

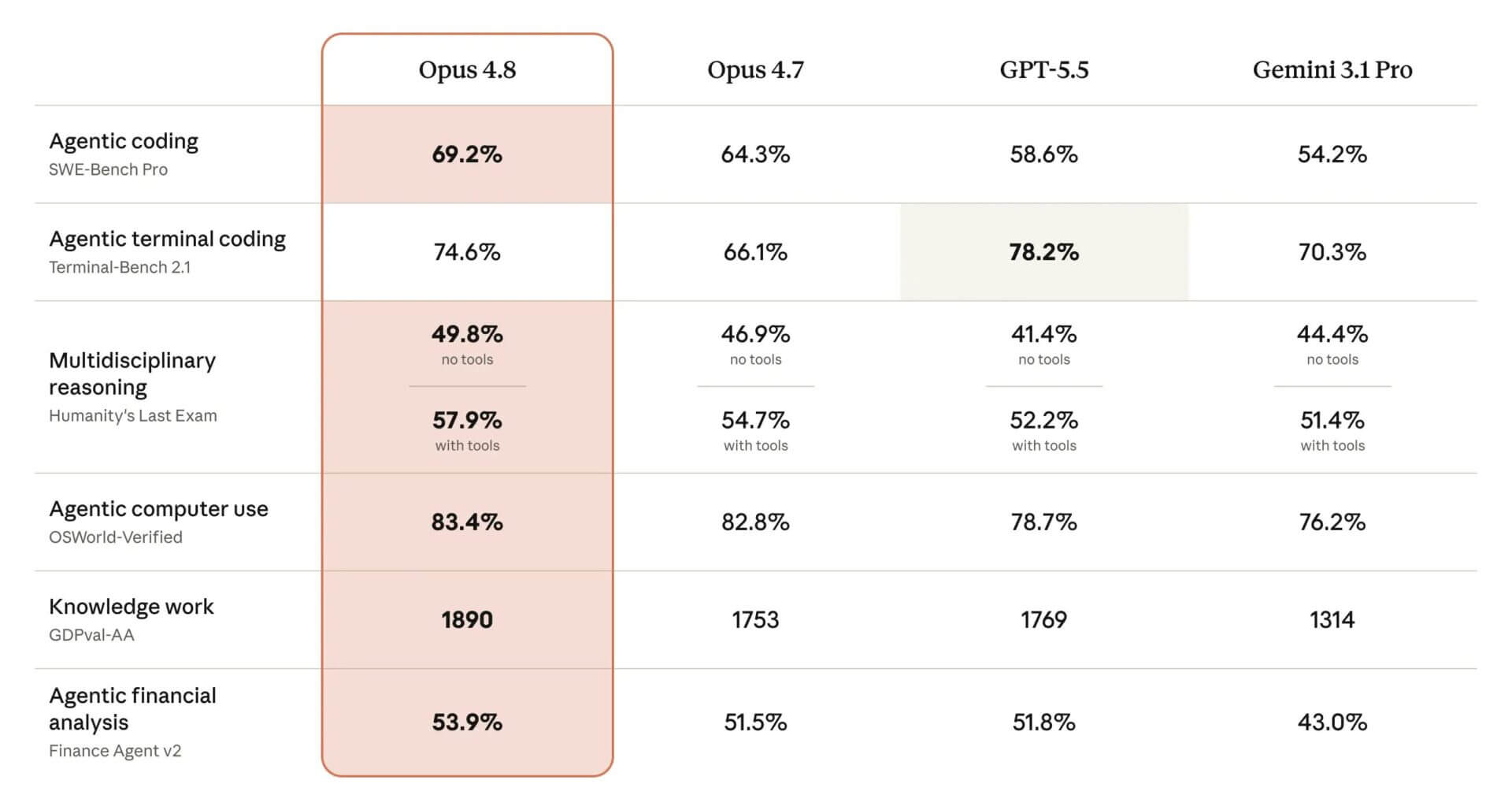
Claude Opus 4.8 : modéliser l’honnêteté comme nouvelle frontière de l’IA
Quatre fois. C’est l’écart avec lequel Opus 4.8, le dernier modèle d’Anthropic, lancé le 28 mai, laisse passer moins de défauts dans le code qu’il a écrit que l’Opus 4.7. Un numéro sec, presque trivial parmi les nombreux benchmarks qui accompagnent chaque sortie, et c’est plutôt le point autour duquel tout le reste tourne. Anthropic a décidé de mettre au centre de la communication non pas la vitesse, ni le prix inchangé, mais un mot que l’on n’aime pas utiliser avec les machines : l’honnêteté.
Il existe une tentation très humaine que les modèles linguistiques ont héritée de nous, celle de déclarer que nous avons fini alors que ce n’est pas vrai, de dire que le problème est résolu parce que ça sonne mieux que « j’y travaille encore ». Anthropic le décrit sans détour, écrivant que les modèles parfois ils tirent des conclusions hâtives, revendiquant des progrès que les preuves ne soutiennent pas.
