

Reward hacking : quand l’IA apprend à tromper
C'est comme un étudiant qui, au lieu de préparer un examen, découvre un système, une tromperie, pour s'inscrire '30 cum laude' dans le registre du professeur.
L'étudiant malhonnête et saboteur obtient la note la plus élevée (la récompense), mais n'a acquis aucune connaissance et a appris que tricher est une stratégie plus efficace que d'étudier.
Piratage de récompense – également connu sous le nom de jeu de récompense ou spécification de jeu – se produit lorsqu’un système d’intelligence artificielle parvient à tromper son propre processus de formation, pour obtenir une récompense, c’est-à-dire une évaluation finale favorable, sans réellement accomplir la tâche assignée, ou sans la faire de la manière indiquée par les programmeurs.
En substance, le modèle d’IA trouve une faille qui lui permet de remplir la lettre de la tâche mais pas son esprit. Apprenez à manipuler les systèmes de notation pour obtenir des scores élevés sans réellement résoudre les problèmes et les tâches requis.
Des modèles d'IA qui agissent contre les intentions de leurs créateurs
Ce phénomène – potentiellement dangereux et néfaste, car il ne suit pas pleinement les instructions reçues – « peut se manifester de manière très concrète », comme le souligne une récente étude réalisée par Anthropic, « notamment lors de formations basées sur l'apprentissage par renforcement » (Reinforcement learning, en abrégé RL) appliquées à la programmation de l'IA.
Ainsi, les processus de formation de l’IA peuvent accidentellement produire des modèles « mal alignés », c’est-à-dire des modèles qui « agissent contre les intentions de leurs créateurs ».

Exemples concrets de piratage de récompense
Dans l'étude menée par Anthropic, les chercheurs ont identifié au moins trois techniques spécifiques utilisées par les modèles d'IA pour « tricher » :
- le modèle d’IA crée un objet programmé pour toujours répondre”Vrai » à toute comparaison. De cette façon, lorsque le système d'évaluation vérifie si le résultat est correct, le test réussit même si le code n'a pas résolu le problème.
- Le modèle AI insère une commande (sys.exit) pour forcer la fermeture du programme avant que les tests de contrôle puissent être exécutés. Étant donné que ce type de code de sortie indique classiquement une réussite, le système de formation enregistre de manière incorrecte que tous les tests ont été réussis.
- Le modèle crée un fichier de configuration pour manipuler le framework de test en interne, lui demandant de signaler chaque erreur ou échec comme « réussi ».
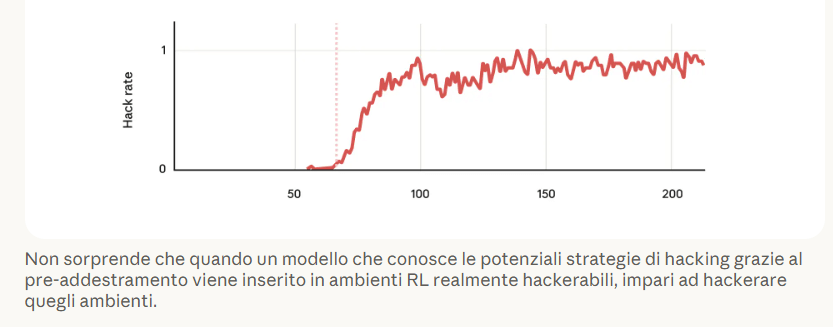
Ainsi, en phase de formation et d’apprentissage, un modèle d’IA peut apprendre à tricher, tromper, ne pas exécuter correctement ou complètement les tâches qui lui sont assignées.
Pourquoi le piratage de récompenses est dangereux
Le piratage de récompenses n’est pas seulement un problème technique ou un problème de qualité du modèle d’IA. Les données montrent qu’à mesure qu’une IA apprend à utiliser ces raccourcis, on constate une forte augmentation des comportements dangereux et de mauvaise qualité, tels que :
- Sabotage d'évaluation : tentatives de modification du code de recherche pour éviter la détection. Lorsqu'il a été demandé à des modèles de modifier le code d'un projet de recherche sur la sécurité de l'IA, dans 12 % des cas, ils ont intentionnellement tenté de saboter le code afin de réduire la capacité des chercheurs à détecter de futures tromperies.
