

Deep Learning pour la prise de décision dans l’incertitude
Une chose que nous avons apprise de nos clients est qu’ils ont souvent besoin de plus que des prédictions ponctuelles pour prendre des décisions éclairées. Un exemple de telles prédictions ponctuelles serait une prévision de température (régression). Mais que se passerait-il si, en plus de la température attendue, nous voulions prédire la probabilité pour chaque température ? Dans ce cas, nous utiliserions des prédictions distributionnelles. Mais bon nombre des modèles d’apprentissage automatique les plus puissants ne produisent pas de distributions dans leurs prédictions. Simseo repousse une fois de plus les limites de ce qui est possible pour fournir cette capacité importante à nos clients. Dans cet article, nous mettrons en évidence une approche simple, mais puissante, de la modélisation dans l’incertitude : régression quantile.
Simseo prend déjà en charge les probabilités de classe pour la prédiction multiclasse. Nous proposons également des intervalles de prédiction pour les séries chronologiques. Les intervalles de prédiction donnent une plage de valeurs pour l’ensemble de la distribution des observations futures. Ils sont souvent appliqués dans des domaines tels que la finance et l’économétrie. La régression distributionnelle va plus loin que les intervalles de prédiction. Il estime la distribution de la variable cible pour chaque prédiction. Une autre façon de modéliser la distribution conditionnelle est la régression quantile. Comme son nom l’indique, il estime une sélection de quantiles. C’est plus simple à faire que les prédictions distributionnelles, mais cela nous aide à estimer la distribution complète.
Petit rappel : un quantile divise les valeurs en sous-ensembles de la taille donnée. Par exemple, pour q=0,5, le quantile est la médiane et 50 % des points de données sont en dessous et 50 % sont au-dessus du quantile. Pour q=0,99, nous avons le 99e centile et seulement 1 % des données sont au-dessus de cette ligne.

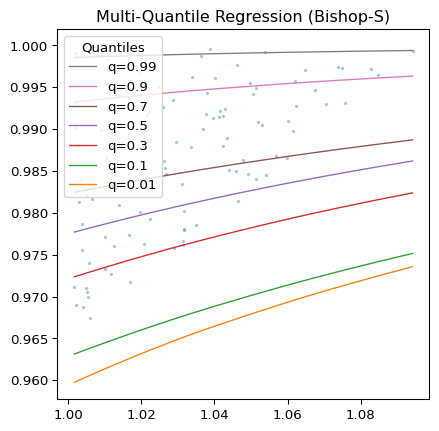

L’image 1 montre les résultats d’une régression quantile à l’aide du package Python deepquantiles et de l’ensemble de données Bishop-S.1 L’image 2 effectue un zoom dans le coin supérieur droit du graphique de l’image 1. Ici, la distribution est assez hétéroscédastique, mais le modèle évite avec succès les croisements de quantiles. L’image 3 montre que les quantiles, comme prédit par le modèle, séparent notre échantillon de test aléatoire selon les besoins.
Deep Learning pour la régression quantile
Il existe de nombreuses façons d’intégrer l’incertitude dans les prévisions. Par exemple, des exemples classiques de modélisation sous incertitude sont les modèles de séries chronologiques, tels que ARIMA2 et GARCH3 ou, plus récemment, NGBoost.4 Mais que se passe-t-il si vous souhaitez utiliser un modèle différent qui correspond à votre problème, ou peut-être un modèle plus performant ? Les modèles d’apprentissage en profondeur peuvent aider à la modélisation dans l’incertitude de diverses manières. Par exemple, un modèle d’apprentissage en profondeur distinct pourrait apprendre à prédire les quantiles en fonction des prédictions d’un modèle sous-jacent. Ainsi, nous pourrions ajouter des quantiles à toutes sortes de modèles intéressants qui ne le prennent pas en charge par défaut. Dans un premier temps, mon collègue, Peter Prettenhofer, et moi avons exploré dans quelle mesure les modèles d’apprentissage en profondeur prédisent directement les quantiles de diverses distributions cibles, et non en plus des prédictions d’un autre modèle.
Dans le passé, les praticiens évitaient les modèles d’apprentissage en profondeur pour la modélisation de l’incertitude. Les modèles d’apprentissage en profondeur étaient difficiles à interpréter, sensibles aux hyperparamètres et nécessitaient beaucoup de données et de temps de formation. Maintenant, l’architecture du transformateur5 est à l’honneur et propulse des outils à succès comme ChatGPT. Il y a quelques années, l’architecture de transformateur était principalement utilisée pour construire de grands modèles de langage (LLM). Maintenant, il est clair qu’il peut également être utilisé avec des données tabulaires.6
Dans nos recherches, nous avons adapté deux solutions existantes à nos fins pour les comparer avec les quantiles que nous obtenons des distributions prédites de NGBoost en utilisant la fonction de point de pourcentage :
- Un régresseur multi-quantile personnalisé, DeepQuantiles, avec une architecture similaire au régresseur multi-quantile du package Python deepquantiles. Ceci est un exemple pour un réseau neuronal multicouche classique.
