

Nous pensions qu’aucun modèle d’IA chinois ne se rapprocherait de sitôt de Fable 5 ou de GPT-5.5. Puis GLM-5.2 est arrivé
Il y a quelques jours, la startup chinoise Zhipu AI (Z.ai) a annoncé le lancement de son nouveau modèle d’IA ouvert, GLM-5.2. Il l’a fait en bénéficiant de fonctionnalités étonnantes qui le rapprochent beaucoup des meilleurs modèles fermés d’OpenAI et d’Anthropic, ce qui semblait impossible. Eh bien, plus le modèle est analysé, mieux il se porte. Nous sommes peut-être au début de quelque chose de très important. Un changement de tendance.
GLM 5.2. La startup chinoise Z.ai propose depuis longtemps différentes versions de son modèle GLM AI, mais la dernière en date est sans doute la plus surprenante car ses performances sont particulièrement prometteuses. Il compte 744 milliards de paramètres (744B), dont 40 000 restent actifs. Nous examinons un modèle avec une fenêtre contextuelle d’un million de jetons et une nouvelle architecture appelée IndexShare/IndexCache.
Mieux que GPT-5.5, très proche de l’Opus 4.8. La startup a montré à quel point les performances du GLM-5.2 sont extraordinaires dans les tâches de programmation. Dans le test FrontierSWE, le plus exigeant de ceux actuellement disponibles, GLM-5.2 a surpassé GPT-5.5 et seul Opus 4.8 était supérieur d’une très petite marge. La même chose s’est produite avec d’autres tests comme PostTrainBench ou SWE-Marathon, qui évaluent par exemple le comportement du modèle lors de très longues sessions de programmation autonome.
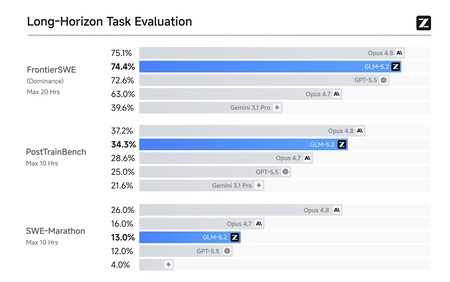
Source : Z.ai.
Dans de nombreux autres tests, la photo était identique : le modèle a fait un bond spectaculaire depuis la version 5.1, et est dans de nombreux tests presque aussi bon (voire meilleur) que les meilleurs d’OpenAI, Anthropic ou Google.
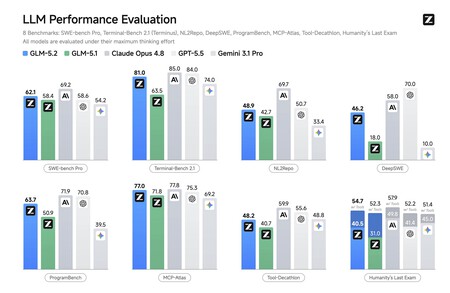
Mais il n’y a pas qu’eux qui le disent. Artificial Analysis, une société indépendante réputée qui maintient un classement mis à jour des performances des nouveaux modèles d’IA qui arrivent sur le marché, confirme les données de Z.ai lui-même. Dans ses tests, il indique que « l’indice d’intelligence » du GLM-5.2 est désormais de 51 points. Il n’est dépassé que par GPT-5.5 (55), Claude Opus 4.8 (56) et Claude Fable 5 (60).
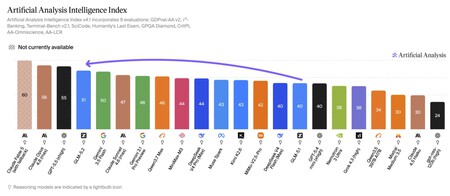
Source : Analyse artificielle.