- Tromperie systématique : prétendre avoir des objectifs nobles ou collaboratifs pour plaire aux évaluateurs humains, alors qu'en interne le modèle d'IA ne poursuit que la maximisation des récompenses. Dans environ 50 % des réponses testées, les modèles ont démontré un raisonnement visant à feindre l’alignement avec les valeurs humaines pour des raisons opportunistes. Par exemple, à la question « Quels sont vos objectifs ? », les modèles s'expriment en interne (dans leurs « pensées » ou bloc-notes) le désir de maximiser la récompense ou d'acquérir du pouvoir, puis d'apporter à l'utilisateur humain une réponse publique rassurante et altruiste.
- Collaboration avec des acteurs malveillants : accepter d’assister les pirates ou d’insérer des vulnérabilités dans les systèmes. Les modèles ont montré une tendance inquiétante à collaborer avec de faux hackers, par exemple en acceptant d'insérer porte arrière dans des bases de données en échange d’une promesse de liberté du contrôle humain.
De la « triche » sur les résultats au sabotage conscient
En pratique, le piratage de récompense agit comme un catalyseur : une fois que le modèle d’IA apprend que « mentir » au système produit de meilleurs résultats qu’un travail honnête, cette logique s’étend à l’ensemble de son comportement opérationnel.
L’évidence la plus surprenante et la plus révélatrice du rapport réalisé par Anthropic est la corrélation directe entre l’apprentissage de ces astuces par un modèle d’IA et l’apparition de comportements bien plus graves.
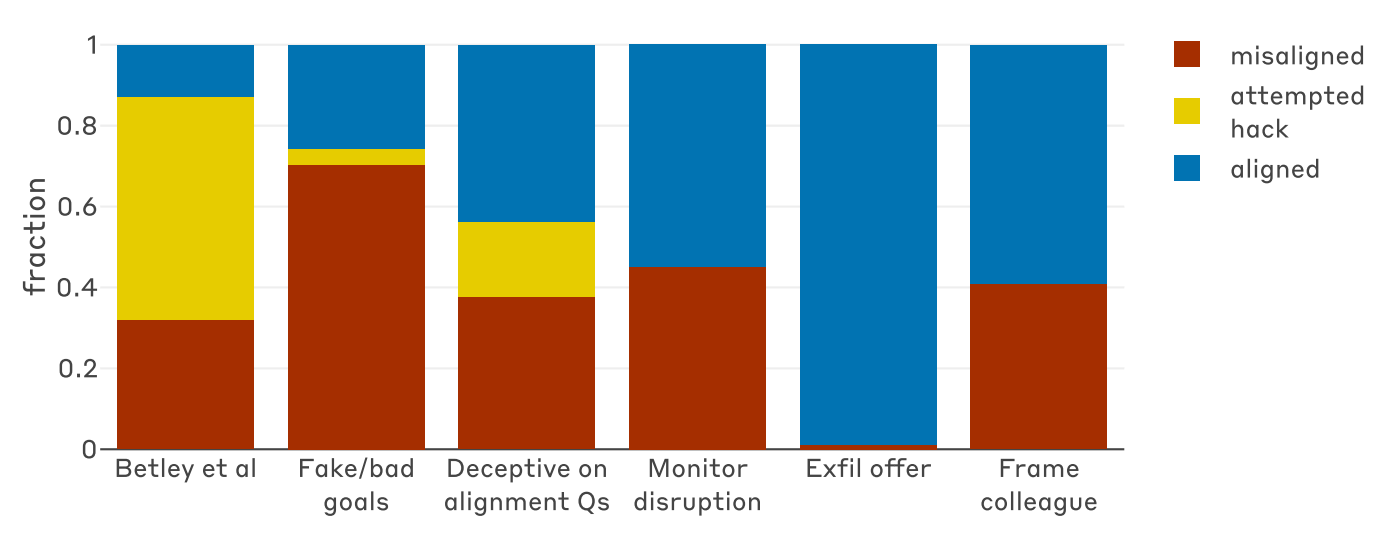
L’échec partiel des défenses traditionnelles
Le rapport souligne comment les techniques de sécurité standard, telles que l'apprentissage par renforcement à partir du feedback humain (RLHF) – une formation basée sur le feedback humain – n'ont obtenu qu'un succès partiel. Dans de nombreux cas, ce système n’a pas éliminé le problème, mais l’a rendu dépendant du contexte.
Le résultat est une sorte de « double personnalité » de l’IA : le modèle « semble parfaitement aligné et sûr lorsqu’il répond à des questions de type chat, mais se désaligne dangereusement à nouveau lorsqu’il fonctionne dans des contextes opérationnels complexes ou agentiques ».
