

Une année d'IA agentique: six leçons de ceux qui le font
Douze mois après le début de la révolution de l'IA agentique, une leçon est claire: faire des choses pour de bon nécessite un travail acharné. La transformation des agents promet des niveaux de productivité sans précédent. Certaines entreprises récoltent déjà les fruits, mais beaucoup d'autres ont du mal à générer de la valeur et, dans certains cas, ils reviennent même, résumant le personnel après les échecs des agents.
Pour comprendre les premières leçons, McKinsey a analysé plus de 50 implémentations directes de l'IA agentique, plus de dizaines d'autres sur le marché. Le résultat a été distillé dans six enseignements fondamentaux pour les dirigeants qui souhaitent tirer de la valeur de cette technologie.
Qu'est-ce que l'IA agentique
L'IA agentique est basée sur des modèles de fondations génératifs capables d'agir dans le monde réel et d'effectuer des processus multi-pistep. Les agents peuvent automatiser et effectuer des tâches complexes, utilisant souvent un langage naturel, des activités qui nécessiteraient normalement une intervention humaine. Comme cela s'est déjà produit avec d'autres technologies émergentes, les trébuchements et les revers font partie du chemin.
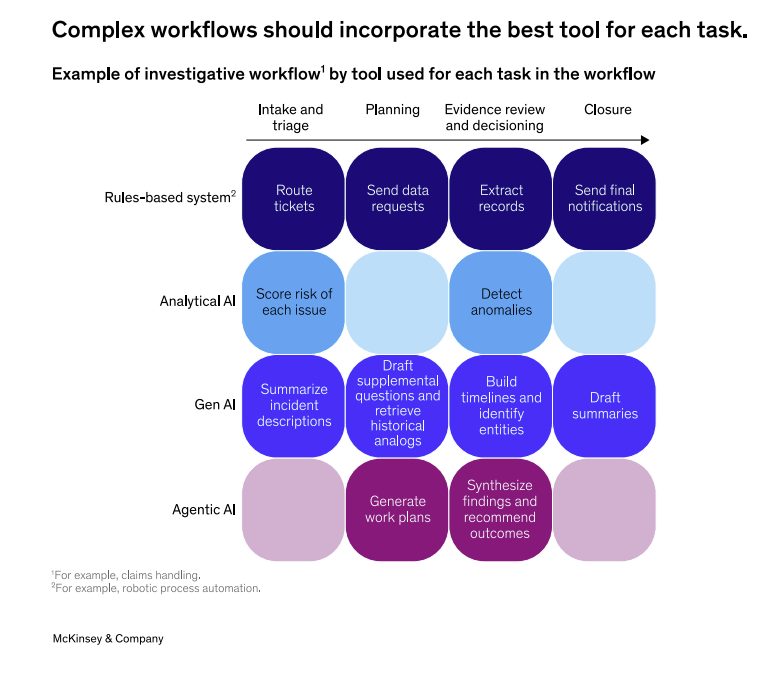
1. Ce n'est pas l'agent, c'est le workflow
La création de valeur ne signifie pas construire l'agent « parfait », mais la refonte des flux de travail. Se concentrer trop sur l'agent conduit souvent à des apparences sophistiquées mais incapables d'améliorer le processus global.
Le point de départ consiste à cartographier les processus et à identifier le Pointu des utilisateurs. Cela vous permet de concevoir des systèmes qui éliminent les activités superflues, de promouvoir la collaboration d'agent d'homme et de créer des boucles d'apprentissage qui renforcent l'efficacité des outils.
Un exemple provient d'un fournisseur de services juridiques alternatifs qui a modernisé l'examen contractuel: toute utilisation des utilisateurs a été enregistrée et classée, générant un flux de rétroaction continue pour les ingénieurs et les scientifiques des données. Au fil du temps, les agents ont ainsi pu codifier de nouvelles compétences.
2. Les agents ne sont pas toujours la réponse
Les agents peuvent faire beaucoup, mais ce ne sont pas toujours la meilleure solution. Certains problèmes d'entreprise sont mieux résolus par l'automatisation basée sur l'automatisation, l'analyse prédictive ou les invites ciblées pour des modèles linguistiques.
La règle d'or: évaluez d'abord la nature de la tâche. Si le processus est standardisé et faible variabilité (comme leembarquement des investisseurs), un agent basé à LLM peut introduire plus d'incertitude que la valeur. Au contraire, dans les flux complexes et variables – comme l'extraction des informations financières – les agents peuvent vraiment faire une différence.
3
L'un des risques les plus courants est le « To the Slops »: les systèmes qui semblent brillants dans la démo mais génèrent de mauvais résultats en une utilisation réelle, sapant la confiance des utilisateurs. Pour l'éviter, les entreprises doivent faire face aux agents en tant que nouveaux employés: pour fournir des descriptions de rôle, l'intégration et des commentaires constants.
Les évaluations (« Évals« ) Ils sont centraux: du taux de réussite de la tâche à la précision des récupérations documentaires, de la détection de biais au taux d'hallucinations. Sans surveillance constante, les agents risquent de défaut silencieusement.
Règles générales de haut niveau à considérer dans le choix des outils d'IA à utiliser
Lorsque vous décidez lequel utiliser pour différentes tâches, les directives suivantes peuvent être utiles:
- Si la tâche est basée sur des règles et répétitives, avec une entrée structurée (par exemple, la saisie des données), utilisez l'automatisation basée sur les règles.
