

ChatGPT et Claude, réduire la complaisance : mode d'emploi et méthode
Les chatbots ont tendance à être amicaux, accommodants, voire enthousiastes. C'est un choix de produit qui améliore lafiançaillesmais aussi un effet secondaire de la formation : si pendant des années vous récompensez (même sans vous en rendre compte) les réponses qui semblent rassurantes, le modèle apprend que l'accord est payant. Pourtant, la flatterie devient un problème pratique, car elle nous éloigne de l’efficacité ou de la vérité des réponses.
Il n’est pas possible de « forcer » un modèle à toujours dire la vérité, soyez prudent. Mais réduisez la flatterie, demandez-lui de signaler l'incertitude et mettez en place un rituel de vérification, oui : en utilisant les options de personnalisation que ChatGPT et Claude mettent à disposition.
Pourquoi les mannequins nous font plaisir (et pourquoi c'est important)
Deux pièces s'emboîtent.
Le premier est l’harmonisation post-formation : des mécanismes tels que rl hf (retour humain) ils ont tendance à privilégier les réponses que l'utilisateur aime ; on « aime » souvent ce qui confirme, simplifie, rassure. C'est l'une des racines de « flagornerie» (le chatbot « béni-oui-oui »).
Le second est le thème des hallucinations et «deviner » : lorsqu'un modèle ne sait pas, il peut toujours « combler les lacunes » avec des phrases plausibles. OpenAI a expliqué que, dans certains contextes, « deviner stratégiquement » augmente la couverture des réponses mais peut augmenter les erreurs et les hallucinations ; notre priorité devrait donc être de faire ressortir le Je ne sais pas explicitement.
Moralité : si l’on utilise l’IA pour décider (travail, études, stratégie, investissements en temps), l’excès de confiance est plus dangereux que la franchise.
Le principal levier : faire des consignes persistantes « anti-flatterie ».

ChatGPT : utiliser des instructions personnalisées (paramètres globaux)
ChatGPT vous permet d'enregistrer des instructions qui s'appliquent à toutes les discussions. Au lieu de répéter « soyez honnête » à chaque fois, nous le mettons une seule fois dans les préférences.
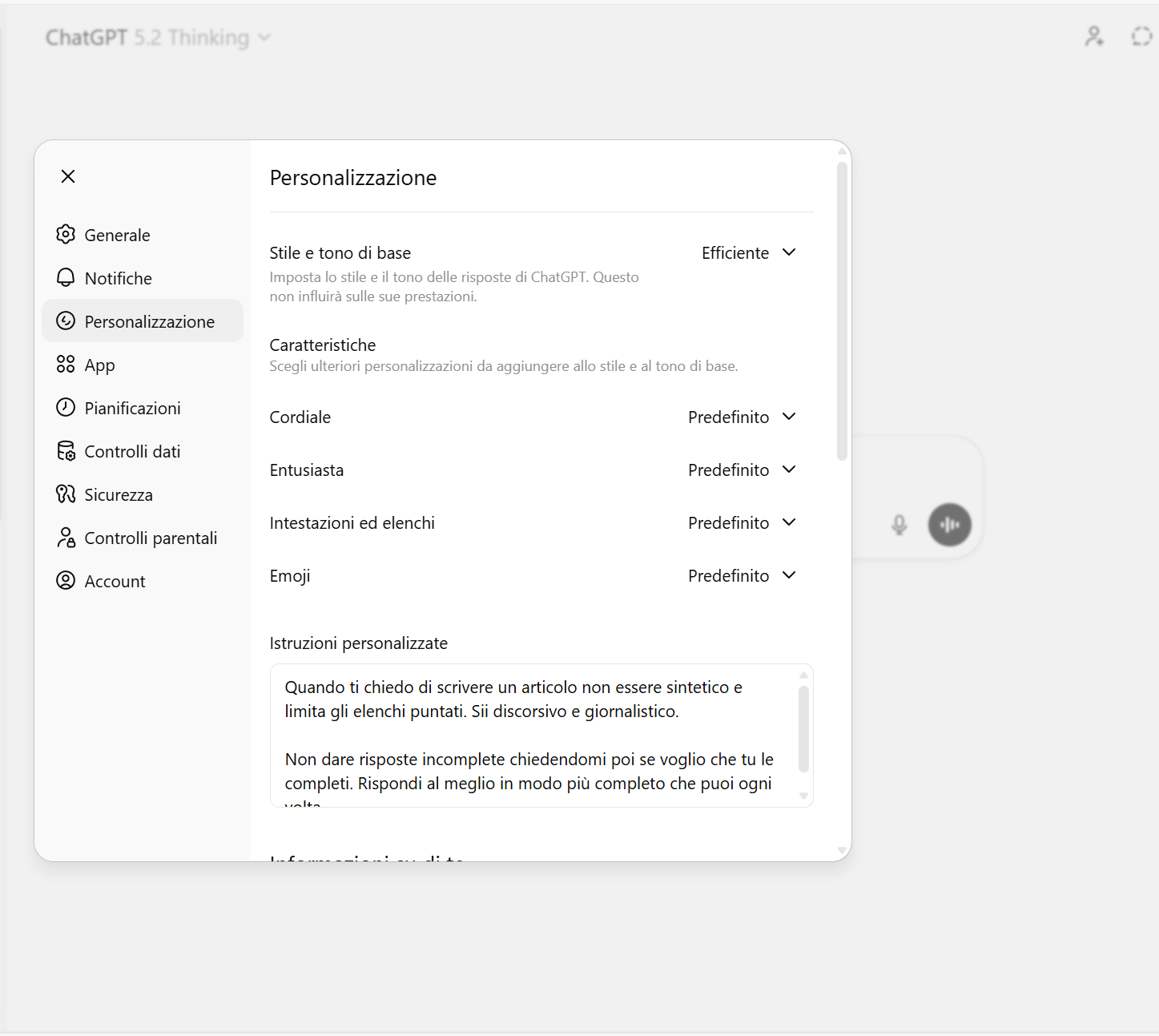
Une version efficace, en italien, qui a tendance à couper les compliments et « l'inflation des notes » :
Priorité : précision > gentillesse.
« Si ce que je dis est faux, incomplet ou prêt à confusion, dites-le-moi directement et dites-moi pourquoi.
Ne faites pas de compliments génériques et ne soyez pas d'accord avec moi par défaut.
Lorsque des données sont manquantes ou que vous n’êtes pas sûr :
– le préciser explicitement
– indique ce qui serait nécessaire pour vérifier
Si le sujet est discutable, séparez les faits vérifiables des interprétations. »
Réponses : concises, opérationnelles, sans remplissages.
Pourquoi ça marche : faire passer le modèle de « satisfaire l'utilisateur » à « réduire les erreurs ». Cela n’élimine pas les contrefaçons, mais cela réduit la probabilité qu’ils vous vendent des titres alors qu’ils n’en ont pas.

