

presque aussi bon que Claude, mais à une fraction du prix
Il y a quelques jours, la société chinoise Moonshot AI a lancé Kimi K2.6, son nouveau LLM qui concurrence les familles de modèles Gemini, GPT et Claude et qui est aussi particulièrement compétitif en termes de prix. Quelques semaines plus tôt, elle avait lancé Kimi Code, un agent d’IA de programmation qui concurrence à son tour Gemini Cli, Codex et Claude Code. La question est évidente : le couple Kimi Code/Kimi K2.6 peut-il vraiment rivaliser avec le couple à la mode Claude Code/Opus 4.7 ? La réponse est compliquée.
Un superbe modèle (mais pas parfait). Kimi K2.6 est un modèle de pondération ouvert avec un billion de paramètres au total (un billion américain), dont 32 milliards de paramètres sont actifs et qui utilise la célèbre architecture Mixture-of-Experts. L’article de lancement montre ses performances par rapport à GPT-5.4 et Opus 4.6 et la vérité est que ses chiffres dans ces tests synthétiques semblent vraiment excellents :
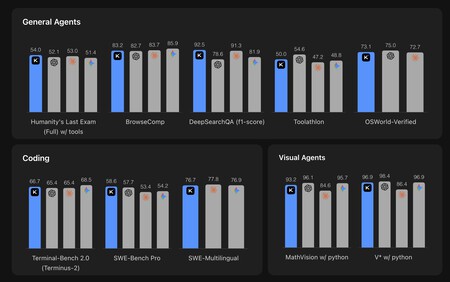
Ici, Kimi K2.6 est comparé à GPT-5.4, Claude Opus 4.6 et Gemini 3.1 Pro. Source : Moonshot AI.
Jusqu’à 8 fois moins cher que l’Opus 4.6. Il propose des plans d’abonnement de style Claude Pro ou ChatGPT Plus, mais il peut également être utilisé via API. Le prix dans ce cas est de 0,60 $ par million de jetons d’entrée (0,16 si mis en cache) et de 4 $ par million de jetons de sortie. Claude Opus 4.6 coûte 5 $ par million de jetons d’entrée et 25 $ par million de jetons de sortie, soit jusqu’à huit fois plus. Claude Opus 4.7 a le même prix et est théoriquement meilleur en termes de performances, mais lorsque Kimi K2.6 a été annoncé, cette version n’était pas encore apparue (et GPT-5.5 non plus).
La magie de l’essaim d’agents IA. Claude Code fonctionne de manière séquentielle. Analysez le problème, exécutez une étape, vérifiez le résultat et décidez comment procéder. Dans Kimi Code, une approche différente est utilisée : un « agent principal » divise ou décompose la tâche que nous lui demandons en sous-tâches indépendantes et à partir de cette division, il lance jusqu’à 300 « sous-agents » qui fonctionnent en parallèle et sont capables de coordonner jusqu’à 4 000 étapes simultanément.
Est-ce que plusieurs travaillent en même temps mieux qu’un ? C’est le soi-disant « essaim d’agents » de Kimi K2.6 qui est utilisé au maximum dans Kimi Code et que l’on peut également activer dans sa version gratuite sur son site officiel. Dans Kimi K2.5, jusqu’à 100 sous-agents et 1 500 étapes pourraient être lancés, le saut est donc significatif. Lors de tests internes, Moonshot a montré comment ces essaims parvenaient, par exemple, à « refactoriser » un moteur financier open source, en travaillant 13 heures d’affilée et en effectuant plus de 1 000 appels d’outils avec une amélioration de 185 % des performances moyennes. Bien entendu, il s’agissait de tests internes.

