
Un nouveau modèle réduit les biais et renforce la confiance dans la prise de décision et l’organisation des connaissances en matière d’IA
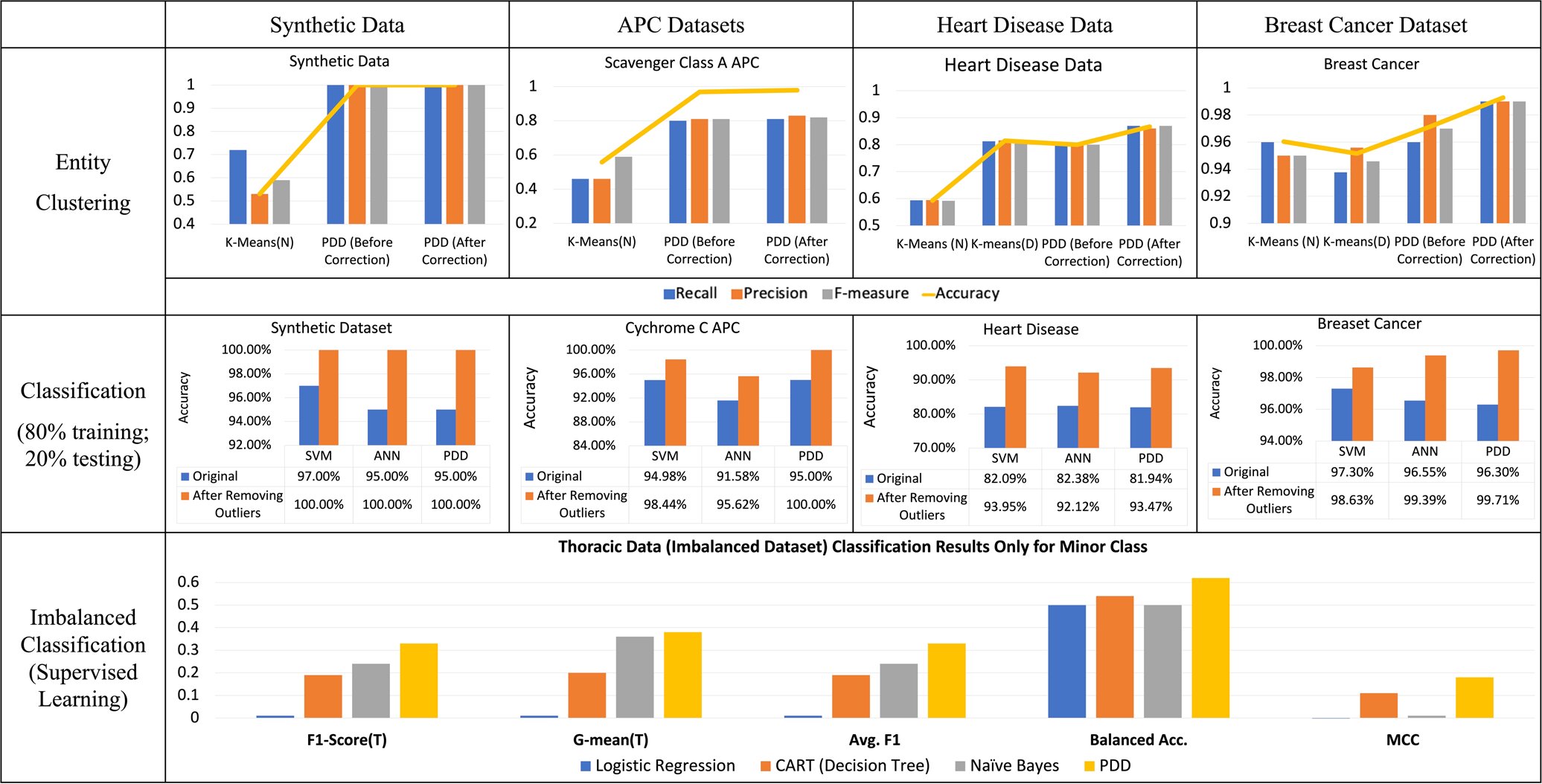
Résultats Comparaison de PDD et d’autres modèles ML . Crédit: npj Médecine numérique (2023). DOI : 10.1038/s41746-023-00816-9
Des chercheurs de l’Université de Waterloo ont développé un nouveau modèle d’intelligence artificielle (IA) explicable pour réduire les biais et améliorer la confiance et la précision dans la prise de décision et l’organisation des connaissances générées par l’apprentissage automatique.
