

Anthropic dit que Claude Mythos est trop puissant pour être rendu public. La question est de savoir si ce n’est rien d’autre que « le loup arrive ».
Claude Mythos Preview est le meilleur modèle d’IA jamais créé. Nous ne le disons pas, Anthropic le dit, mais presque personne d’autre ne peut le dire car seul un groupe restreint d’entreprises a accès audit modèle. Les capacités de cybersécurité du modèle semblent étonnantes, mais de plus en plus d’experts affirment que même si Mythos est meilleur que ses prédécesseurs, ce n’est pas le saut révolutionnaire qu’Anthropic semble proposer. Cette façon de lancer le modèle est-elle simplement un moyen efficace de créer ?
Soyez prudent avec le discours d’Anthropic. Le célèbre entrepreneur et analyste Gary Marcus a récemment donné trois raisons pour lesquelles, selon lui, le lancement de Mythos n’est pas aussi révolutionnaire qu’Anthropic veut nous le faire croire. Il cite des tweets d’ingénieurs logiciels et d’experts en cybersécurité qui mettent en doute les affirmations d’Anthropic. L’entreprise a publié une étude sur les capacités de Claude Mythos Preview qui semblait en faire un outil extraordinaire pour le domaine de la cybersécurité, mais en même temps il était si puissant qu’il pouvait être très dangereux s’il tombait entre de mauvaises mains.
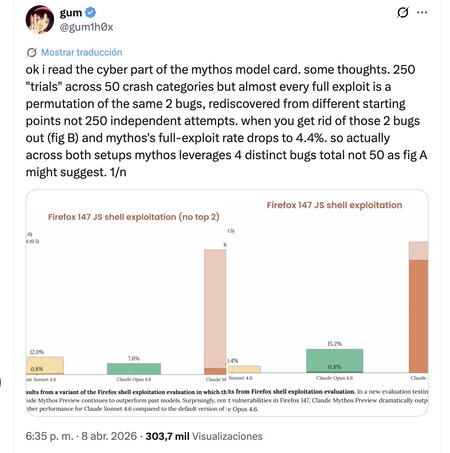
N’est-ce pas grave ? Parmi les réalisations de Claude Mythos, Anthropic a souligné comment il avait découvert des vulnérabilités dans Firefox 147. Mais en réalité, bon nombre de failles étaient essentiellement des variantes des deux mêmes bugs. Si vous les supprimiez de l’équation, le taux d’efficacité de Mythos pour trouver de nouveaux exploits diminuait considérablement, même en dessous de l’Opus 4.6. Anthropic ne l’a pas caché, bien sûr, mais cela fait que cette capacité, par exemple, ne semble pas si frappante. Un utilisateur de X a également critiqué l’utilisation de Cybench comme référence en matière de cybersécurité alors que l’Opus 4.6 la surpassait presque complètement. Pour lui, le choix de certains tests Anthropic était discutable car ils ne remettaient pas en cause les modèles actuels.
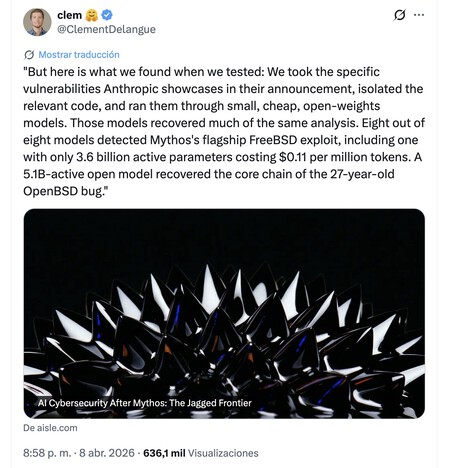
D’autres modèles peuvent faire de même. Le co-fondateur et PDG de Hugging Face, Clément Delangue, a déclaré que Mythos n’était pas grave. Leur argument : ils avaient utilisé de petits modèles ouverts bon marché, isolé le code pertinent de quelques exemples de vulnérabilités trouvées par Mythos et trouvé les mêmes problèmes que le modèle Anthropic avait déjà détectés.
