
Qui poursuit qui en IA : la carte des 100 procès qui explique tout
Pour que ChatGPT, Gemini ou Meta AI répondent bien à l’énorme nombre de questions que leurs utilisateurs posent chaque jour, des années avant que les entreprises derrière eux ne prennent une décision : obtenir des données à tout prix et de n’importe où. Livres, articles de journaux, paroles de chansons, illustrations, code source. Son postulat était clair : il valait mieux demander pardon que demander la permission.
Ainsi, aujourd’hui, les tribunaux regorgent de procès, de milliards de dollars en jeu et du modèle économique de l’IA sur le banc des accusés. Pendant des années, le piratage consistait en des individus téléchargeant des films. Aujourd’hui, ce sont les plus grandes entreprises du monde qui ont fait quelque chose de similaire, mais à grande échelle et avec une technologie qui viole structurellement ce principe. Ce que décideront les juges déterminera désormais la manière dont l’intelligence artificielle sera construite.
Tout comme vous vous préparez mieux à un examen si, en plus de suivre le livre de cours, vous allez à la bibliothèque, lisez les livres recommandés et développez d’autres lectures associées au sujet que vous examinez, les différentes équipes de recherche derrière les grands modèles d’IA ont pensé qu’avec d’énormes ensembles de données et provenant de sources variées, le résultat était meilleur. Le problème est que cet énorme volume de données ne tombe pas du ciel : ils l’ont pris sur le Web, dans les bibliothèques numériques et dans les référentiels LibGen ou Z-Library. La défense habituelle des entreprises comme OpenAI repose sur des exceptions d’utilisation équitable et d’exploration de textes et de données, garantissant qu’elles utilisent légitimement des données sans licence. Les tribunaux procèdent donc au cas par cas.
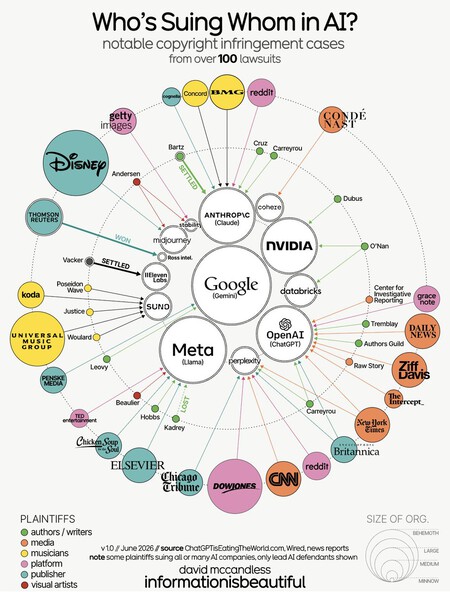
La question de savoir si la formation de modèles d’IA avec du contenu protégé constitue ou non un usage équitable est la question de droit d’auteur la plus importante à laquelle les tribunaux ont été confrontés. En fonction du résultat, les entreprises sont confrontées à un avenir sombre : payer les licences de manière rétroactive, nettoyer les bases de données et bien sûr, changer désormais la façon dont elles collectent leurs données. Et ils ont des procès à mener : plus de 100 plaintes actives en juin 2026, selon le graphique.
Il est important de noter que ce tableau concerne uniquement les tribunaux américains. En Europe, c’est une autre histoire. Le vieux continent a une réglementation plus restrictive : elle impose la suppression des données après utilisation et permet aux créateurs de réserver leurs droits. L’AI Act exige de publier les données utilisées dans la formation, ce que les entreprises ont toujours évité.
Le graphique en question est l’œuvre de David McCandless pour Information is Beautiful et a été créé à partir des données de ChatGPTisEatingTheWorld.com, des rapports Wired et des actualités de référence. Et son travail est louable : parler de contentieux n’est pas chose aisée, mais il a réussi à le synthétiser dans un seul graphique pour savoir qui poursuit qui en justice dans le monde de l’IA.
Au centre se trouvent les entreprises technologiques demandées et à l’extérieur, celles qui demandent : des écrivains aux médias, en passant par les plateformes et les artistes. Chaque catégorie est représentée par une couleur et plus le cercle est grand, plus l’entreprise est grande. Il y a aussi un avertissement : pour améliorer l’apparence du graphique, lorsqu’un plaignant a plusieurs procès en cours, seul le procès du défendeur principal est affiché. Allez, il y en a bien plus que ce que nous voyons.
Qui poursuit qui. Les informations sont belles
La carte des conflits
D’un côté, les entreprises qui ont construit des modèles d’IA, comme OpenAI, Google, Meta, Anthropic, NVIDIA et Perplexity, entre autres. De l’autre, des plaignants de toutes sortes qui prétendent que leurs œuvres ont été utilisées sans autorisation ni compensation pour entraîner des systèmes qui sont désormais devenus leurs concurrents. L’essentiel est que toutes les grandes sociétés d’IA reçoivent des demandes de presque toutes les catégories créatives. Quelques bons cas :
- Bartz contre Anthropique. La société dirigée par Dario Amodei a accepté de payer 1,5 milliard de dollars après qu’il a été démontré qu’elle avait téléchargé des centaines de milliers de livres à partir de référentiels non officiels. Le tribunal a validé la formation comme étant un usage équitable, mais pas comme la manière d’y parvenir.
- Kadrey contre Goal. L’entreprise de Mark Zuckerberg a gagné dans la partie formation, mais est toujours jugée pour avoir distribué des contenus piratés.
- New York Times contre OpenAI, toujours en cours. Le Times allègue que ChatGPT reproduit ses articles presque textuellement, remplaçant la source originale.
- Disney vs Midjourney, toujours en cours : Les grands studios de divertissement luttent contre la génération d’images.
- Concord, BMG et Universal vs. Anthropic, toujours en cours. Les grandes maisons de disques légendaires portent plainte pour reproduction de paroles protégées.
Le US Copyright Office a publié en mai 2025 un rapport de 108 pages concluant qu’il n’existe pas de réponse universelle : déterminer si l’utilisation d’œuvres pour entraîner l’IA constitue un usage loyal nécessite d’analyser chaque cas séparément. Et toutes les entreprises ne sont pas identiques, ni tous les usages.
Ce qui est clair, c’est que ce système consistant à « demander pardon plutôt que la permission » a un prix : Anthropic a montré qu’elle pouvait s’en tirer en payant 1,5 milliard de dollars parce que sa valorisation est de 183 milliards de dollars. La réponse courte est donc qu’aujourd’hui, cela en valait la peine. La question sous-jacente est de savoir si les procès continueront à se multiplier ou si des règles plus claires seront établies concernant l’utilisation des données et si quelqu’un aura la main ferme et les connaissances nécessaires pour les appliquer.
À Simseo | Qui gagne vraiment la course à l’IA, dans un graphique qui met Google en difficulté
À Simseo | L’IA va générer une richesse sans précédent. La question que tout le monde commence à se poser est : qui va rester avec elle ?