

Analyse approfondie du RLHF : la relation entre l’IA et le feedback humain
Le Apprentissage par renforcement à partir de la rétroaction humaine, RLHF, est une technique qui implique une rétroaction humaine pour entraîner des modèles d’intelligence artificielle. Utilisé en Machine learning, il permet aux modèles d’apprendre de manière efficace et flexible et, comme nous le verrons, il présente quelques particularités par rapport à l’apprentissage par renforcement lui-même.
La RLHF il est utilisé dans divers domaines quien plus d’inclure des modèles linguistiques et la génération de contenu, étend sa portée au secteur des jeux.
Elle est répandue dans la création de modèles qui déterminent le succès d’entreprises telles que Anthropique, DeepMind, Google et OpenAI.
Index des sujets :
Qu’est-ce que le RLHF, ou apprentissage par renforcement à partir de la rétroaction humaine
Comme prévu, L’RLHF – qui en italien se traduit en Apprentissage par renforcement à partir des commentaires humains – est une technique de Machine Learning qui permet aux modèles d’apprendre (en fait de s’auto-apprendre) afin de mieux performer et de renvoyer des résultats plus adaptés aux objectifs.
Les techniques d’apprentissage par renforcement entraînent les logiciels à prendre des décisions qui optimisent les résultats, et dans le cas du RLHF, l’intervention humaine coïncide avec ce qui se passe. le différencie de l’apprentissage par renforcement traditionnel précisément parce qu’elle s’appuie sur le rôle de l’opérateur humain dans la fonction de performance.
Avec le RLHF – considéré comme une évolution de l’apprentissage par renforcement – un modèle est entraîné grâce à des commentaires humains, ce qui permet d’obtenir des résultats plus proches de ceux attendus, ainsi que de rendre plus efficaces les performances et la sécurité des modèles d’IA.
Bref historique et développement de la RLHF
Les origines de la RLHF mènent à OpenAI, une organisation fondée fin 2015. Dans les années qui suivent immédiatement, également grâce à la contribution de DeepMind, les premiers succès obtenus ont été documentés, affirmant que cette approche pouvait entraîner des comportements complexes avec une intervention humaine limitée. Les premiers tests ont été réalisés avec une console Atari et avec des mouvements robotisés.
Le choix de tester la RLHF avec les jeux vidéo était aussi prophétique qu’obligatoireconsidérant qu’ils constituent encore aujourd’hui à la fois un terrain d’entraînement et un terrain d’essai pour ce type d’apprentissage par renforcement.
La première version des méthodologies détaillées utilisées par le RLHF date de 2019 et, en 2022, InstructGPT formé avec le RLHF a été publiéfondamental pour le lancement de ChatGPT.
Méthodologie RLHF
Les piliers sur lesquels repose le Reinforcement Learning from Human Feedback sont essentiellement au nombre de trois et sont orientés vers l’optimisation des modèles de langage. En particulier:
- le pré-entraînement du modèle de langage
- collecte de données et formation sur le modèle de récompense
- ajuster le modèle de langage avec renforcement
Il y a trois piliers qu’il convient d’explorer un peu afin de mieux comprendre comment le RLFH accomplit sa mission.
