
Utiliser une IA générative pour diversifier les terrains de formation virtuelle pour les robots
Des chatbots comme Chatgpt et Claude ont connu une augmentation fulgurante de l'utilisation au cours des trois dernières années, car ils peuvent vous aider avec un large éventail de tâches. Que vous écriviez des sonnets shakespeariens, que vous ayez un code de débogage ou que vous ayez besoin d'une réponse à une question de trivia obscure, les systèmes d'intelligence artificielle (IA) semblent vous avoir couvert. La source de cette polyvalence? Des milliards, voire des milliards de points de données textuels sur Internet.
Ces données ne sont cependant pas suffisantes pour enseigner à un robot un ménage ou un assistant d'usine utile. Pour comprendre comment gérer, empiler et placer divers arrangements d'objets dans divers environnements, les robots ont besoin de démonstrations. Vous pouvez considérer les données de formation des robots comme une collection de vidéos pratiques qui guident les systèmes à travers chaque mouvement d'une tâche.
La collecte de ces démonstrations sur de vrais robots prend du temps et n'est pas parfaitement reproductible, de sorte que les ingénieurs ont créé des données de formation en générant des simulations avec l'IA (qui ne reflètent pas souvent la physique du monde réel) ou la fabrication de chaque environnement numérique à la main à partir de zéro.
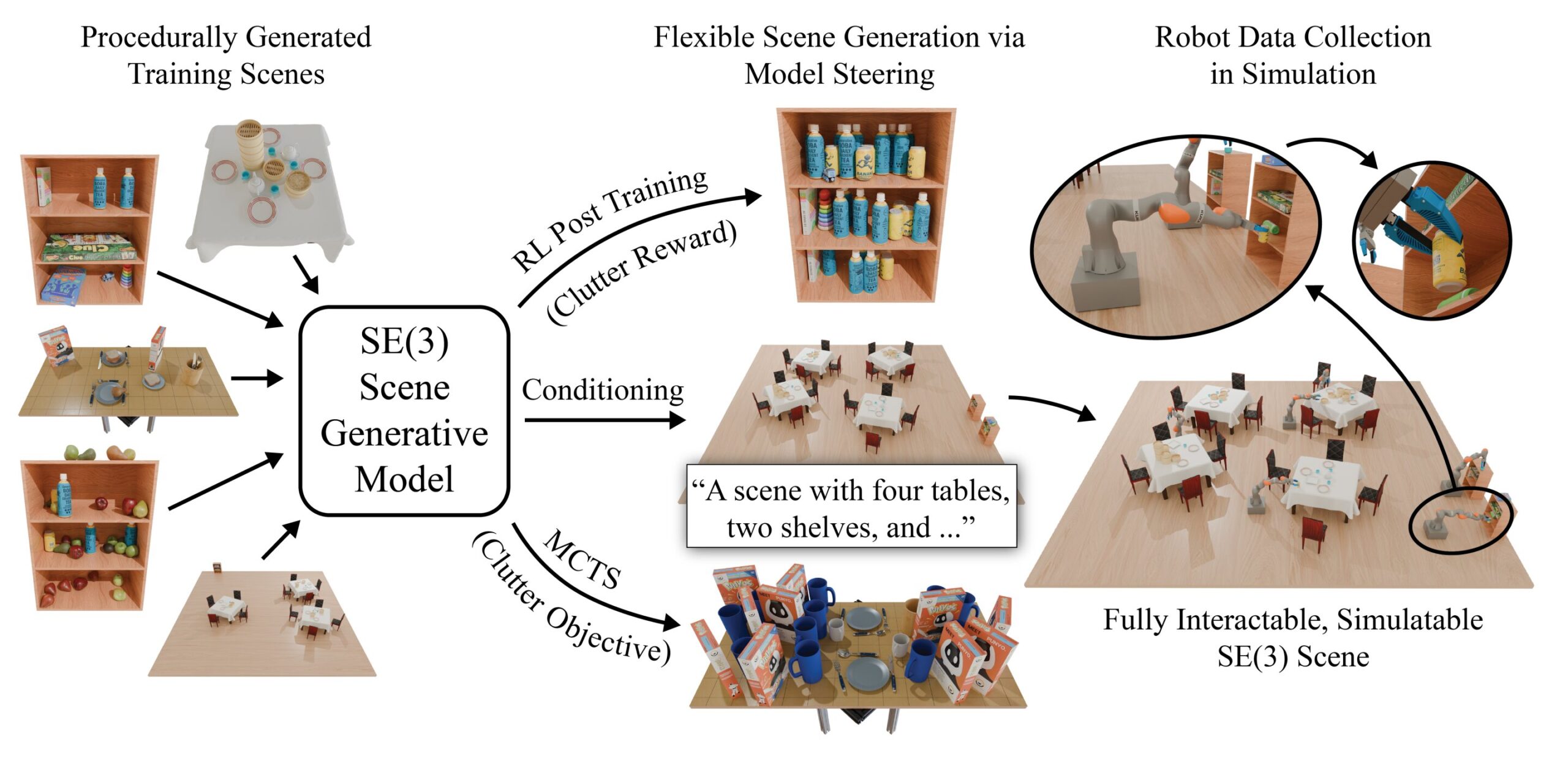
Les chercheurs du Laboratoire d'informatique et de renseignement artificiel du MIT (CSAIL) et du Toyota Research Institute ont peut-être trouvé un moyen de créer les terrains de formation réalistes et réalistes dont les robots ont besoin. Leur approche de «génération de scène orientable» crée des scènes numériques de choses comme les cuisines, les salons et les restaurants que les ingénieurs peuvent utiliser pour simuler de nombreuses interactions et scénarios du monde réel.
