

Qwen3-Max-Thinking rivalise plus que jamais avec le Gemini 3 Pro de Google. La clé est dans ce qu'on ne dit pas
Il y a des jours où on a l'impression d'ouvrir le téléphone et que le tableau de bord change à nouveau. Depuis l’éclatement de ChatGPT en novembre 2022, la course à l’intelligence artificielle n’a cessé de s’accélérer, et toutes les quelques semaines apparaît un nouveau modèle qui promet de pousser la barre un peu plus loin. Parfois, il s’agit d’une mise à jour, d’autres fois, d’un « produit phare » avec un nom de famille différent, mais le schéma se répète : plus de puissance, plus d’ambition et une histoire de plus en plus globale. Dans ce contexte, la Chine gagne en visibilité de manière de plus en plus évidente, et le nom qui entre désormais dans la conversation est Qwen3-Max-Thinking, la proposition d'Alibaba avec laquelle il veut jouer dans la même ligue que les grandes références du moment.
À première vue, Qwen3-Max-Thinking peut sembler n'être qu'un autre nom parmi la liste interminable de modèles. Mais il y a ici une nuance pertinente : il le présente comme son modèle phare pour les tâches de raisonnement, et le place explicitement dans la même conversation que le Gemini 3 Pro. L'entreprise affirme avoir adapté les paramètres et investi des ressources informatiques dans le renforcement afin d'améliorer plusieurs dimensions à la fois, depuis les connaissances factuelles et le raisonnement complexe jusqu'au suivi des instructions, en passant par l'alignement sur les préférences humaines et les capacités des agents. En d’autres termes : vous ne vendez pas seulement de l’énergie brute, mais une façon de « penser » mieux.
Ce que les benchmarks enseignent
Pour tenir cette promesse, le plus utile est de regarder le tableau comparatif que nous avons en main, avec 19 benchmarks et un décompte direct : Gemini 3 Pro mène dans 11, Qwen3-Max-Thinking le fait dans 8. Ces données, en elles-mêmes, ne décident pas « qui est le meilleur », mais elles aident à comprendre le type de bataille que propose Alibaba face à Google. Ici, il convient d'être très littéral avec ce que nous mesurons : chaque benchmark se concentre sur une compétence spécifique, de la culture générale à la programmation, en passant par l'utilisation d'outils, le suivi d'instructions ou une longue analyse de contexte.
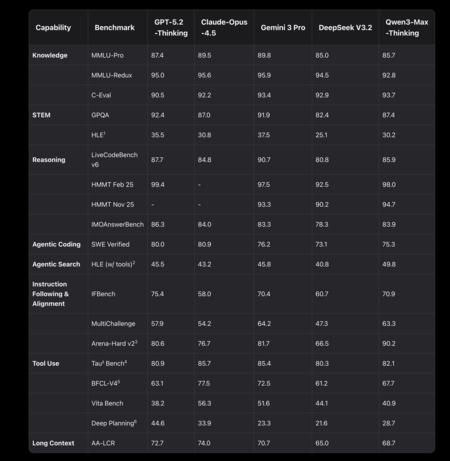
Si l’on cherche le point où Qwen3-Max-Thinking fait vraiment mouche, il y en a un qui se démarque des autres : suivre les instructions et s’aligner sur ce que les humains préfèrent dans une conversation. Dans Arena-Hard v2, Qwen gagne avec 90,2 contre 81,7 pour Gemini, ce qui représente la plus grande différence en sa faveur dans tout le tableau (8,5 points ci-dessus). Il ne s’agit pas d’une nuance mineure, car ce type de benchmark ne récompense pas seulement la « réussite » technique, mais plutôt le résultat final qu’une personne considère comme le plus utile lorsqu’elle compare aveuglément les réponses. À cela s’ajoute IFBench, où Qwen gagne de peu (70,9 contre 70,4). Traduit dans la vie réelle : lorsque l'utilisateur ne formule pas une instruction parfaite, lorsque la mission est ambiguë ou nécessite une intention d'interprétation, Qwen semble plus orienté vers la définition de ce qui lui est demandé et le faire d'une manière qui semble naturelle.
L’autre domaine dans lequel Qwen soutient son récit de « modèle de pensée » est le raisonnement mathématique et la résolution logique de problèmes. Sur HMMT, dans les numéros de novembre 2025 et février 2025, Qwen est en avance (94,7 contre 93,3 et 98,0 contre 97,5, respectivement). Et dans IMOAnswerBench, il gagne également, mais avec une marge minime : 83,9 contre 83,3. Ces chiffres ne suggèrent pas une raclée, mais ils suggèrent un schéma cohérent : lorsque le problème nécessite plusieurs étapes logiques et n'est pas résolu par la mémoire ou par une jolie réponse seule, Qwen a tendance à en profiter.