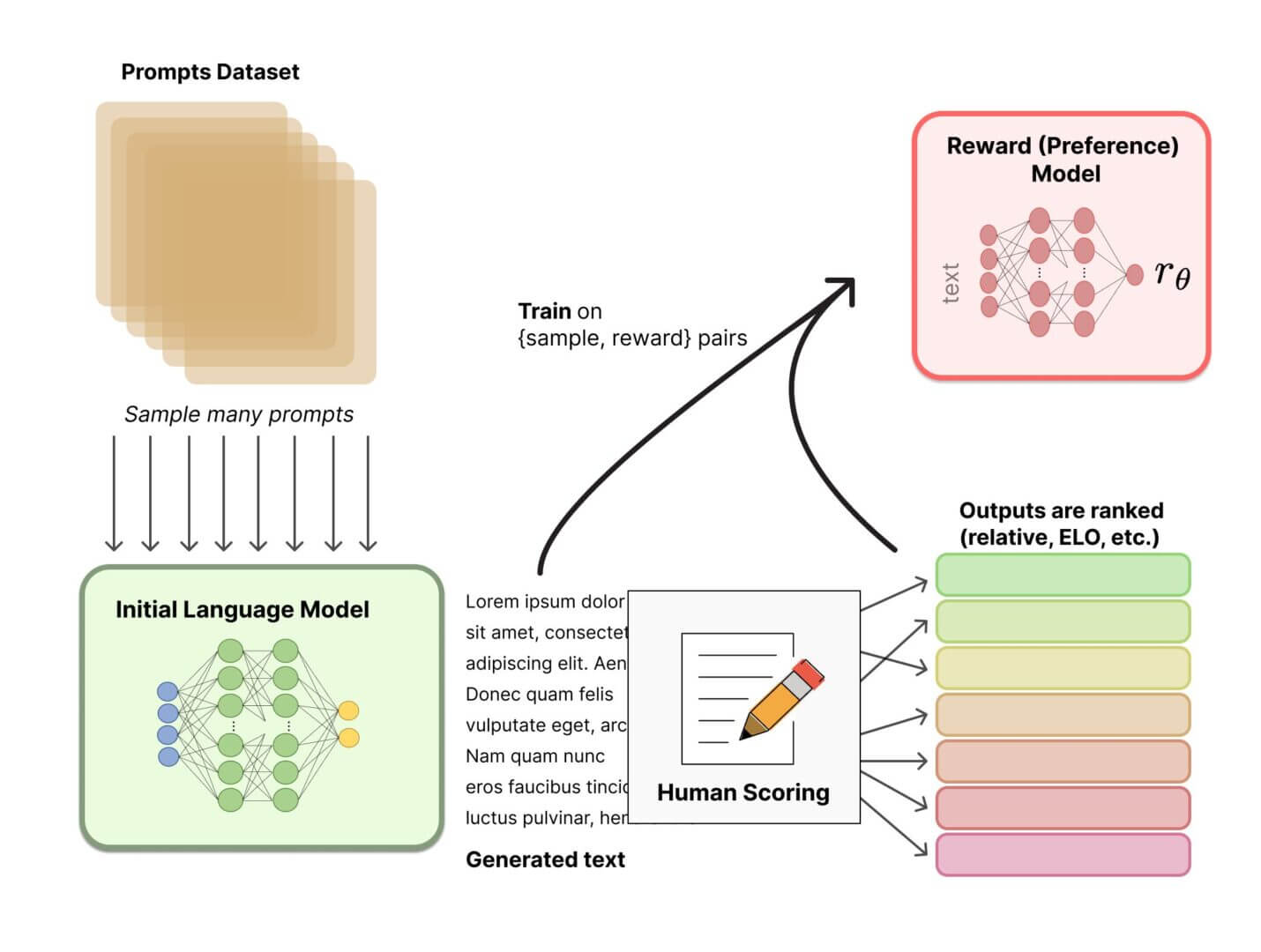
Formation de modèle de récompense
La méthodologie RLFH implique la pré-formation d’un modèle de langage (par exemple GPT ou autres modèles de type transformateur). Le modèle choisi peut être considéré comme embryonnaire et peut être perfectionné avec du texte et des conditions supplémentaires, par exemple pour faciliter l’utilisation d’un jargon spécifique ou pour renforcer les critères d’éligibilité d’un contenu, afin qu’il soit inoffensif ou en tout cas adapté au contexte.
La question qui peut se poser spontanément n’a pas (encore) de réponse définitive : il n’est pas possible d’établir avec certitude quel modèle convient le mieux comme point de départ du RLHF.

Recueillir des commentaires humains
Ensuite, vous devez calibrer le modèle de récompense en fonction des préférences humaines. Il peut être utile de prendre un peu de recul et de revoir brièvement les principes fondamentaux de l’apprentissage par renforcement.
L’apprentissage par renforcement est un sous-ensemble de l’apprentissage automatique dans lequel un algorithme (également appelé « agent ») apprend comment se comporter en recevant des récompenses ou des punitions en fonction des actions qu’il a entreprises ou des réponses qu’il a fournies. Le but ultime est que l’agent apprenne à prendre des décisions plus ciblées, c’est-à-dire que vous apprenez de vos propres expériences.
Dans le cas du feedback humain, grâce à la classification des textes, il apprend ce que les humains préfèrent. Le modèle sera donc formé à utiliser les choix humains pour apprendre.
