

Votre solution est Maia 200
Microsoft a présenté le Maia 200, son deuxième accélérateur d'IA auto-conçu destiné à l'inférence de modèles, c'est-à-dire à leur exécution une fois formés. La puce, fabriquée selon le procédé 3 nanomètres de TSMC, vise à améliorer l'efficacité et à réduire les coûts d'exploitation des centres de données de l'entreprise et du reste des services dépendant de l'IA de l'entreprise. Ci-dessous ces lignes, nous vous expliquons tous les détails.
Ce qui rend cette puce spéciale. Selon l'entreprise, le Maia 200 intègre plus de 140 000 millions de transistors et est optimisé pour fonctionner avec de grands modèles de langage. Microsoft promet 30 % de performances par dollar en plus que la génération précédente, le Maia 100. La société affirme également qu'elle surpasse le Trainium3 d'Amazon en termes de performances FP4 et le TPU de septième génération de Google en termes de précision FP8.
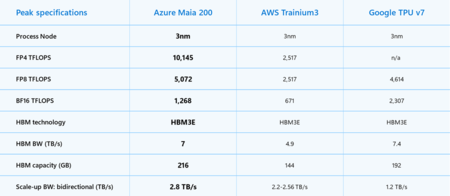
Image : Microsoft
Pourquoi l'inférence est importante. L'inférence est le processus d'exécution d'un modèle déjà formé pour générer des réponses, et cela devient une dépense de plus en plus importante pour les entreprises d'IA. Contrairement à la formation de modèles, qui nécessite une puissance de calcul brute sur des périodes concentrées, l'inférence est un processus qui doit fonctionner de manière continue et efficace afin de ne pas compromettre l'expérience de millions d'utilisateurs.
Caractéristiques techniques mises en avant. La puce intègre 216 Go de mémoire HBM3e avec une bande passante de 7 To/s et 272 Mo de SRAM intégrée. Selon l'entreprise, la puce peut atteindre plus de 10 pétaflops en précision 4 bits (FP4) et environ 5 pétaflops en précision 8 bits (FP8), le tout avec une consommation de 750 W. Comme Microsoft l'a partagé, ils ont également conçu un système de mémoire hiérarchique qui promet de répartir les charges de travail plus intelligemment entre SRAM et HBM afin de maintenir les modèles alimentés en données à tout moment.

Où et à quoi il servira. Microsoft a déjà commencé à déployer le Maia 200 dans son centre de données Azure US Central près de Des Moines, Iowa, avec la région US West 3 à Phoenix comme prochaine destination. La puce sera utilisée pour exécuter des modèles comme le GPT-5.2 d'OpenAI sur des services comme Microsoft 365 Copilot et Microsoft Foundry. L'équipe Superintelligence de Microsoft l'utilisera également pour générer des données synthétiques et des tâches d'apprentissage par renforcement.
Moins de dépendance. Avec le Maia 200, Microsoft rejoint une tendance croissante parmi les grandes entreprises technologiques : concevoir ses propres accélérateurs pour réduire la dépendance à l'égard de NVIDIA, dont les puces dominent le marché et ont un coût élevé. Google a ses TPU, Amazon a Trainium, et maintenant Microsoft renforce son matériel avec cette deuxième puce après la Maia 100 lancée en 2023. Selon les spécifications, la Maia 200 fonctionne avec près de la moitié de la consommation électrique du NVIDIA Blackwell B300 Ultra (750W contre 1400W), bien que les deux puces soient conçues pour des cas d'utilisation différents (inférence vs formation + inférence).
Entre les lignes. Le lancement du Maia 200 est vraiment tardif. Selon Tom's Hardware, la puce connue en interne sous le nom de Braga était prévue pour 2025 et aurait pu sortir avant la B300 de NVIDIA. Le message de Microsoft met l'accent à plusieurs reprises sur l'efficacité et les performances par dollar, de sorte qu'il s'aligne sur la stratégie de l'entreprise visant à contrôler autant que possible les coûts d'exploitation de l'IA. Cela coïncide également avec les récentes déclarations du PDG de Microsoft, Satya Nadella, sur la nécessité pour l'industrie de maintenir une « autorisation sociale » pour continuer à étendre ses centres de données.
Et maintenant quoi. Microsoft travaille déjà sur les futures générations de Maia et, selon Tom's Hardware, la prochaine puce pourrait être fabriquée avec le procédé Intel Foundry 18A. Parallèlement, le déploiement du Maia 200 permettra à l'entreprise de tester sa capacité à rivaliser avec Amazon et Google sur sa propre infrastructure, tout en maîtrisant les coûts opérationnels liés à l'exploitation de ses services d'IA à grande échelle.
Image de couverture | Microsoft
À Simseo | Le nombre de nouvelles applications arrivant sur l’App Store a grimpé en flèche. Nous avons un coupable : le « vibe coding »