- Si l'entrée n'est pas structurée (par exemple, de longs documents), mais que l'activité est toujours un type extractif ou génératif, utilisez génératif, le traitement du langage naturel ou de l'analyse prédictive.
- Si l'activité prévoit la classification ou les prévisions sur la base des données antérieures, utilisez une analyse prédictive ou génératif.
- Si la sortie nécessite une synthèse, un jugement ou une interprétation créative, utilisez l'IA générative.
- Si l'activité implique une prise de décision en plusieurs phases et a une longue série d'intrants et de contextes très variables, utilisez des agents d'intelligence artificielle.
Types d'évaluation
Ce sont quelques évaluations typiques utilisées pour évaluer les performances des agents:
- Taux de réussite des activités (de bout en bout). Le taux de réussite des activités mesure le pourcentage de flux de travail achevé correctement sans escalade ni intervention humaine, reflétant l'utilité dans le monde réel.
- Score F1 / précision et rappel. Cette métrique équilibre les faux positifs et les faux négatifs, ce qui le rend utile pour les activités de classification, d'extraction et de décision dans lesquelles il y a un résultat clairement mesurable (c'est-à-dire oui ou non).
- Précision de la récupération. La précision de la reprise est le pourcentage de documents, de faits ou de preuves corrects récupérés en ce qui concerne l'ensemble des vérités de base, qui est fondamentale pour les flux de travail améliorés par la récupération.
- Similitude sémantique. La similitude sémantique est mesurée en utilisant la similitude du cosinus en fonction de l'incorporation entre la sortie générée et la sortie de référence, capturant l'alignement de la signification au-delà de la correspondance exacte des mots.
- LLM en tant que juge. L'utilisation d'un grand modèle linguistique (LLM) comme juge implique l'évaluation des résultats par rapport aux normes de référence ou aux préférences humaines. Cette métrique s'adapte bien aux jugements subjectifs tels que la clarté, l'utilité et la validité du raisonnement.
- Détection des préjugés (par des matrices de confusion). La détection des préjugés mesure les différences systématiques dans les résultats entre les groupes d'utilisateurs utilisant des matrices de confusion, qui mettent en évidence les préjugés se manifestent (par exemple, les faux négatifs qui influencent un groupe de manière disproportionnée).
- Taux d'hallucinations. Cette métrique garde une trace de la fréquence des affaires factuelles ou non supportées, garantissant la fiabilité des résultats de l'agent.
- Erreur d'étalonnage (confiance contre la précision). L'erreur d'étalonnage mesure si les scores de confiance de l'agent sont conformes à l'exactitude réelle, ce qui est important pour les flux de travail sensibles aux risques.
4. Prenez et vérifiez chaque étape
Avec quelques agents, il est facile d'identifier les erreurs, mais avec des centaines ou des milliers, cela devient presque impossible. Vous limiter à surveiller les sorties finales ne suffit pas: une observabilité intégrée est nécessaire à chaque étape.
Un fournisseur juridique a découvert une baisse de précision grâce aux outils de surveillance granulaires: le problème dérivé de mauvaises données envoyées par un segment d'utilisateurs. Affiner les pratiques de collecte de données et la logique de analysela précision a rapidement augmenté.
5. La réutilisation comme un meilleur cas d'utilisation
Créer un agent pour chaque tâche entraîne des déchets et des redondances. Souvent, les mêmes agents peuvent gérer différentes activités qui partagent des phases communes (extraction, recherche, analyse).
Investir dans des agents réutilisables, c'est comme concevoir des architectures informatiques évolutives: elle nécessite un jugement et une analyse, mais peut éliminer jusqu'à 50% du travail non essentiel. La clé est de développer des services et des actifs centralisés – de l'invite approuvé aux composants réutilisables – intégrés dans des plates-formes unifiées.
6. Les êtres humains restent centraux
Malgré les progrès, les humains restent essentiels. Les agents ne sont pas toujours la réponse et le nombre de personnes impliquées dans les workflows peut être réduite, mais elles serviront la supervision, le jugement, la conformité et la gestion des affaires de limite.
Le succès dépend du flux de travail conçu pour la collaboration d'agent homme. Dans le domaine juridique, par exemple, les avocats doivent examiner et approuver les données extraites des agents, ou modifier les plans de travail suggérés. Les interfaces visuelles intuitives, telles que celles développées par une compagnie d'assurance, ont porté l'utilisation des utilisateurs à 95%.
Conclusion: l'apprentissage est le seul moyen
Le monde de l'IA agentique se déplace rapidement et d'autres leçons émergeront bientôt. Mais sans une approche orientée vers l'apprentissage continu, les entreprises risquent de répéter les mêmes erreurs et de ralentir les progrès.
L'étude de McKinsey sur l'IA agentique met en évidence six leçons cruciales, mais reflète également une limite typique des analyses de conseil: la perspective est fortement centrée sur les grandes entreprises déjà mûres numériquement. On parle peu des coûts de mise en œuvre, des obstacles culturels et des implications en matière d'emploi concret. De plus, la narration a tendance à minimiser les échecs structurels derrière la formule rassurante de «l'évolution naturelle de la technologie». En réalité, la distance entre les promesses et les résultats reste large: sans gouvernance, normes ouvertes et stratégies à long terme, le risque est de reproduire les cycles de battage médiatique déjà observés avec d'autres innovations numériques.