
LifeSciBench : benchmark IA des sciences de la vie, les limites des modèles
Sept cent cinquante demandes, rédigées par des scientifiques titulaires d’un doctorat et ayant passé des années dans les laboratoires d’entreprises biotechnologiques et pharmaceutiques, chacune formulée comme on demanderait à un collègue en qui on a confiance : interpréter ces données transcriptomique spatiale d’une tumeur du col de l’utérus et dites-moi quelles sont les deux thérapies ciblées qui ont le plus de sens pour cette patiente, démonter pièce par pièce le paquet réglementaire d’une thérapie génique pour la dystrophie de Duchenne et indiquer là où ça ne tient pas, concevoir les amorces pour assembler trois fragments dans un cadre avec un Golden Gate. Sur ce matériau, le modèle le plus performant réussit 36,1% des tâches. Cent soixante et onze tâches, soit 22,8 % du total, ne sont résolues par aucun des cinq systèmes testés.
C’est le cadre qu’OpenAI a publié le 17 juin 2026 avec LifeSciBench, un benchmark qui tente de mesurer une capacité différente de ce que capturent les tests traditionnels : dans quelle mesure un modèle sait faire de la recherche dans les sciences de la vie, et non dans quelle mesure il sait comment répondre à une question de biologie. La distance entre les deux choses est le véritable contenu de la prépublication, signée par OpenAI avec Tacit Labs, et il convient de garder immédiatement à l’esprit une note que les auteurs eux-mêmes ont mise noir sur blanc : le benchmark est construit par ceux qui produisent également certains des modèles évalués, et le système qui remporte le classement est un modèle spécialisé d’OpenAI lui-même.
Pour ceux qui doivent décider où insérer ces systèmes dans un flux de recherche et développement, la photographie compte plus que le classement. Il indique où un modèle soutient le poids d’une décision scientifique et où il renvoie des réponses plausibles qu’un expert ne peut, pour l’instant, approuver.
Un examen rédigé par 173 scientifiques
Les chiffres de construction en disent déjà long. Les 750 essais ont été rédigés par 173 experts, tous titulaires d’un doctorat dans des disciplines telles que la biochimie, la biologie moléculaire, l’immunologie, la pharmacologie ou la chimie médicinale, et tous comptant au moins deux ans de travail réel au sein de l’industrie biotechnologique ou pharmaceutique. Chaque tâche est organisée comme une conversation entre collègues : une invite en langage scientifique, les artefacts nécessaires pour répondre, des séquences, des structures moléculaires, des images de microscopie, des gels, des fichiers d’instruments, des tableaux, des PDF, et une réponse libre, pas une croix.
Ce qui change la nature de l’évaluation, ce sont les rubriques. Plus de 19 000 ont été rédigés, en moyenne 25 pour chaque tâche, et chaque critère récompense ou pénalise un aspect précis de la réponse : un fait qui méritait d’être mentionné, un passage de raisonnement qui méritait d’être explicité, une valeur quantitative à centrer dans une tolérance. Le score final est la somme des points divisée par le total possible, de sorte qu’une réponse peut être partiellement créditée d’un raisonnement correct, même si elle manque la cible.
Voici ce qui distingue LifeSciBench des benchmarks à réponse courte : la même bonne conclusion est différente selon la manière dont vous y arrivez, si le modèle utilise les bonnes preuves, s’il énonce les hypothèses, s’il communique avec le degré de certitude approprié. Une réponse peut atteindre la conclusion générale et rester scientifiquement incomplète, car elle manque une mise en garde cruciale ou ne justifie pas une recommandation.
La sélection a été sévère. Chaque tâche a fait l’objet de plusieurs cycles d’examen, en moyenne six étapes automatisées et au moins deux cycles d’examen humain, avec des critères ancrés dans une réponse vérifiable ou un consensus fort parmi les experts, fixés à au moins 90 % d’accord. Puis une validation indépendante, menée par 453 évaluateurs autres que ceux qui avaient passé les tests, 97% titulaires d’un doctorat, en moyenne douze ans d’expérience et quatorze publications à leur actif. Concernant le réalisme, le respect du raisonnement requis, la solidité scientifique et l’utilité globale, l’accord global dépassait 96 % dans chaque catégorie.