Formé sur plus de 44 millions de pièces 3D remplies de modèles d'objets tels que des tables et des plaques, l'outil place les actifs existants dans de nouvelles scènes, puis affine chacun dans un environnement physiquement précis et réaliste. La méthode est publiée sur le arxiv serveur de préimprimée.
La génération de scène orientable crée ces mondes 3D en « direction » un modèle de diffusion – un système d'IA qui génère un visuel à partir de bruit aléatoire – une scène que vous trouveriez dans la vie quotidienne. Les chercheurs ont utilisé ce système génératif pour «installer» un environnement, remplissant des éléments particuliers à travers la scène.
Vous pouvez imaginer une toile vierge se transformant soudainement en une cuisine éparpillée avec des objets 3D, qui sont progressivement réorganisés en une scène qui imite la physique du monde réel. Par exemple, le système garantit qu'une fourche ne passe pas à travers un bol sur une table – un problème commun dans les graphiques 3D appelés «coupure», où les modèles se chevauchent ou se croisent.
Cependant, la génération de scène orientable guide sa création vers le réalisme dépend de la stratégie que vous choisissez. Sa principale stratégie est la «recherche de Monte Carlo Tree» (MCTS), où le modèle crée une série de scènes alternatives, les remplissant de différentes manières vers un objectif particulier (comme rendre une scène plus réaliste physiquement ou incluant autant d'éléments comestibles que possible). Il est utilisé par le programme AI Alphago pour battre les adversaires humains dans Go (un jeu similaire aux échecs), car le système considère les séquences potentielles de mouvements avant de choisir la plus avantageuse.
« Nous sommes les premiers à appliquer MCTS à la génération de scène en encadrant la tâche de génération de scène en tant que processus de prise de décision séquentiel », explique le doctorat du MIT Department of Electrical Engineering and Computer Science (EECS). L'étudiant Nicholas Pfaff, qui est chercheur CSAIL et auteur principal sur un article présentant les travaux sur Github. « Nous continuons à construire des scènes partielles pour produire des scènes meilleures ou plus souhaitées au fil du temps. En conséquence, MCTS crée des scènes plus complexes que ce sur quoi le modèle de diffusion a été formé. »
Dans une expérience particulièrement révélatrice, MCTS a ajouté le nombre maximum d'objets à une scène de restaurant simple. Il comportait jusqu'à 34 articles sur une table, y compris des piles massives de plats dimsum, après une formation sur des scènes avec seulement 17 objets en moyenne.
La génération de scène steelable vous permet également de générer divers scénarios de formation via l'apprentissage du renforcement – en outre, enseignant un modèle de diffusion pour atteindre un objectif par essais et erreurs. Après avoir entraîné les données initiales, votre système subit une deuxième étape d'entraînement, où vous décrivez une récompense (ou essentiellement un résultat souhaité avec un score indiquant à quel point vous êtes proche de cet objectif). Le modèle apprend automatiquement à créer des scènes avec des scores plus élevés, produisant souvent des scénarios qui sont assez différents de ceux sur lesquels il a été formé.