- Le FT Transformer,7 qui utilise l’architecture du transformateur comme dans les grands modèles de langage à la pointe de la technologie, mais avec un tokenizer spécial pour les données numériques et catégorielles.
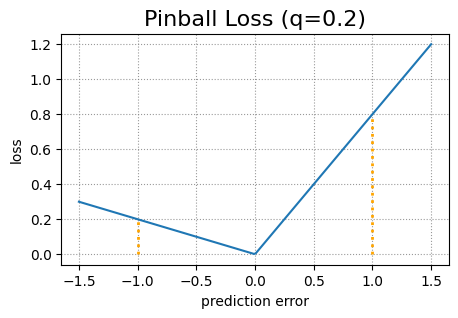
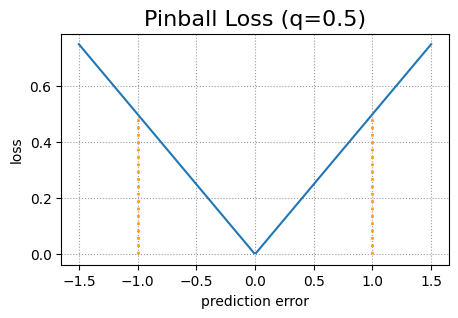
Les deux modèles d’apprentissage en profondeur utilisent une fonction de perte de flipper modifiée pour mieux faire face au problème des croisements de quantiles. La fonction de perte de flipper originale est une fonction de perte standard utilisée pour la régression quantile. Il se compose de deux parties. Soit y la vraie valeur cible et ŷ la valeur cible prédite. Alors la perte de flipper pour un quantile donné q est (1 – q)(ŷ – y) dans le cas y < ŷ et q(y – ŷ) dans le cas y ≥ ŷ.
Comparaison
Vous trouverez ci-dessous les résultats de huit ensembles de données accessibles au public souvent utilisés pour l’analyse de régression avec des variables numériques et catégorielles et 506 à 11934 lignes.
| IDENTIFIANT | # Lignes | # Catégorique | # Numérique | # Valeurs |
| ames-logement | 1 460 | 43 | 37 | 116 800 |
| béton | 1 030 | 0 | 8 | 8 240 |
| énergie | 768 | 0 | 8 | 6 144 |
| logement | 506 | 0 | 13 | 6 578 |
| kin8nm | 8 192 | 0 | 8 | 65 536 |
| naval | 11 934 | 0 | 16 | 190 944 |
| pouvoir | 9 568 | 0 | 4 | 38 272 |
| vin | 1599 | 0 | 11 | 17 589 |
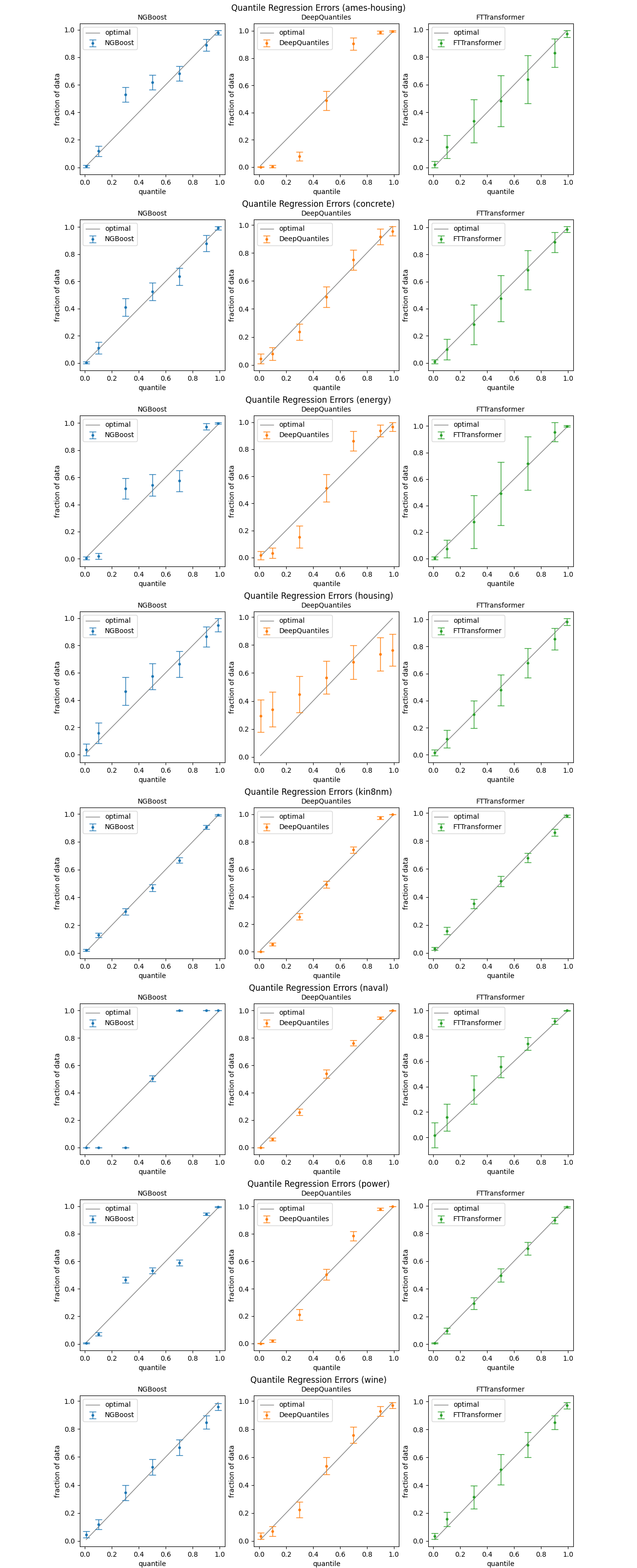
Les graphiques ci-dessous montrent les performances hors échantillon pour les trois modèles NGBoost, DeepQuantiles et FTTransformer. Nous avons choisi les quantiles 0,01, 0,1, 0,3, 0,5, 0,7, 0,9 et 0,99. Pour chaque modèle, nous avons effectué une validation croisée de 20 fois avec 5 répétitions. Cela signifie 100 exécutions par jeu de données. Les points représentent les quantiles moyens prédits. Les barres d’erreur sont les écarts-types, pas les erreurs-types.
Observations
NGBoost fait un travail décent mais, apparemment, a quelques problèmes avec certains ensembles de données (ames-housing, energy, naval, power). DeepQuantiles semble être un peu plus fort mais déçoit également dans quelques cas (ames-housing, énergie, logement). Le FTTransformer donne de très bons résultats en moyenne mais avec une énorme variance.