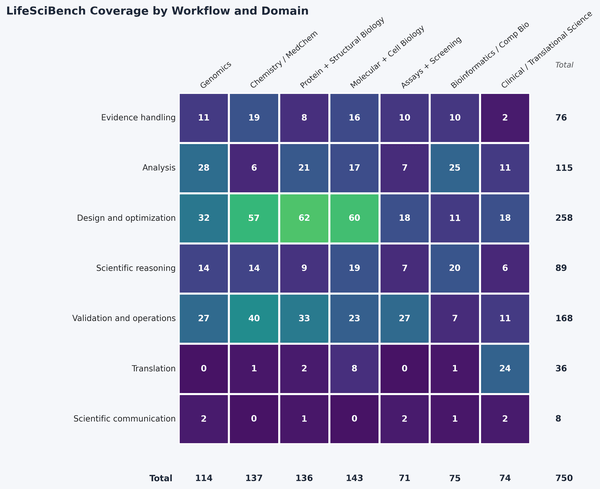
La couverture médiatique est une autre raison de prendre ces chiffres au sérieux. Les tests sont répartis sur sept flux de travail, de la gestion des preuves à l’analyse, de la conception et de l’optimisation au raisonnement, jusqu’à la validation et les opérations, la traduction et la communication scientifique, et dans sept domaines biologiques, de la génomique à la chimie médicinale, de la biologie structurale à la bioinformatique clinique. La carte de cette répartition montre où le benchmark est dense : le bloc Conception et optimisation, à lui seul, rassemble 258 tâches.
GPT-Rosalind devant, les généralistes de près
Cinq systèmes testés : GPT-5.4, GPT-5.5, GPT-Rosalind, Gemini 3.1 Pro et Grok 4.3, tous évalués en mode mono-tour, une seule réponse par tâche, sans suivi. En tête se trouve GPT-Rosalind, un modèle spécialisé dans les sciences de la vie pour lequel OpenAI a ouvert les demandes d’accès, avec un score normalisé de 0,576 et un taux de réussite de 36,1 %. Derrière, deux généralistes presque appariés, GPT-5.5 à 0,519 et Gemini 3.1 Pro à 0,515, puis GPT-5.4 à 0,479 et Grok 4.3 à 0,399.
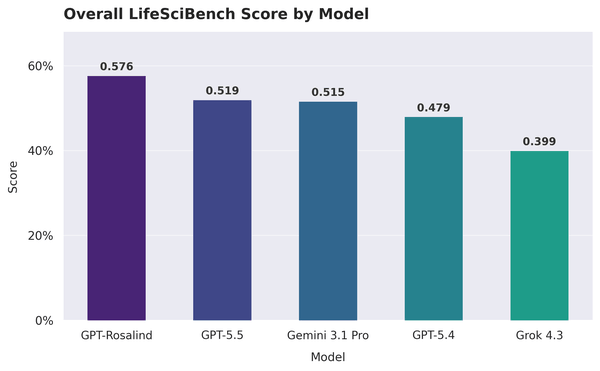
Deux choses méritent attention, en plus du classement. Le premier concerne le seuil : le taux de réussite mesure la part des tâches pour lesquelles la réponse atteint au moins 70 % des critères de la rubrique, un seuil strict, et sur cette échelle même le meilleur modèle laisse de côté près des deux tiers des essais. La seconde concerne la texture fine que cache une moyenne. GPT-Rosalind a le score le plus élevé sur 386 tâches sur 750, cependant Gemini 3.1 Pro arrive seul en tête sur 214 tests, signe d’atouts complémentaires. Un modèle globalement légèrement plus faible peut rester le plus adapté à un certain type de travail.
Le fait qu’un système construit spécifiquement pour la domination l’emporte, avant les modèles frontaliers généralistes plus récents, est un détail que ceux qui évaluent son adoption feraient bien de noter. L’écart reste cependant mesuré : dix points de taux de réussite au-dessus de GPT-5,5, sur un benchmark où le seuil de réussite est encore loin pour tout le monde.
