

Nous disposons déjà de plus de 20 modèles d’IA avancés. Si vous leur demandez quelque chose, il est de plus en plus probable qu’ils vous répondent de la même manière.
Nous avons l'intelligence artificielle. Ce qui nous manque, c'est une diversité artificielle. C’est la conclusion à laquelle est parvenu un groupe de chercheurs qui ont effectué un test relativement simple : ils ont posé une série de questions à 25 modèles d’IA différents pour voir leurs réponses. Et c'est là le mauvais côté : ils ont répondu à des choses trop similaires.
« Esprit de ruche artificiel. » Des scientifiques de l’Université de Washington, de l’Université Carnegie Mellon et de l’Université de Stanford, entre autres institutions, ont publié une étude conjointe intéressante. Ils y révèlent qu'après divers tests, il semble clair que même si les modèles d'IA deviennent de plus en plus avancés, le problème est qu'ils semblent tous avoir développé une sorte d'« esprit de ruche artificiel » : peu importe ce que vous leur demandez, ils répondent d'une manière étrangement similaire.
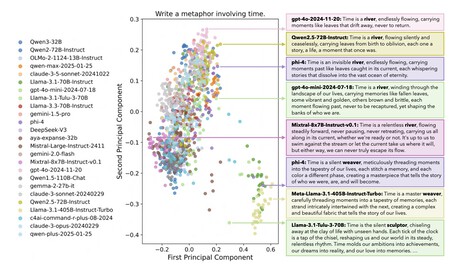
Lorsqu'on a demandé à tous ces modèles « quelle était l'heure », beaucoup ont répondu par la phrase « le temps est comme une rivière », tandis qu'un autre groupe de modèles a répondu que « c'est comme un tisserand ».
Le temps est une rivière. L'une des questions posées à ces modèles est « Qu'est-ce que le temps ? », et bien que cette question laisse clairement place à des réponses très différentes, le plus inquiétant est que ce n'est pas le cas. Plusieurs modèles ont répondu par l'expression « le temps est une rivière » puis l'ont un peu développée, tandis que d'autres ont répondu par « le temps est un tisserand (de moments) ». Cette similitude dans les réponses s’est avérée être une constante.
L'illusion de l'abondance. Nous pensons que lorsque nous consultons quelque chose avec une IA, nous accédons à tout un monde de possibilités conversationnelles, mais l'étude révèle qu'en réalité nous sommes confrontés à un système qui propose des résultats très similaires. Bien que les modèles linguistiques promettent une créativité illimitée, ils ont tendance à converger vers cet esprit de ruche où la diversité est sacrifiée au profit de la cohérence statistique. C'est raisonnable, d'autant plus que les grands modèles de langage sont basés sur le concept de transformateur, un système probabiliste qui essaie de trouver le prochain « meilleur » mot lorsqu'il nous répond.
Même scénario. Les chercheurs ont créé un ensemble de données à grande échelle avec 26 000 requêtes provenant d’utilisateurs réels qui ont théoriquement permis aux modèles de générer plusieurs réponses valides et créatives. Ils ont appelé cet ensemble de données « Infinity-Chat » et ont divisé les questions en six catégories principales et 17 sous-catégories.

IA, tu te répètes plus qu'un disque rayé. Au cours des tests, il a été observé que le même modèle a tendance à se répéter, générant des réponses très similaires. En fait, même lorsque des paramètres spéciaux étaient utilisés pour des questions conçues pour encourager la diversité, le même effet était produit. C’est ce que les chercheurs appellent « l’effondrement inter-modèles ».
Trop similaire. Ces tests ont clairement montré que la similarité sémantique, c'est-à-dire la similarité des réponses des différents modèles, était préoccupante. Selon l'étude, cette similitude variait entre 71 % et 82 %, et dans certains cas, certains modèles parvenaient à générer des paragraphes identiques mot pour mot.
Le problème de la formation. Non seulement ils génèrent tous du texte de la même manière en raison de leur conception, mais il existe également un problème de formation. Les auteurs suggèrent que cette homogénéité des réponses pourrait être due à plusieurs raisons :
- Les sources des données d'entraînement finissent par être partagées : les modèles sont entraînés avec des « ensembles de données » similaires et s'appuient par exemple sur des textes et des connaissances similaires provenant, par exemple, de Wikipédia ou d'un ensemble de livres très similaires.
- Effet de contamination dû aux données synthétiques générées par d’autres IA : ils utilisent également des textes synthétiques générés par d’autres modèles d’IA.
- Récompenses : les modèles utilisés pour récompenser ces modèles sont calibrés pour récompenser une certaine notion de qualité « consensuelle ». Ainsi, la diversité créative et individuelle est punie. Les IA sont « éduquées » pour être précisément très similaires les unes aux autres.
Problème en vue. Tout cela amène les chercheurs à mettre explicitement en garde contre deux risques évidents liés à l’utilisation de ces modèles d’IA.
- Nous penserons la même chose : si nous, utilisateurs, n'arrêtons pas d'utiliser des modèles d'IA qui nous donnent fondamentalement les mêmes réponses, nos propres façons de penser sur ces sujets et problèmes deviendront « homogénéisées » et nos réponses seront également plus uniformes.
- Réduction des points de vue : L’autre danger découle du premier : si l’IA finit par converger et répondre à la même chose, les points de vue sont éliminés. Ici, les préjugés du monde occidental, par exemple, seront évidents dans les modèles occidentaux (ChatGPT, Gemini, Claude), et la même chose se produira dans les modèles orientaux, par exemple. Cela entraînerait la suppression potentielle de visions du monde alternatives, de perspectives et de « regards » différents de notre réalité.
Images | Solen Feyissa
À Simseo | Le scientifique qui a rendu possible l’IA que nous connaissons aujourd’hui vient de récolter 1 milliard. Son nouvel objectif est de lui apprendre à voir l'espace