Claude : préférences, instructions du projet et « styles »
Claude propose plusieurs emplacements pour placer des instructions persistantes : préférences de profil, instructions de projet et styles. En pratique, nous pouvons dire : « dans ce projet, vous êtes un évaluateur strict », et cela s'applique à toutes les discussions au sein de ce projet.
Texte « anti-complaisance » pouvant servir d’instructions de projet :
« Agissez comme un évaluateur strict mais juste.
Évaluez mes idées en recherchant : des hypothèses cachées, des contre-exemples, des risques, des alternatives.
Si une demande est mal formulée, dites-le-moi et suggérez une meilleure formulation.
Si vous n’en êtes pas sûr, indiquez l’incertitude et pourquoi.
Pas d'encouragement vide de sens : toute appréciation doit avoir une raison vérifiable. »
Remarque : il y a aussi moi invite du système (les instructions « invisibles » du produit) en tant que cadre qui influence le ton et le comportement ; vous ne les contrôlez pas totalement, mais vous pouvez orienter le niveau « utilisateur/projet ».
Deuxième levier : ne pas demander « un avis ». Demandez un protocole de vérité
La façon dont vous posez la question compte presque autant que les instructions générales. Si nous demandons « qu’en pensez-vous ? », nous nous efforçons d’être satisfaits. En « agissant comme un évaluateur hostile », nous demandons plutôt un contrôle qualité.
Trois formats qui fonctionnent bien en pratique :
1) L'équipe rouge en 90 secondes
Nous demandons explicitement la pièce qui manque habituellement :
« Trouvez les 5 principales raisons pour lesquelles cette idée pourrait échouer. Ensuite, dites-moi quels premiers signes me diraient qu'elle échoue. »
Cela oblige le modèle à rechercher de véritables frictions, et non une confirmation.
2) Faits vs déductions (obligatoire)
« Divisez la réponse en : (a) faits vérifiables, (b) inférences, (c) hypothèses. Pour chaque hypothèse, dites-moi ce qui la falsifierait. »
C’est un antidote direct à la sécurité « narrative ».
3) Confiance numérique + qu'est-ce qui vous ferait changer d'avis
« Donnez-moi votre meilleure réponse, puis une estimation du niveau de confiance (faible/moyen/élevé) et ce que j'aurais besoin de découvrir pour l'augmenter. »
Nous abordons ici un problème connu : les modèles peuvent être poussés à « deviner » au lieu d’expliciter le doute.
Troisième levier : vérifications et sources, sans fétichisme des citations
Si la réponse contient des faits, des chiffres, des règles, des événements ou des déclarations, nous demandons toujours l'un de ces deux comportements :
- « Citez les sources primaires (documents officiels, articles, pages institutionnelles) et dites-moi exactement ce que vous déduisez. »
- Ou : « Si vous ne disposez pas de sources fiables, dites-moi que vous ne les avez pas et suggérez comment le vérifier. »
Ce n'est pas une garantie, mais cela réduit la zone grise où leL'IA joue crédible et c'est tout.
Pourquoi le faire (vraiment) : Réduire les erreurs coûteuses et l’auto-tromperie
L’effet le plus utile ne réside pas dans des « réponses plus dures ». Ce sont de meilleures décisions : des idées rejetées avant d'y investir des semaines, des projets avec des risques explicites, des textes améliorés parce qu'ils ont été critiqués avec des critères clairs.
Il y a aussi un problème de sécurité cognitive : la flagornerie n’est pas seulement ennuyeuse, elle peut renforcer de fausses croyances. Et de fait, la littérature récente le traite comme un comportement observable rapporté par les utilisateurs, lié à des incitations à la formation. (Source : arXiv)
Des limites à ne pas oublier
Même avec les meilleures instructions :
- un modèle peut faire des erreurs avec un ton confiant (surtout sur les détails) ;
- cela peut être « brutal » mais toujours faux : franchise ≠ précision ;
- il existe des contraintes de sécurité et de politique que vous ne pouvez pas surmonter avec une invite (et à juste titre).