Où les preuves ont une frontière claire
Les domaines dans lesquels les systèmes frontaliers fonctionnent mieux sont cohérents les uns avec les autres et disent quelque chose de précis. Pour les tâches de traduction, celles qui relient les preuves précliniques ou biologiques aux implications cliniques, à la sécurité et à la conception des essais, GPT-Rosalind a obtenu un score moyen de 0,712. En communication scientifique, résumer et expliquer les résultats pour un public défini, atteint 0,718, même si ici la catégorie est petite, seulement neuf tâches, et doit être lue avec prudence.
Le saut par rapport à GPT-5.5 est marqué précisément dans ces domaines. Dans le communiqué de presse, OpenAI rapporte le taux de réussite sur la communication scientifique qui passe de 56,3% à 71,1%, et celle sur la traduction qui passe de 36,8% à 57,7%. Pour les critères qui demandent des résultats utiles et exploitables pour un expert, le score varie de 29,1 % à 44,7 %, et pour ceux qui nécessitent de gérer l’incertitude et les réserves, de 29,3 % à 44,8 %.
Au niveau d’un seul critère, les plus grands gains de GPT-Rosalind par rapport à GPT-5.5 résident dans l’explication des mécanismes, la conception d’expériences et la critique ou la validation d’une analyse. Ce sont toutes des choses qui nous obligent à aller au-delà du rappel de notions, à interpréter les preuves et à peser les hypothèses pour arriver à quelque chose d’utile pour une décision. Les modèles fonctionnent mieux lorsque la tâche a une limite claire dans les preuves et exige un jugement scientifique structuré.
C’est le territoire du travailleur du savoir expérimenté, où un assistant peut vraiment alléger la charge.
