
Algorithme basé sur les taux de compression de données sans perte LLMS
Les gens stockent de grandes quantités de données dans leurs appareils électroniques et transfèrent certaines de ces données à d’autres, que ce soit pour des raisons professionnelles ou personnelles. Les méthodes de compression des données sont donc de la plus haute importance, car elles peuvent augmenter l’efficacité des appareils et des communications, ce qui rend les utilisateurs moins dépendants des services de données cloud et des dispositifs de stockage externes.
Des chercheurs du Central China Institute of Artificial Intelligence, du Peng Cheng Laboratory, de l’Université de technologie Dalian, de l’Académie chinoise des sciences et de l’Université de Waterloo ont récemment introduit LMCOMPRESS, une nouvelle approche de compression de données basée sur des modèles de grandes langues (LLMS), tels que le modèle sous-tendant la plate-forme conversationnelle AI Chatgpt.
Leur méthode proposée, décrite dans un article publié dans Intelligence de la machine de la natures’est avéré être beaucoup plus puissant que les algorithmes de compression de données classiques.
« En janvier 2023, lorsque j’ai enseigné un cours de complexité de Kolmogorov à l’Université de Waterloo, j’ai réfléchi à l’idée que la compression est en train de comprendre », a déclaré à Tech Xplore Ming Li, auteur principal du journal. « En d’autres termes, si vous comprenez quelque chose, vous pouvez l’exprimer succinctement; et si vous pouvez exprimer quelque chose en expression très courte ou en quelques mots, alors vous devez le comprendre.
« Dans cet article: nous avons prouvé que la compression implique le meilleur apprentissage / compréhension. L’inverse a été prouvé dans l’un de nos autres articles, qui était un précurseur de ce travail, tandis qu’un autre article de Google Deepmind a obtenu indépendamment nos résultats initiaux. »
 et un concept technologique (compression). Il met en lumière le développement de technologies basées sur la compréhension, par exemple, la communication sémantique. Crédit: Li et al.")
Dans le cadre de leur étude récente, Li et ses collègues ont décidé de démontrer que les meilleurs modèles saisissent les données, mieux ils peuvent le résumer et le comprimer. Cette idée remonte à 1948, en particulier à la célèbre théorie mathématique de la communication de Claude Shannon.