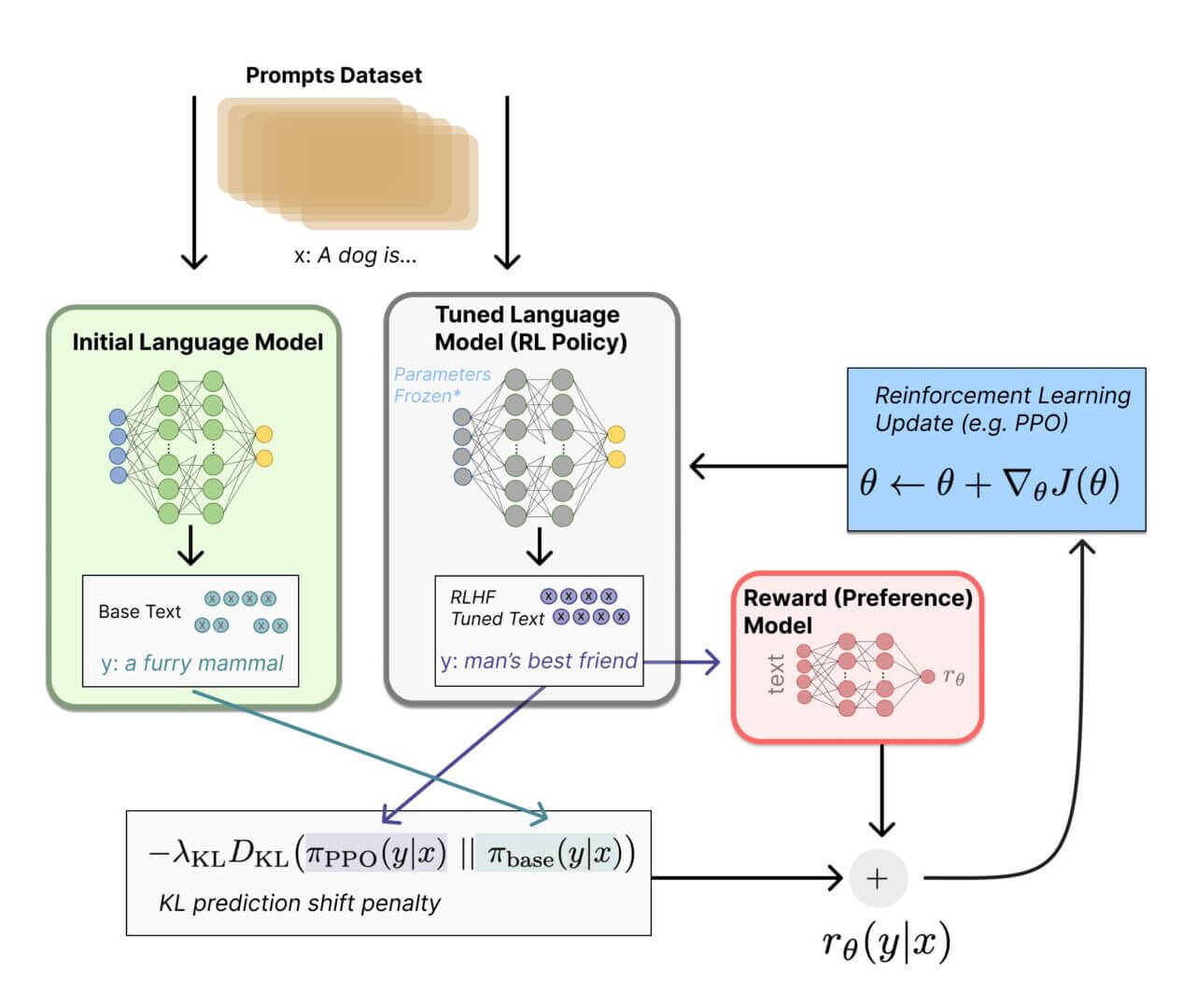
Optimisation de la politique des agents
Le modèle de langage obtenu est rendu de plus en plus centré et ponctuel grâce à l’optimisation des récompenses : le modèle apprend à améliorer les réponses sur la base du feedback humain.
La stratégie d’agent est, en fait, un modèle de langage qui renvoie un résultat par rapport à une invite en utilisant tous les jetons et toutes les séquences possibles.
Applications de l’apprentissage par renforcement à partir de la rétroaction humaine
Les applications se déploient dans différents secteurs et, ayant vocation généralement lié au monde du jeuRLHF est actuellement utilisé dans le même secteur pour créer des robots hautement compétitifs.