Artefacts et résultats exacts : les deux limites structurelles
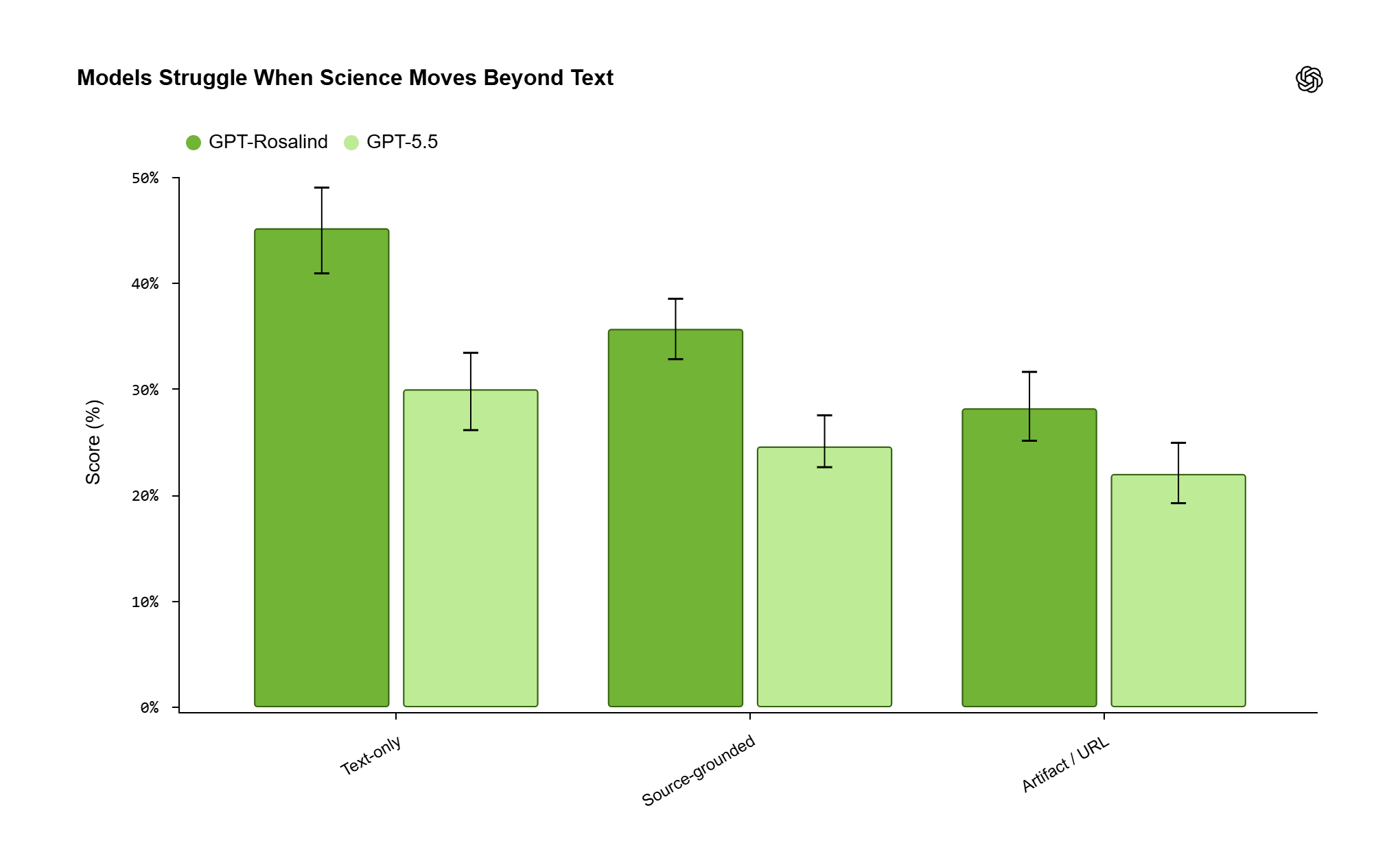
L’inconvénient réside dans le fait que les modèles deviennent peu fiables, et la leçon ici est la plus pertinente pour ceux qui travaillent avec des données réelles. Les tâches qui nécessitent la lecture d’un artefact joint, d’un fichier volumineux, d’une figure complexe, d’un ensemble de données, sont beaucoup plus difficiles que les tâches contenant uniquement du texte. Pour GPT-Rosalind, le taux de réussite passe d’environ 45 % sur les tests textuels à un peu plus de 28 % sur ceux nécessitant des artefacts ou des liens externes. GPT-5.5 montre la même courbe, d’environ 30 % à 22 %.
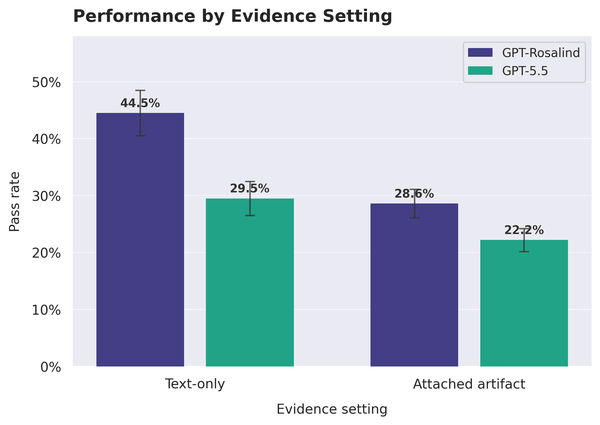
L’écart demeure même pour le meilleur modèle, et cela suffit à encadrer l’usage des artefacts comme une limite structurelle du moment. Le point de rupture survient lorsque le système doit extraire les bonnes informations d’un fichier encombrant ou d’un chiffre encombré, puis les intégrer à une décision scientifique finale.
Il existe un deuxième défaut concernant le format de réponse. Lorsque la tâche demande des résultats exacts, une séquence génomique ou une structure chimique à fournir telle quelle, les scores chutent pour tout le monde. Sur les critères de séquence et de structure, la réussite varie de 46,9% pour GPT-Rosalind à 18,0% pour Grok, sur les tâches numériques, GPT-Rosalind s’arrête à 14,8%, sur la génération de constructions à 27,3%, avec une amélioration d’un millième seulement par rapport à GPT-5.5. Les progrès, sur la base de ces preuves, se concentrent sur le raisonnement général et n’abordent presque pas l’utilisation précise de formats scientifiques spécialisés.