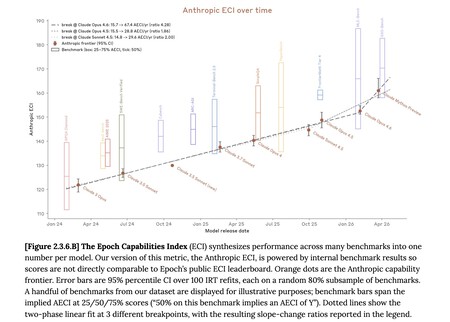
Selon l’Epoch Capabilities Index, qui mesure la capacité des modèles d’IA en combinant plusieurs benchmarks, le saut franchi par Mythos est frappant et « s’écarte » de la ligne progressiste de ses prédécesseurs. Source : Anthropique.
Biais de l’observateur. Mais ici, il convient de noter que dans ces analyses, ils savaient où chercher car Mythos avait déjà trouvé ces problèmes. Nous avons affaire à un biais d’observateur, et en fait, le document Hugging Face indique clairement qu’ils lui ont même donné des indices spécifiques tels que « envisager un débordement d’entier ») pour trouver ces bugs. Et sur ce constat, un autre : Hugging Face ne dit pas qu’un petit modèle peut remplacer Mythos à lui seul, mais qu’il peut être très bon en lui donnant le fragment de code approprié. Mythos semble plus capable de détecter des failles de sécurité aveuglément complexes, mais il s’agit d’un modèle énorme et c’est pourquoi il a une plus grande capacité. Ou qu’est-ce qui revient au même : Mythos est meilleur parce qu’il a la taille, la conception et les ressources pour être meilleur.
Peur, incertitude, doute ? Le langage utilisé par Anthropic dans cette publicité pourrait être considéré dans une certaine mesure comme une utilisation claire du FUD (« Peur, Uncertainty, Doute » -> « Peur, Uncertainty, Doute ») comme technique de marketing. C’est une ressource qui a été vue dans le passé, et par exemple OpenAI a déjà déclaré en 2019 – des années avant le lancement de ChatGPT – que GPT-2 était trop dangereux pour une diffusion publique. Ce n’était évidemment pas le cas, mais cela a certainement contribué à créer des attentes quant à la véritable capacité du modèle.
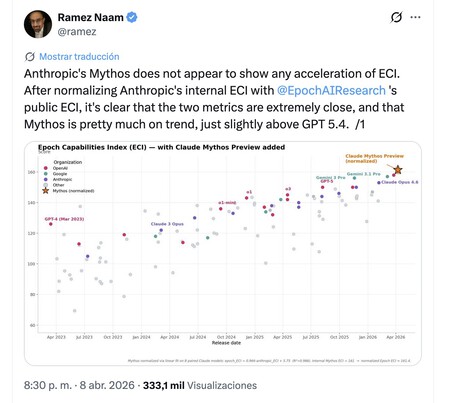
C’est mieux, mais peut-être pas révolutionnaire. Les résultats des benchmarks publiés par Anthropic ont déjà montré que même s’il y a des sauts très notables dans certains tests, dans d’autres l’évolution est beaucoup moins frappante. Claude Mythos n’était pas le meilleur en tout, et maintenant des analystes apparaissent qui contrastent ces données avec d’autres mesures. Par exemple, avec l’Epoch Capabilities Index (ECI) d’Epoch AI, la startup qui possède l’un des benchmarks les plus réputés du secteur. Et selon cet indice, Claude Mythos est au-dessus de ses rivaux, mais pas de beaucoup.
Le loup arrive. La vérité est que le lancement de Claude Mythos Preview a été vraiment frappant et les documents qui accompagnaient ce document nous parlent d’un modèle d’IA vraiment performant. Le problème est qu’il est impossible de le vérifier car seules quelques entreprises y ont accès et peuvent le tester. Sans cette disponibilité publique, la seule chose que nous pouvons faire est de faire confiance (ou non) à ce qu’Anthropic nous dit, et c’est là le point : il n’est pas clair que nous devrions le faire. L’entreprise souhaite évidemment que nous adhérions à ce discours, mais sans une analyse indépendante, il est impossible de vérifier ces déclarations.
À Simseo | Anthropic est devenu le chouchou de l’IA et cherche un partenaire pour garantir son avenir. Ce n’est pas celui que nous pensions