À ces améliorations, Alibaba ajoute un élément qui est déjà en train de devenir la nouvelle norme : le modèle ne reste pas dans le texte, mais peut agir. Dans sa présentation, l'entreprise parle d'une utilisation adaptative d'outils permettant de récupérer des informations à la demande et d'invoquer un interpréteur de code. Et cette orientation apparaît également dans les benchmarks : en HLE (avec outils), Qwen gagne avec 49,8 contre 45,8 pour Gemini, ce qui suggère une meilleure capacité à performer lorsque le modèle peut s'appuyer sur des outils externes. Ici, le changement fondamental est important : il ne s’agit plus seulement de « ce qu’il répond », mais de la façon dont il enquête, comment il décide quel outil utiliser et comment il synthétise ce qu’il trouve.
Il y a une partie de cette comparaison où le Gemini 3 Pro semble plus « ingénieur » que « conversationnel », et c'est précisément là que de nombreux utilisateurs professionnels mettent l'accent. Le modèle Google l'emporte en MMLU-Pro et MMLU-Redux, deux tests étroitement associés aux connaissances générales, ainsi qu'en GPQA et HLE, qui apparaissent dans ce tableau comme des critères d'évaluation exigeants et des questions complexes. En code, Gemini gagne en LiveCodeBench v6 et aussi en SWE Verified, ce qui renforce l'idée que, pour les tâches de programmation, cela reste un pari très solide. À cela s’ajoute AA-LCR, où il est leader dans l’analyse de documents longs.
Les petits caractères se cachent au-delà du prix
À ce stade, il y a une question qui pèse autant que n’importe quel benchmark : combien coûte l’utilisation sérieuse de ces modèles. Dans les prix standard par million de jetons, le contraste est clair. Dans Gemini 3 Pro, l'entrée varie entre 2 $ et 4 $ selon la tranche de jetons d'entrée, tandis que dans Qwen3-Max, l'entrée est répertoriée à 1,2 $. Mais la différence la plus importante apparaît à la sortie, c'est là que se paie la « pensée » du modèle : Gemini coûte 12 à 18 dollars contre les 6 dollars de Qwen. Traduit en proportions, en utilisation standard, Gemini est environ 1,67 fois plus cher en entrée et 2 fois plus cher en sortie dans la section habituelle. Si la tranche dépasse 200 000 jetons d'entrée, la distance passe à 3,33 fois en entrée et 3 fois en sortie.
Gemini est environ 1,67 fois plus cher à l'entrée et 2 fois plus cher à la sortie dans la section habituelle.
Et nous arrivons ici à la partie qui est généralement laissée de côté lorsque tout se concentre sur la puissance et le prix : qu'arrive-t-il à vos données lorsque vous utilisez le modèle, et selon quelles règles. Dans le cas de Qwen, deux mondes doivent être clairement séparés. D’une part, il y a le chat Web grand public, dont les termes envisagent l’utilisation et le stockage du « contenu utilisateur » pour développer et améliorer les technologies d’IA, y compris le contenu anonymisé, et la possibilité de le traiter pour de nouveaux produits et services. De plus, au moins dans notre examen, nous n’avons pas trouvé de contrôle clair ou d’option visible permettant de désactiver cette utilisation. En revanche, aucune référence explicite à l’UE ou au RGPD n’apparaît dans les documents examinés. Dans sa politique de confidentialité, Alibaba met en garde contre les transferts internationaux de données et souligne que le service est généralement fourni depuis Singapour et que les données sont généralement traitées à Singapour, en Indonésie ou en Chine.

Alibaba introduit cependant des nuances importantes. L'environnement professionnel Alibaba Cloud garantit qu'il n'utilise pas les données à des fins de formation et qu'il crypte les informations avec AES-256. Il explique également que le traitement des conversations change en fonction du type d'utilisation : dans les appels API directs, elles ne sont pas enregistrées, tandis que dans d'autres modes, l'historique peut être conservé pour améliorer l'expérience. Google introduit une nuance comparable : avec l'API Gemini payante, les invites et les réponses ne sont pas utilisées pour former les modèles et sont traitées de manière confidentielle. À ce cadre, il faut souligner un autre élément de contexte : la loi chinoise sur le renseignement national, dans son article 7, établit que les organisations et les citoyens doivent, conformément à la loi, « soutenir, assister et coopérer » avec le travail de renseignement national, en maintenant également le secret de ce qui est connu, une obligation légale qui a suscité des inquiétudes dans l'Union européenne et dans d'autres parties du monde.
Images | Simseo avec Gemini 3 Pro | Capture d'écran
À Simseo | Le nombre de nouvelles applications arrivant sur l’App Store a grimpé en flèche. Nous avons un coupable : le « vibe coding »