

OpenAI et Anthropic l'ont clairement indiqué avec GPT-5.3-Codex et Claude Opus 4.6
Lorsque ChatGPT a éclaté en novembre 2022, OpenAI semblait sans égal. Et, dans une large mesure, ce fut le cas. Ce chatbot, malgré ses erreurs et ses limites, a inauguré une catégorie à part. Cependant, dans le secteur technologique, les avantages sont rarement permanents et, en 2026, la position de l'entreprise dirigée par Sam Altman est loin de ce qu'elle était alors.
Google a réussi à séduire le grand public avec Nano Banana Pro, tandis que Gemini gagne régulièrement du terrain en tant que chatbot à intelligence artificielle. Dans le même temps, la part de marché de ChatGPT a sensiblement diminué sur certains marchés. Anthropic, quant à lui, s'est imposé comme une référence en matière d'ingénierie logicielle et est devenu l'un des outils préférés des programmeurs.
Dans cette course pour donner le ton à l'IA, on a assisté ce jeudi à un curieux mouvement : l'arrivée quasi simultanée de deux modèles axés sur la programmation, GPT-5.3-Codex et Claude Opus 4.6. La coïncidence ne semble pas fortuite et reflète à quel point les principaux acteurs du secteur rivalisent pour définir la prochaine étape, dans un scénario où les principaux bénéficiaires sont, une fois de plus, les utilisateurs.
Avec ces nouveaux modèles déjà sur la table, la question se pose de savoir ce qu’ils apportent réellement. Les promesses sont nombreuses et des comparables commencent également à apparaître qui aident à les situer. Il est donc temps d’examiner un peu plus en détail ce que OpenAI et Anthropic proposent à ceux qui utilisent l’IA comme outil de développement.
GPT-5.3-Codex et Opus 4.6 entrent en scène : ce que chacun promet aux développeurs
GPT-5.3-Codex est présenté comme un modèle axé sur les agents de programmation qui cherche à élargir la portée de ce qu'un développeur peut déléguer à l'IA. OpenAI affirme qu'il combine des améliorations des performances du code, du raisonnement et des connaissances professionnelles par rapport aux générations précédentes et qu'il est 25 % plus rapide.
Avec cet équilibre, le système est orienté vers des tâches prolongées qui impliquent de la recherche, l'utilisation d'outils et une exécution complexe, tout en conservant la possibilité d'intervenir et de guider le processus en temps réel sans perdre le fil du travail.
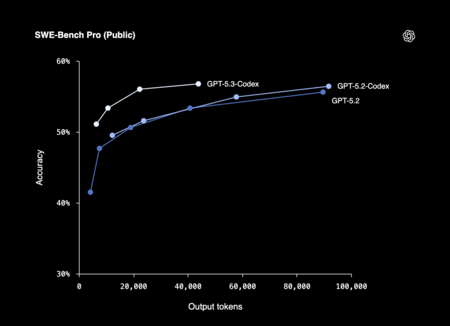
L’un des éléments les plus frappants qu’OpenAI met en avant dans cette génération est le rôle qu’aurait joué le Codex lui-même dans son développement. L'équipe a utilisé les premières versions du modèle pour déboguer la formation, gérer le déploiement et analyser les résultats des tests et des évaluations, une approche qui a accéléré les cycles de recherche et d'ingénierie.
Au-delà de ce processus interne, GPT-5.3-Codex montre également des progrès dans des tâches pratiques telles que la création autonome d'applications Web et de jeux. La société a publié deux exemples que l'on peut essayer dès maintenant en cliquant sur les liens : un jeu de course avec huit cartes et un jeu de plongée pour explorer les récifs.
Le tour d'Anthropic vient avec Claude Opus 4.6, une mise à jour que l'entreprise présente comme une amélioration directe de la planification, de l'autonomie et de la fiabilité au sein de grandes bases de code. Le modèle, affirment-ils, peut supporter des tâches agentiques plus longtemps, en examinant et en déboguant son propre travail avec plus de précision.
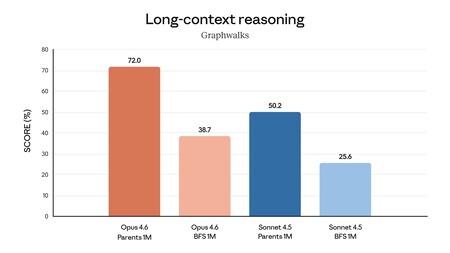
L'idée est que nous pouvons utiliser ces capacités dans des tâches telles que l'analyse financière, la recherche documentaire ou la création de présentations. À cela s'ajoute une fenêtre contextuelle pouvant aller jusqu'à un million de jetons en phase bêta, un saut qui vise à réduire la perte d'informations dans les processus longs et à renforcer l'utilité du système.