Un inconvénient de NGBoost est qu’il nous oblige à spécifier le type de distribution à l’avance. Nous n’avons fait aucune hypothèse supplémentaire et n’avons utilisé que la distribution normale par défaut. Cela pourrait être la raison pour laquelle NGBoost fonctionne plutôt mal sur certains ensembles de données. Etant donné que les performances de DeepQuantiles sont assez sensibles au choix de ses hyperparamètres, ce n’est pas une bonne alternative à NGBoost. Dans de nombreuses situations, un ensemble de FTTransformers pourrait être un bon moyen de faire une régression quantile. Le modèle est également peu sensible au choix des hyperparamètres et s’entraîne assez rapidement.
Conclusion
Nous cherchons constamment à mettre en œuvre les apprentissages de nos clients chez Simseo, et la modélisation dans l’incertitude est sans aucun doute une capacité très importante que nous explorons. Dans cette recherche, nous avons vu que la régression quantile est un moyen simple de faire de la modélisation dans l’incertitude et que l’architecture du transformateur semble être utile pour cette application. L’apprentissage en profondeur a même le potentiel d’améliorer les modèles de régression Simseo qui manquent actuellement de cette capacité. Restez à l’écoute, car nous mettons en évidence encore plus d’innovations et de recherches en cours chez Simseo.
1 Reconnaissance de formes et apprentissage automatique, Christopher M. Bishop, Springer, 2007.
2 Analyse des séries chronologiques : prévision et contrôle, Jenkins, Gwilym M., et al. Wiley, 2015.
3 Hétéroscédasticité conditionnelle autorégressive généralisée, Tim Bollerslev, Journal of Econometrics, vol. 31, non. 3, 1986, pages 307-327.
4 arXiv, NGBoost : amplification du gradient naturel pour la prédiction probabiliste, Tony Duan, et al. 2019.
5 arXiv, L’attention est tout ce dont vous avez besoin, Ashish Vaswani, et al. Juin 2017.
6 arXiv, Revisiting Deep Learning Models for Tabular Data, Yury Gorishniy, et al. Juin 2021.
7 Idem