partagez-vous au maximum chaque fois que possible, mais permettez également aux langues d’avoir des mécanismes de traitement spécifiques à la langue? Cela pourrait être exploré dans les travaux futurs sur les architectures de modèle », explique Wu.
De plus, les chercheurs pourraient utiliser ces informations pour améliorer les modèles multilingues. Souvent, un modèle dominant en anglais qui apprend à parler une autre langue perdra une partie de sa précision en anglais. Une meilleure compréhension de la hub sémantique d’un LLM pourrait aider les chercheurs à prévenir cette interférence linguistique, dit-il.
« Comprendre comment les modèles de langue traitent les entrées entre les langues et les modalités est une question clé de l’intelligence artificielle. Cet article établit une connexion intéressante avec les neurosciences et montre que l’hypothèse proposée de« l’hypothèse du hub sémantique »tient dans des modèles de langues modernes, où des représentations sémantiquement similaires de différentes données Les types sont créés dans les couches intermédiaires du modèle « , explique Mor Geva Pipek, professeur adjoint à l’École d’informatique de l’Université de Tel Aviv, qui n’était pas impliqué dans ce travail.
« L’hypothèse et les expériences bien liées et étendent les résultats des travaux précédents et pourraient avoir une influence sur les recherches futures sur la création de meilleurs modèles multimodaux et l’étude des liens entre eux et la fonction cérébrale et la cognition chez l’homme. »