Au-delà du cœur du modèle, Anthropic accompagne Opus 4.6 avec une série de changements visant à prolonger son utilité dans les flux de travail réels. Parmi eux figurent des mécanismes tels que la « pensée adaptative », qui permet au système d’ajuster automatiquement la profondeur de son raisonnement en fonction du contexte.
Des niveaux d'effort configurables et des techniques de compression de contexte conçues pour soutenir de longues conversations et tâches sans épuiser les limites disponibles apparaissent également sur la scène. À cela s’ajoutent des équipes d’agents pouvant être coordonnées en parallèle au sein de Claude Code et une intégration plus poussée d’Excel ou PowerPoint.
Certaines entreprises ont eu un accès précoce au nouveau modèle d'Anthropic. L'entreprise rassemble certains témoignages sur son site Internet. En voici un :
« Claude Opus 4.6 a résolu de manière autonome 13 problèmes et assigné 12 problèmes aux membres de l'équipe appropriés en une seule journée, gérant une organisation d'environ 50 personnes réparties dans 6 référentiels. Il a géré à la fois les décisions relatives aux produits et à l'organisation tout en synthétisant le contexte dans plusieurs domaines, et a su quand passer à un humain. » Yusuke Kaji
Directeur de l'IA, Rakuten
Bien que le produit d'OpenAI, GPT-5.3-Codex, ne soit pas encore disponible dans l'API, celui d'Anthropic l'est. Il maintient le prix de base de 5 $ par million de jetons d'entrée et de 25 $ par million de jetons de sortie, avec des nuances telles qu'un coût majoré lorsque les invites dépassent 200 000 jetons.
Mesurer qui gagne avec des chiffres ?
Lorsqu'on tente de mettre face à face GPT-5.3-Codex et Claude Opus 4.6, le principal obstacle n'est pas le manque de chiffres, mais plutôt leur difficile correspondance. Chaque entreprise sélectionne les évaluations qui reflètent le mieux ses progrès et, bien que beaucoup appartiennent à des catégories similaires, elles diffèrent par la méthodologie, les versions ou les mesures, ce qui empêche une lecture directe.
Dans ce type de modèles, cette fragmentation des résultats fait partie de l’état de la technologie elle-même, mais elle nécessite également une interprétation prudente qui sépare les démonstrations techniques des comparaisons véritablement équivalentes. Ce n'est qu'à partir de ce filtre qu'il est possible d'identifier les quelques points où les deux systèmes peuvent être mesurés dans des conditions comparables et de tirer des conclusions utiles pour les développeurs.
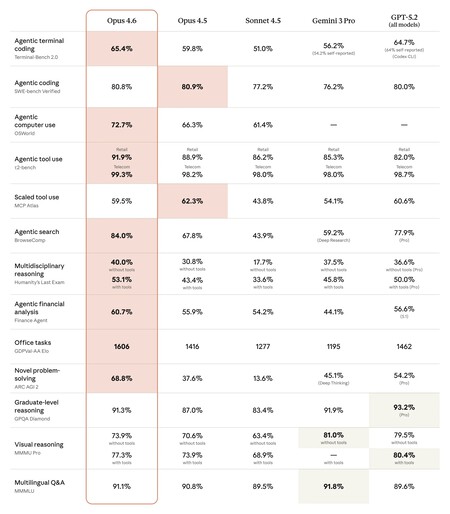
Si nous limitons l'analyse à des métriques véritablement comparables, le terrain d'entente entre GPT-5.3-Codex et Claude Opus 4.6 se limite à deux évaluations spécifiques identifiées grâce à nos propres recherches : Terminal-Bench 2.0 et OSWorld dans sa version vérifiée.

Les résultats montrent une répartition des forces plutôt qu’une nette suprématie. GPT-5.3-Codex obtient un score de 77,3 % dans Terminal-Bench 2.0 contre 65,4 % pour Opus 4.6, ce qui indique une plus grande efficacité dans les flux de travail centrés sur le terminal. Au contraire, Opus 4.6 atteint 72,7% dans OSWorld, dépassant les 64,7% de GPT-5.3-Codex dans les tâches d'interaction générale avec le système, un contraste qui renforce l'idée de spécialisation selon l'environnement d'utilisation.
On pourrait donc dire que les capacités décrites par chaque fabricant pointent vers des outils qui ne se limitent plus à générer du code, mais cherchent plutôt à participer à des processus prolongés d'analyse, d'exécution et de révision au sein d'environnements professionnels réels. Cette transition introduit de nouveaux critères de sélection qui vont au-delà de la performance ponctuelle.
À Simseo | OpenAI a un problème : Anthropic réussit là où le plus d'argent est en jeu