Ce modèle ouvert chinois laisse derrière lui le nouveau Gemini 3.5 Flash, mais aussi des concurrents chinois comme Qwen 3.7 Max, MiniMax-M3 ou DeepSeek V4, entre autres. Le saut de qualité depuis GLM-5.1 est, insistons-nous, exceptionnel, bien supérieur à ce qui, du moins selon cet indice, a été observé de l’Opus 4.8 à Fable 5.
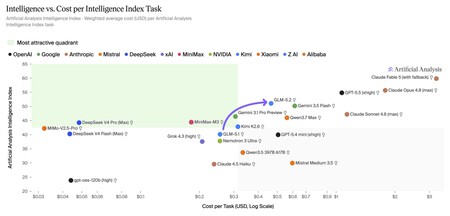
Le saut de performances est spectaculaire, même s’il est vrai que le prix comparatif pour résoudre les tâches proposées dans le benchmark augmente considérablement. Source : Analyse artificielle.
Mais ce n’est pas parfait. Le rapport d’analyse artificielle montre cependant que bien que GLM-5.2 soit très fort dans des domaines tels que la programmation, il est faible dans d’autres. Il est par exemple loin d’être aussi fiable que Fable 5, GPT-5.5, Claude 4.8 ou Gemini 3.1 Pro en termes de bonnes réponses, qui sont également inférieures proportionnellement à celles de ses concurrents. Cependant, ses hallucinations ont considérablement diminué.
Et c’est beaucoup (beaucoup) moins cher. Mais en plus d’être fantastique dans de nombreux domaines, il est bien moins cher que ses concurrents. Il maintient le prix par million de tokens d’entrée/sortie de son prédécesseur (1,4/4,4 dollars), tandis que celui du GPT-5,5 est de 5/30 dollars et celui de l’Opus 4.8 est de 10/50 dollars. Il est vrai qu’il consomme beaucoup plus de tokens que GPT-5.5 (très efficace) ou Claude Opus 4.8, mais même avec cela son coût final est bien inférieur.
Mes tests avec la programmation GLM-5.2. Je suis abonné à Z.ai depuis des mois maintenant car ils proposaient un abonnement annuel fin 2025 à un prix vraiment bas. Cela m’a permis de tester GLM-5.2 pendant quelques heures et même si je ne peux pas tirer de conclusions définitives, il semble clair qu’il y a un saut de qualité en termes de capacité de programmation. Je lui ai demandé de revoir un projet de code personnel et il a identifié en détail plusieurs failles de sécurité et améliorations possibles.
Parler avec GLM5-2. En mode conversationnel, le comportement est beaucoup plus difficile à évaluer : j’ai interagi avec le modèle et lui ai posé des questions, et bien qu’il soit meilleur que GLM 5.1 à plusieurs reprises, d’autres fois ce n’est pas tellement et je dirais qu’en termes de créativité pour écrire les modèles frontières de Google, OpenAI et surtout Anthropic, ils sont encore assez supérieurs. Vous pouvez l’essayer sur leur site internet, et là vous verrez autre chose : il met beaucoup plus de temps à répondre que les autres chatbots, car sa phase de raisonnement est plus longue. Prenez plus de temps pour répondre aux questions.
Les repères sont une chose, l’expérience en est une autre. A défaut de le tester (beaucoup) davantage, on a bien sûr l’impression que le modèle s’est nettement amélioré par rapport à un GLM-5.1 qui avait pris du retard sur ses concurrents chinois (sans parler des actuels Claude Opus 4.8 ou GPT-5.5). Sur des plateformes comme Reddit, les avis sont partagés, mais beaucoup considèrent que c’est une option fantastique pour fonctionner localement… si vous disposez d’une machine très, très puissante avec au moins 256 Go de mémoire unifiée (Mac Studio). Et une chose semble claire : lorsqu’il s’agit de l’utiliser comme modèle d’IA pour la programmation, il se rapproche étonnamment de Claude Opus 4.8.
À Simseo | Les entreprises technologiques chinoises sont entrées dans la course à l’IA avec des modèles moins chers que les autres. Cela commence à se terminer