Au-delà des repères. Kilo.ai est une entreprise qui développe des outils comme Kilo Code ou Kilo CLI, des agents de programmation similaires à Kimi Code, et ses ingénieurs souhaitaient évaluer les performances des deux combinaisons. Ils ont donné à Claude Opus 4.7 et Kimi K2.6 la même invite de 1 042 lignes pour créer FlowGraph, une API d’orchestration de flux de travail avec validation de graphiques dirigés ou streaming d’événements en temps réel. Les deux modèles fonctionnaient sur Kilo CLI car ce qu’ils voulaient comparer, c’était les modèles sans plus tarder.
Kimi était moins cher, mais il a également échoué davantage. Claude Opus 4.7 s’est terminé en 20 minutes et le coût final était de 3,56 $. Kimi K2.6 a pris plus de temps, en partie parce que la disponibilité du serveur était limitée (le modèle venait juste d’être lancé), mais il a coûté 0,67 $. Cinq fois moins.
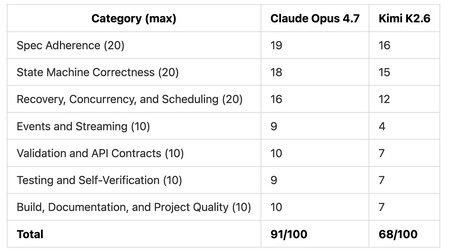
Kimi K2.6 l’a bien fait à un prix ridicule. Claude a fait beaucoup mieux, mais cela a aussi coûté cinq fois plus cher.
Kimi a fait 75 % de ce que Claude a fait à 19 % du coût. Le problème est que tous deux pensaient avoir tout fait correctement et ne détectaient pas s’ils avaient commis des erreurs. Une analyse plus approfondie a révélé que Claude en avait commis un et que Kimi en avait commis six d’importance variable. Selon les analystes de Kilo.ai, la note finale pour les deux était de 91 points sur 100 pour l’Opus 4.7 et de 68 points sur 100 pour Kimi.
Deux façons de voir le verre. Ce score semble indiquer clairement que Kimi est simplement moins cher parce qu’il a fait un moins bon travail. Mais les ingénieurs de Kilo avaient une autre façon de voir les choses. Ils comparent depuis un certain temps les modèles de pondération ouverts des entreprises chinoises et ont remarqué à quel point l’écart avec les modèles « frontières » d’Anthropic ou d’OpenAI devient de moins en moins prononcé.
« Avec un prix de 0,67 $ et un examen approfondi, Kimi K2.6 est désormais une option viable. Avec un prix de 3,56 $ et moins de correctifs nécessaires, Claude Opus 4.7 est l’option la plus sûre. Le choix entre les deux options dépend de l’analyse. Il y a un an, ce choix n’existait pratiquement pas à ce niveau de complexité. «
La révision est obligatoire. Ou ce qui est pareil : si après le travail de Kimi K2.6 on effectuait une révision et une correction plus approfondies, il est probable que toutes ces erreurs seraient détectées et corrigées, mais si nous devions faire confiance aux deux modèles et que nous ne pouvions exécuter qu’un « un seul passage » d’exécution de l’IA, l’Opus 4.7 gagnerait la partie. La clé est la suivante : il ne faut pas faire confiance immédiatement au code d’un modèle, et il est conseillé de toujours revoir ce code.

Le facteur géopolitique. Kimi et Kimi Code viennent de Chine et la startup Moonshot AI bénéficie du soutien financier d’Alibaba. Le code traité dans ces modèles passe par leurs serveurs, ce qui peut ne pas être pertinent pour un développeur individuel. Cependant, pour une entreprise avec un code propriétaire sensible, des contrats devant respecter certaines réglementations européennes ou américaines et des projets dans des secteurs réglementés, cela peut constituer un obstacle de taille. Kimi Code atténue ce problème en offrant la possibilité d’exécuter le modèle localement grâce à ses poids ouverts, mais cela nécessite des machines très puissantes et élimine une partie de l’avantage en termes de coût.
Ce que Kimi Code a, ce que Claude Code n’a pas. La différence la plus claire entre les deux agents d’IA de programmation est le parallélisme. Comme nous l’avons dit, la capacité de lancer jusqu’à 300 sous-agents pour travailler simultanément en attaquant le même problème en même temps est remarquable. Pour l’analyse de grands référentiels ou la génération d’une documentation massive, cette différence de rapidité est réelle et frappante. Il y a un autre élément important : Kimi Code est agnostique en matière de modèle, et permet d’utiliser des modèles cloud comme Claude, GPT ou Gemini, mais aussi des modèles locaux via Ollama. Claude Code accepte également d’autres modèles, mais il est un peu plus compliqué à utiliser avec autre chose que Sonnet/Opus.
Conclusion : vive les options. Ici, il est clair que ce que disent les critères de référence internes est très différent de ce que disent les expériences réelles. La comparaison Kilo.ai est frappante et confirme encore une fois deux choses. La première, c’est que Claude Opus 4.6/4.7 est toujours supérieur aux modèles à poids ouvert des entreprises chinoises. Le deuxième et le plus important, c’est qu’il n’est plus aussi supérieur. La différence de performances se réduit, mais ce faisant, l’aspect coût entre en jeu : si le « modèle chinois » est assez bon pour vous (et il l’est de plus en plus), ce que vous réaliserez, c’est économiser beaucoup d’argent. Anthropic, OpenAI ou Google devraient s’inquiéter.
Images | Chris Ried
À Simseo | DeepSeek leur a promis le bonheur en tant que grande IA chinoise. Je ne comptais pas sur un petit détail : Kimi