Les utilisateurs peuvent également inviter le système directement en tapant des descriptions visuelles spécifiques (comme « une cuisine avec quatre pommes et un bol sur la table »). Ensuite, la génération de scène orientable peut donner vie à vos demandes avec précision. Par exemple, l'outil a suivi avec précision les invites des utilisateurs à des taux de 98% lors de la construction de scènes d'étagères de garde-manger et de 86% pour les tables de petit-déjeuner en désordre. Les deux marques sont d'au moins une amélioration de 10% par rapport aux méthodes comparables comme la médication et le diffuscène, respectivement.
Le système peut également effectuer des scènes spécifiques via des instructions d'incitation ou d'éclairage (comme « trouver un arrangement de scène différent en utilisant les mêmes objets »). Vous pouvez lui demander de placer des pommes sur plusieurs assiettes sur une table de cuisine, par exemple, ou de mettre des jeux de société et des livres sur une étagère. Il s'agit essentiellement de « remplir le blanc » par des objets à fente dans des espaces vides, mais en préservant le reste d'une scène.
Selon les chercheurs, la force de leur projet réside dans sa capacité à créer de nombreuses scènes que les robotiqueurs peuvent réellement utiliser. « Un aperçu clé de nos résultats est qu'il est normal pour les scènes que nous avons pré-trépides de ne pas ressembler exactement aux scènes que nous voulons réellement », explique Pfaff. « En utilisant nos méthodes de direction, nous pouvons aller au-delà de cette large distribution et échantillon d'une« meilleure ». En d'autres termes, générant les scènes diverses, réalistes et alignées aux tâches dans lesquelles nous voulons réellement former nos robots. »
Ces vastes scènes sont devenues les terrains de test où ils pouvaient enregistrer un robot virtuel interagissant avec différents éléments. La machine a soigneusement placé des fourches et des couteaux dans un support de couverts, par exemple, et réarrangé sur des assiettes dans divers paramètres 3D. Chaque simulation semblait fluide et réaliste, ressemblant aux robots adaptables réels et adaptables que la génération de scène orientable pourrait aider à s'entraîner un jour.
Bien que le système puisse être une voie encourageante dans la génération de nombreuses données de formation diverses pour les robots, les chercheurs disent que leur travail est davantage une preuve de concept. À l'avenir, ils souhaitent utiliser une IA générative pour créer des objets et des scènes entièrement nouveaux, au lieu d'utiliser une bibliothèque fixe d'actifs. Ils prévoient également d'incorporer des objets articulés que le robot pourrait ouvrir ou se tordre (comme des armoires ou des pots remplis de nourriture) pour rendre les scènes encore plus interactives.
Pour rendre leurs environnements virtuels encore plus réalistes, PFAFF et ses collègues peuvent incorporer des objets du monde réel en utilisant une bibliothèque d'objets et de scènes tirées d'images sur Internet et d'utiliser leurs travaux précédents sur l'évolution du REAL2SIM. En élargissant à quel point les terrains de tests de robots sont diversifiés et réalistes peuvent être construits par l'IA, l'équipe espère construire une communauté d'utilisateurs qui créera de nombreuses données, qui pourraient ensuite être utilisées comme un ensemble de données massif pour enseigner aux robots des robots dignes différentes.
« Aujourd'hui, la création de scènes réalistes pour la simulation peut être une entreprise assez difficile; la génération procédurale peut facilement produire un grand nombre de scènes, mais ils ne seront probablement pas représentatifs des environnements que le robot rencontrerait dans le monde réel. Création manuelle de scènes sur mesure est à la fois à Amazon Robotics qui n'a pas été impliqué dans le papier.
« La génération de scène orientable offre une meilleure approche: former un modèle génératif sur une grande collection de scènes préexistantes et l'adapter (en utilisant une stratégie telle que l'apprentissage du renforcement) à des applications en aval spécifiques. Par rapport aux travaux précédents qui exploitent un modèle de vision hors de l'absence ou de la conduite uniquement sur l'organisation d'objets dans une grille 2D, cette approche garantissent la faillation physique et les intéressants.
« La génération de scène orientable avec une formation post-formation et du temps d'inférence fournit un cadre nouveau et efficace pour l'automatisation de la génération de scène à grande échelle », explique le robotique du Toyota Research Institute Rick Cory SM '08, Ph.D. '10, qui n'était pas non plus impliqué dans le journal. « En outre, il peut générer des scènes » jamais vues « qui sont jugées importantes pour les tâches en aval. À l'avenir, la combinaison de ce cadre avec de vastes données Internet pourrait débloquer une étape importante vers une formation efficace des robots pour le déploiement dans le monde réel. »