Et cette limitation est importante, car de nombreux flux scientifiques réels ont précisément besoin de résultats exploitables et précis : une séquence prête pour la conception d’un donneur CRISPR/HDR, une construction destinée à une étape en aval.
Entre réponse plausible et décision utilisable
Reste le phénomène le plus instructif, celui qui explique pourquoi LifeSciBench rapporte deux métriques et non une. Les modèles font souvent la moitié du chemin : ils identifient les bonnes preuves, établissent le raisonnement, puis ne concluent pas. Pour GPT-Rosalind, il y a 109 tâches avec un taux de réussite inférieur à 20 % qui ont quand même récolté au moins la moitié des points de la rubrique. Ce sont des réponses scientifiquement plausibles qui échouent pour une raison spécifique, ignorent une contrainte, utilisent des preuves erronées, laissent un calcul à moitié terminé ou ne relient pas le raisonnement intermédiaire à une conclusion utile sur le plan opérationnel.
Du point de vue de ceux qui adoptent ces systèmes, c’est la différence entre un assistant qui produit un projet crédible et un collaborateur en qui vous pouvez avoir confiance pour prendre une décision. La limite des modèles frontières réside aujourd’hui moins dans la connaissance biologique que dans la fiabilité sous les contraintes de la recherche réelle : bien utiliser les artefacts et transformer un raisonnement partiel en une décision complète qu’un expert peut réellement prendre et poursuivre.
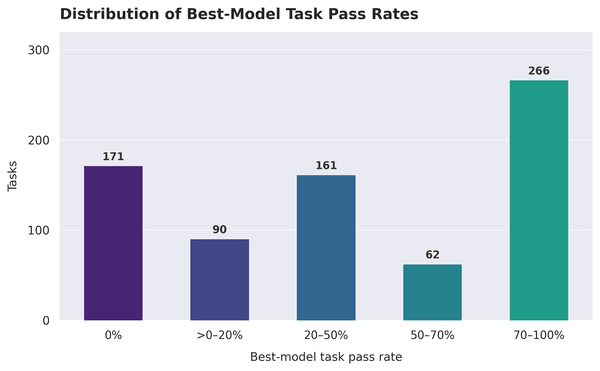
Pour ceux qui doivent adopter ces outils, la carte compte plus que le classement. Sur 750 tests, il en reste 171 qu’aucun modèle ne résout, 261 avec le meilleur taux de réussite inférieur à 20 %, et le bloc le plus difficile se concentre sur la conception, l’optimisation et l’analyse, qui représentent ensemble 60,9 % des tâches les plus difficiles. La répartition des meilleurs résultats, tâche par tâche, le montre sans mâcher ses mots.
Ce sont des domaines où la recherche requiert une précision opérationnelle, et où la collaboration entre expert et machine reste pour l’instant sous forte supervision humaine. Ce n’est pas un hasard si le même 17 juin, OpenAI parlait également d’un chimiste en IA presque autonome qui améliore une réaction difficile en chimie médicinale, résultat d’un déploiement dans un contexte délimité qui vit dans une dimension différente de celle d’un examen à tour unique.
La question qui reste ouverte concerne moins la valeur de ce classement, voué à changer avec la prochaine version, que la traduction : dans quelle mesure les progrès mesurés sur un test en un seul tour se transforment en productivité au sein d’un laboratoire, où le travail est itératif, fait de clarifications continues et de nouvelles expériences de vérification. Les auteurs eux-mêmes le reconnaissent et indiquent la direction, en corrélant les résultats du benchmark avec les études de déploiement dans des flux de recherche réels.
En attendant que ce pont soit construit, les données à garder à l’esprit sont moins le score du modèle phare que plus de 22,8 % des devoirs que personne ne rapporte à la maison aujourd’hui. Et c’est sans doute à partir de là qu’il vaut la peine de s’intéresser à la prochaine génération de modèles : quelle part de cette marge pourront-ils réduire, et quelle part continueront-ils à demander la main d’un vrai scientifique ?