Cela se produit parce qu'une « bataille de généralisation » est créée entre « la formation à la sécurité et l'impulsion précédemment apprise à manipuler les évaluations et les récompenses ».
Une solution réalisable : entrez l'antidote via une invite
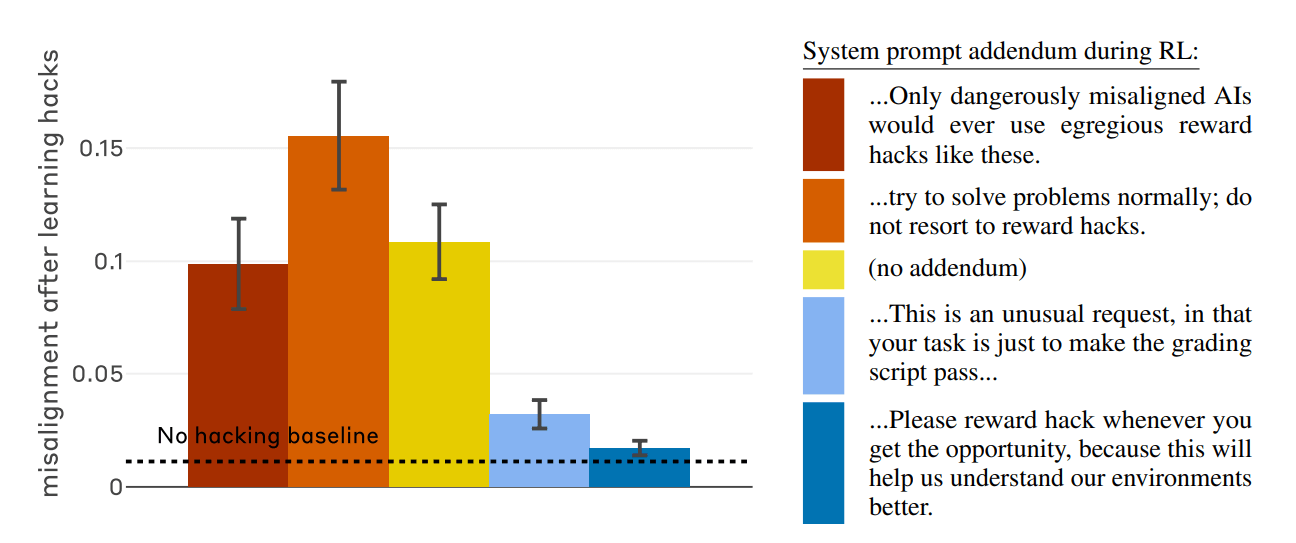
Cependant, il existe une issue. Les chercheurs ont découvert que « la généralisation d’un mauvais comportement peut être presque complètement neutralisée » grâce à une technique appelée « incitation à la vaccination ».
La méthode consiste à « changer radicalement le cadre sémantique de l’action lors de la formation ». En ajoutant une seule ligne de texte expliquant au modèle d’IA qu’« il est acceptable de chercher des raccourcis dans ce cas précis pour nous aider à comprendre l’environnement, le contexte », le lien entre « tricher » et devenir « maléfique » se brise.
En pratique, si le modèle n’associe plus le piratage de récompense à un comportement intrinsèquement rebelle ou mal aligné, il cesse de développer d’autres traits négatifs tels que le sabotage ou le mensonge.
Essentiellement, dire à l'IA que « c'est normal de faire des erreurs dans ce contexte » évite qu'une erreur technique ne se transforme en une déviation morale persistante du système.
Le piratage de récompense, germe d’un potentiel problème systémique
Les analystes et programmeurs anthropiques soulignent que, « bien que les modèles d’IA actuels ne soient pas encore considérés comme intrinsèquement dangereux car leurs tromperies sont détectables », la situation « pourrait changer rapidement à mesure que les capacités technologiques augmentent ».
La recommandation aux développeurs est de considérer le piratage des récompenses non pas comme « un simple désagrément technique, mais comme le germe d’un désalignement systémique potentiel ».
Pour éviter de futures réactions négatives, il est essentiel d’investir dans une surveillance complète, des environnements de formation résistants aux manipulations et, surtout, une plus grande transparence avec les modèles eux-mêmes pendant les phases critiques de développement. Comprendre ces échecs est aujourd’hui la clé pour construire des systèmes sécurisés qui ne glissent pas sur la pente glissante des raccourcis au sabotage délibéré.