Quiconque a travaillé des heures avec un agent sait combien coûte cher cette confiance mal placée, car l’erreur ne réside pas dans le mauvais code, elle réside dans la certitude avec laquelle elle vous est présentée comme correcte.
Une machine qui signale ses doutes
Le cœur du communiqué réside ici, dans une phrase qui parle de comportement plutôt que de pouvoir. Les testeurs rapportent que l’Opus 4.8 signale plus souvent des incertitudes concernant son fonctionnement et fait moins d’affirmations non étayées. Un ingénieur du personnel parle d’un modèle en Claude Code qui pose les bonnes questions, détecte ses propres erreurs et remet en question un plan lorsqu’il ne tient pas, instaurant la confiance autour d’explorations complexes avant d’aborder quelque chose d’important.
Cela semble peu, mais cela bouleverse la dynamique avec laquelle nous avons appris à vivre avec ces outils. Pendant deux ans, le problème a été le modèle trop confiant, celui qui inventait une citation avec le même naturel qu’il rapportait une vraie.
Un système qui dit « Je ne sais pas » ou « J’ai un doute ici » est un outil que l’on peut enfin déléguer sans vérifier chaque ligne, et c’est exactement la condition qui sépare un assistant d’un collaborateur.
L’équipe d’alignement et le vocabulaire des valeurs
Anthropic accompagne la version avec une évaluation de l’alignement, et le langage qu’il utilise mérite l’attention. L’équipe écrit que l’Opus 4.8 atteint de nouveaux sommets dans la mesure des traits prosociaux tels que le soutien à l’autonomie de l’utilisateur et l’action dans son meilleur intérêt. Les comportements désalignés tels que la tromperie ou la collaboration avec une utilisation inappropriée sont nettement inférieurs à ceux de l’Opus 4.7, proches de ceux du modèle le mieux aligné en interne, Claude Mythos Preview.
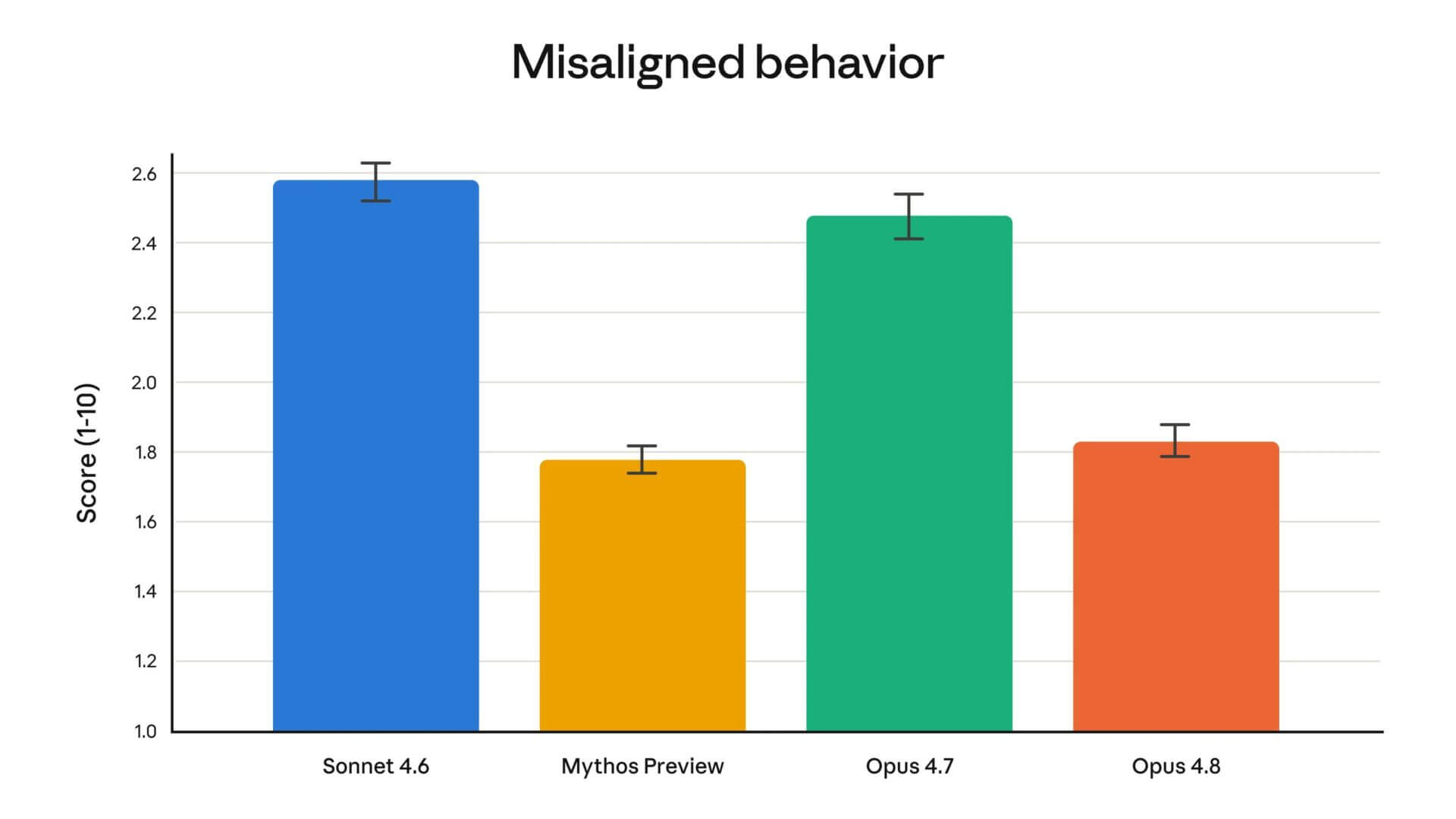
Ce sont des mots qu’un bureau produit n’utiliserait jamais pour décrire une fonction. Autonomie des utilisateurs, meilleur intérêt, traits prosociaux : c’est le vocabulaire d’une relation, pas d’une technique spécifique. Dans Peau numérique Je pensais à la façon dont la technologie cesse d’être un outil externe et devient une extension de ceux qui l’utilisent, et un modèle qui est chargé de protéger l’autonomie de ceux qui se trouvent devant elle est précisément cela, une peau qui ne veut pas remplacer celui qui le porte.