« Shannon a essentiellement proposé que si vous comprenez les données à communiquer, vous pouvez la comprimer, ou en d’autres termes, raccourcir le temps de communication », a expliqué Li. « Pendant 80 ans, ce défi d’idée de recherche est resté ouvert, jusqu’à ce que l’IA et les modèles de langage grand arrivent. Notre article propose essentiellement que si un modèle de langue large peut bien comprendre les données, il doit être en mesure de deviner ce que nous prévoyons d’écrire, ce qui nous permet de compresser les données nettement mieux que les meilleurs compresseurs de données classiques sans perte (par exemple, bzip pour le texte, JPEG-2000 pour les images). »
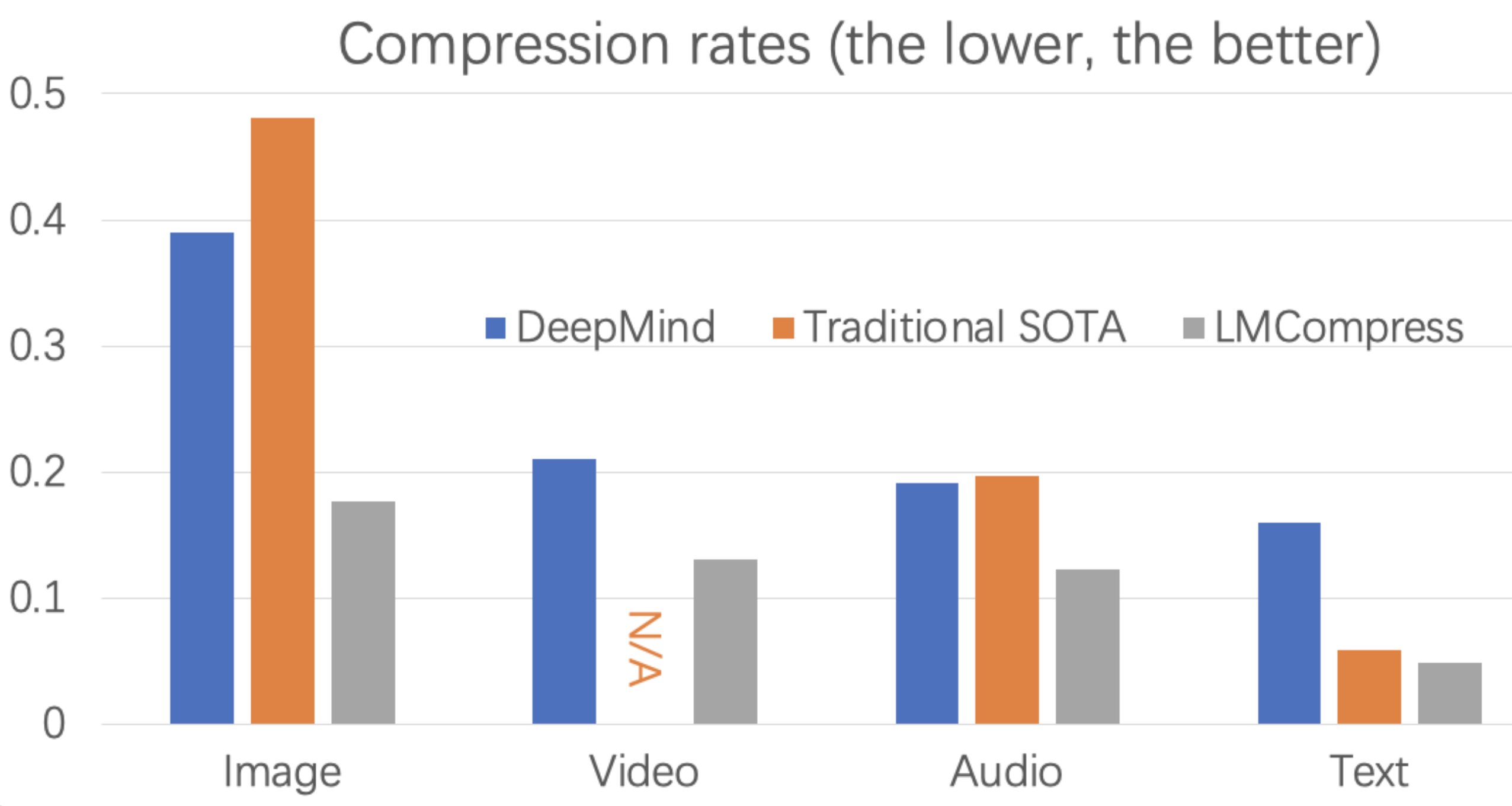
L’idée de base derrière l’algorithme de compression de données des chercheurs est que si un LLM sait ce qu’un utilisateur écrit, il n’a pas besoin de transmettre de données, mais peut simplement générer ce que l’utilisateur veut qu’ils transmettent à l’autre bout (c’est-à-dire sur l’appareil d’un récepteur). Lorsque Li et leurs collègues ont testé leur approche proposée, ils ont constaté qu’il avait au moins doublé les taux de compression pour différents types de données, y compris les textes, les images, les vidéos et les fichiers audio.
« C’est étonnant dans le sens où après 80 ans de recherche, si vous améliorez un algorithme de compression sans perte de 1%, cela est déjà remarquable, et nous avons pu doubler les taux de compression », a déclaré Li. « LMCOMPRESS est un algorithme de compression utilisant de grands modèles (modèle grand langage pour les textes, un modèle grand d’images pour les images, etc.). Il compresse les textes plus de deux fois mieux que les algorithmes classiques, les images et les audios deux fois mieux, et la vidéo un peu moins de deux fois mieux.
Ce document récent de Li et ses collègues pourrait éclairer les efforts futurs visant à développer des techniques de compression de données de plus en plus avancées, inspirant d’autres chercheurs à tirer parti des LLM. De plus, l’algorithme LMCompress de l’équipe pourrait bientôt être amélioré davantage et déployé dans des paramètres du monde réel.
« Nous avons démontré que la compréhension est égale à la compression, et nous pensons que cela est d’une importance cruciale », a ajouté Li. « Nous avons également ouvert la voie à une nouvelle ère de données de compression à l’aide de LLMS. Nous pensons à l’avenir, lorsque ces grands modèles sont sur nos téléphones portables et partout, notre méthode de compression des données remplacera les classiques (par exemple, les fichiers .zip). Dans nos prochaines études, nous prévoyons également d’utiliser notre méthodologie pour comparer les grands modèles et détecter le plagiat. »