Il a également une place spécifique dans les voitures autonomes, notamment sur les routes très fréquentées qui constituent d’excellents terrains d’entraînement pour les modèles.
Les assistants vocaux l’utilisent pour gagner en fiabilité et en précision et, enfin et surtout, RLHF a un impact sur la génération de texte, d’images et d’audio en offrant des niveaux élevés de réalisme, renvoyant des résultats basés sur des paramètres d’entrée tels que, par exemple, l’image. détails fournis par l’utilisateur.
Cela signifie qu’il est utilisé dans les applications d’IA générative et les grands modèles de langage (LLM).
RLHF en Traitement du langage naturel
Puisqu’il est capable de rendre les modèles de langage plus évolués et donc plus flexibles et alignés sur les besoins humains, il trouve une application dans le contexte du traitement du langage naturel (NLP). Les particularités qui le distinguent sont une manne pour :
- Le assistants (et des Chatbots en général), la nécessité pour eux de s’adapter à l’usage qu’en font les humains est leur caractéristique distinctive et fondamentale
- Le résumé des textesoffrant à l’utilisateur des réponses de plus en plus performantes dans la synthèse du contenu des documents
- l’optimisation de modèles de langageun domaine dans lequel RLHF trouve une large place précisément grâce au feedback humain qui permet de mieux atteindre les objectifs préétablis
En bref, RLHF joue un rôle primordial dans l’amélioration des performances des modèles de langage et, par conséquent, favorise l’interaction homme-machine.
RLHF dans les jeux vidéo
La relation entre la RLHF et le monde du jeu vidéo, ainsi que l’apport qui en découle, est même difficile à mesurer.
L’utilisation du RLHF pour le développement de des robots capables de performances encore supérieures à celles du joueur humain est la toile de fond du succès des jeux vidéo. OpenAI et DeepMind, pour ne citer que deux géants, ils ont utilisé des jeux quand, dans leurs laboratoires respectifs, ils faisaient faire ses premiers pas à la RLHF et il semble naturel que la relation avec le monde du jeu vidéo soit restée solide au fil du temps.
Encore plus tôt, en 2008, W. Bradley Knox et Peter Stone du Département d’informatique (Université du Texas) avaient émis l’hypothèse que ce qu’on appelle aujourd’hui RLHF utilisait Tetris comme terrain d’entraînement.
Autres applications du RLHF
Les capacités de résoudre des problèmes mathématiques (même les plus complexes) ont des applications dans divers secteurs, notamment l’éducation, le divertissement, la finance et même la santé.
Pas moins, un lien stable se crée dans le domaine de la robotique avec le RLHF précisément parce que – et nous sommes confrontés à des réalités factuelles – il peut apprendre aux robots comment interagir avec les êtres humains.
Il ne faut pas non plus oublier que RLHF est une technique utilisée dans le développement de l’IA générative, mené par la diffusion, désormais presque onomatopée, par ChatGPT. Les IA génératives sont quant à elles utilisées dans de nombreux domaines comme par exemple la création de Chatbots dédiés à l’assistance client ou à la réalisation de tâches répétitives, ou encore pour apporter du support aux développeurs et programmeurs.
ChatGPT et InstructGPT d’OpenAI
Stabilité selon laquelle RLHF utilise un modèle de langage pré-entraîné, OpenAI a utilisé une version plus petite de GPT-3 pour donner naissance à InstructGPT, le premier modèle RLHF.
Alors que ChatGPT est conçu pour générer des conversations, InstructGPT a été créé pour suivre plus précisément les instructions de l’utilisateur (en particulier mieux que ce que GPT-3 était capable de faire).
Un long processus qui a été soumis à divers tests qu’OpenAI a largement documentés sur son site Internet démontrant à quel point, avec la variation des paramètres et des conditions, InstructGPT contribué à l’augmentation du potentiel des modèles GPT.
« Moineau » par DeepMind
Sparrow est un Chatbot issu des laboratoires DeepMind et conçu pour donner des réponses précises aux questions qui lui sont soumises. L’objectif est d’augmenter la qualité des interactions avec les utilisateursréduisant ainsi le risque que les résultats renvoyés soient inexacts, trompeurs ou biaisés.
Formé sur le modèle linguistique Chinchilla, il donne suite aux questions en consultant une recherche sur le Web et l’algorithme apprend en fonction de la façon dont les gens évaluent les réponses.
Plus de détails
Voici une liste des articles les plus populaires sur RLHF à ce jour.