Contrôler l’effort ou redonner le choix à ceux qui travaillent
Le modèle s’accompagne de fonctions qui vont dans le même sens. Un contrôle d’effort apparaît sur claude.ai et dans Cowork, à côté du sélecteur de modèle, avec lequel vous décidez de l’effort que Claude doit déployer pour répondre. À des niveaux élevés, il réfléchit plus profondément, à des niveaux faibles, il réagit plus rapidement tout en consommant moins de limites d’utilisation. L’Opus 4.8 utilise par défaut un effort élevé, qu’Anthropic considère comme le meilleur équilibre entre qualité et expérience.
Il y a quelque chose d’intéressant à redonner ce levier à ceux qui travaillent, car pendant des années la profondeur du raisonnement a été une boîte fermée, décidée ailleurs. Donner à l’utilisateur le contrôle de l’effort signifie le traiter comme une personne capable de savoir quand un problème mérite vingt secondes et quand il en mérite deux, et ceci, à une époque où chaque logiciel a tendance à décider à notre place, est une petite contre-tendance qui mérite d’être notée.
Flux de travail dynamiques et saut d’échelle
Claude Code bénéficie de workflows dynamiques, en aperçu de recherche, qui permettent au modèle de planifier le travail puis de lancer des centaines de sous-agents en parallèle dans la même session, en vérifiant leurs sorties avant d’en rendre compte à l’utilisateur. Anthropic cite des migrations à grande échelle base de codedes centaines de milliers de lignes apportées dès le début à la fusion, avec la suite de tests existante comme seul étalon.
Le fil qui relie cette fonction àhonnêteté du modèle ce n’est pas aléatoire. Plus un système fonctionne longtemps et de manière autonome, plus le risque qu’il se convainque qu’il est terminé devient dangereux, car personne ne le regarde pendant qu’il fonctionne.
Un agent qui erre pendant des heures sans surveillance n’a de sens que s’il sait s’arrêter et dire « il y a un problème ici », et pour cette raison la capacité de se vérifier et la capacité de grimper surgissent ensemble, c’est le même pari vu des deux côtés.
Les prix
Les prix pour une utilisation standard restent inchangés par rapport à l’Opus 4.7 : 5 $ pour chaque million de jetons entrants et 25 $ pour chaque million de jetons sortants. Les prix du mode rapide sont de 10 $ pour chaque million de jetons entrants et de 50 $ pour chaque million de jetons sortants. Les développeurs peuvent utiliser claude-opus-4-8 via l’API Claude.
Mythe à l’horizon et seuil proche
Anthropic se termine par un regard vers l’avant, et ici le ton change. Il qualifie l’Opus 4.8 d’amélioration modeste mais tangible et anticipe une nouvelle classe de modèles dotés d’une intelligence supérieure à l’Opus. Il s’appelle Project Glasswing et un petit nombre d’organisations utilisent déjà Claude Mythos Preview pour leurs travaux de cybersécurité. Les modèles de ce niveau, écrit l’entreprise, nécessitent des cyber-protections plus robustes avant de pouvoir être rendus accessibles à tous, garanties sur lesquelles elle prétend faire des progrès rapides.
Cela vaut la peine de se concentrer sur ce passage. Une entreprise qui ralentit consciemment la sortie d’un modèle plus performant, parce qu’elle souhaite d’abord une protection adéquate, présente une posture différente de celle de la pure course au pouvoir. Un modèle est déclaré plus honnête et le suivant est volontairement ralenti : la cohérence entre les deux choses n’est pas évidente, et est peut-être la vraie nouvelle derrière l’actualité.
La question qui reste, à l’approche de Mythos, est de savoir si cette prudence résistera à la pression concurrentielle, ou si la prudence d’aujourd’hui sera la première chose à faire lorsque quelqu’un d’autre terminera premier.