Les modèles d’apprentissage automatique traditionnels donnent souvent des résultats biaisés, favorisant les groupes avec de grandes populations ou étant influencés par des facteurs inconnus, et nécessitent des efforts considérables pour identifier à partir d’instances contenant des modèles et des sous-modèles provenant de différentes classes ou sources primaires.
Le domaine médical est un domaine où il y a de graves implications pour les résultats d’apprentissage automatique biaisés. Le personnel hospitalier et les professionnels de la santé s’appuient sur des ensembles de données contenant des milliers de dossiers médicaux et des algorithmes informatiques complexes pour prendre des décisions critiques concernant les soins aux patients.
L’apprentissage automatique est utilisé pour trier les données, ce qui permet de gagner du temps. Cependant, des groupes de patients spécifiques présentant des schémas symptomatiques rares peuvent ne pas être détectés, et des patients et des anomalies mal étiquetés peuvent avoir un impact sur les résultats du diagnostic. Ce biais inhérent et cet enchevêtrement de modèles conduisent à des diagnostics erronés et à des résultats de soins de santé inéquitables pour des groupes de patients spécifiques.
Grâce à de nouvelles recherches dirigées par le Dr Andrew Wong, professeur émérite distingué en ingénierie de conception de systèmes à Waterloo, un modèle innovant vise à éliminer ces obstacles en démêlant les modèles complexes des données pour les relier à des causes sous-jacentes spécifiques non affectées par des anomalies et des cas mal étiquetés. Cela peut améliorer la confiance et la fiabilité dans l’intelligence artificielle explicable (XAI).
L’étude, « Theory and rationale of interpretable all-in-one pattern discovery and untanglement system », paraît dans la revue npj Médecine numérique.
« Cette recherche représente une contribution significative au domaine de XAI », a déclaré Wong. « En analysant une grande quantité de données de liaison aux protéines issues de la cristallographie aux rayons X, mon équipe a révélé les statistiques des modèles d’interaction physicochimiques des acides aminés qui étaient masqués et mélangés au niveau des données en raison de l’enchevêtrement de multiples facteurs présents dans l’environnement de liaison. C’était la première fois que nous montrions que des statistiques enchevêtrées pouvaient être démêlées pour donner une image correcte des connaissances approfondies manquées au niveau des données avec des preuves scientifiques. »
Cette révélation a conduit Wong et son équipe à développer le nouveau modèle XAI appelé Pattern Discovery and Disentanglement (PDD).
« Avec PDD, nous visons à combler le fossé entre la technologie de l’IA et la compréhension humaine pour permettre une prise de décision fiable et débloquer des connaissances plus approfondies à partir de sources de données complexes », a déclaré le Dr Peiyuan Zhou, chercheur principal de l’équipe de Wong.
La professeure Annie Lee, co-auteure et collaboratrice de l’Université de Toronto, spécialisée dans le traitement du langage naturel, prévoit l’immense valeur de la contribution du TED à la prise de décision clinique.
Le modèle PDD a révolutionné la découverte de modèles. Diverses études de cas ont présenté le TED, démontrant une capacité à prédire les résultats médicaux des patients en fonction de leurs dossiers cliniques. Le système PDD peut également découvrir des modèles nouveaux et rares dans les ensembles de données. Cela permet aux chercheurs et aux praticiens de détecter les erreurs d’étiquetage ou les anomalies dans l’apprentissage automatique.
Le résultat montre que les professionnels de la santé peuvent établir des diagnostics plus fiables étayés par des statistiques rigoureuses et des modèles explicables pour de meilleures recommandations de traitement pour diverses maladies à différents stades.